Headings h1-h6 for SEO and Accessibility: Multiple H1 Tags, HTML5 and More
More than a decade ago, heading optimization had a significant impact on ranking. While their influence has diminished, they remain useful for search engines. Additionally, headings not only indirectly affect SEO by improving content understanding and user engagement, but also influence how your content appears in search results and help new agents and assistants with navigational capabilities.
In this article, I will address this topic through official documentation and web accessibility standards.
The importance of headings h1-h6 for Search Engines
Headings help clarify the structure and topics of page content. They provide clear signals to search engines about the themes of each section. The specific heading level isn’t as important as ensuring that each heading clearly indicates its topic.
So headings on a page help us to better understand the content on the page. Headings on the page are not the only ranking factor that we have. We look at the content on its own as well. But sometimes having a clear heading on a page gives us a little bit more information on what that section is about.
And when it comes to text on a page, a heading is a really strong signal telling us this part of the page is about this topic.
…whether you put that into an H1 tag or an H2 tag or H5 or whatever, that doesn’t matter so much.
But rather kind of this general signal that you give us that says… this part of the page is about this topic. And this other part of the page is maybe about a different topic.
Google recommends using clear, meaningful headings to emphasize key topics and establish a hierarchical structure, making it easier for users to navigate.
Use meaningful headings to indicate important topics, and help create a hierarchical structure for your content, making it easier for users to navigate through your document.
Use heading tags where it makes sense. Too many heading tags on a page can make it hard for users to scan the content and determine where one topic ends and another begins.
Avoid:
Placing text in heading tags that wouldn’t be helpful in defining the structure of the page.
Using heading tags where other tags like <em> and <strong> may be more appropriate.
Erratically moving from one heading tag size to another.
Excessive use of heading tags on a page.
Very long headings.
Using heading tags only for styling text and not presenting structure.
The text is easy-to-read and well organized: Write content naturally and make sure the content is well written, easy to follow, and free of spelling and grammatical mistakes. Break up long content into paragraphs and sections, and provide headings to help users navigate your pages.
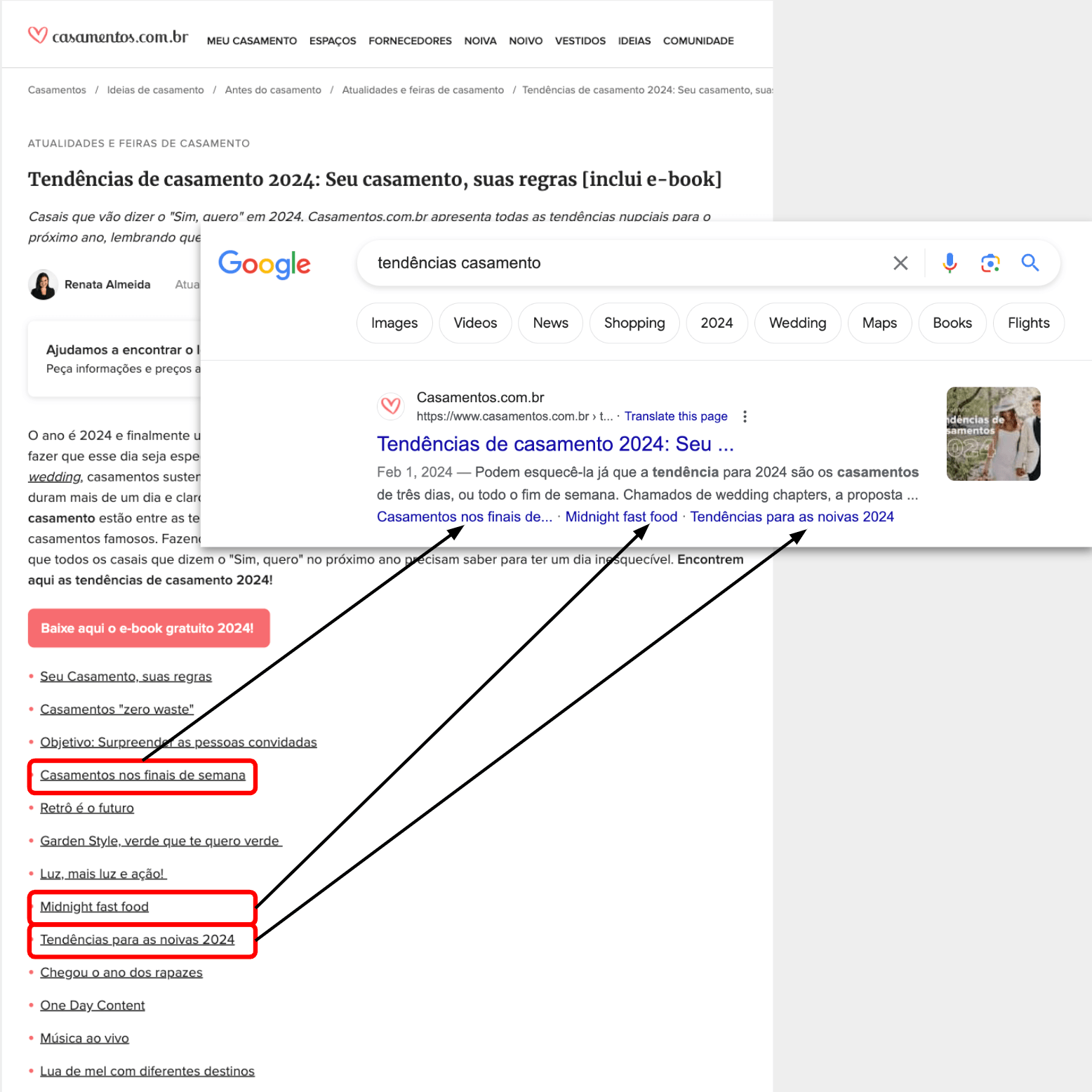
Google also uses headings for SERP elements. For instance, it utilizes named anchors for «Fraggles» and headings to summarize articles in featured snippets
Named anchors as «fraggles»
Headings in featured snippets
Semantic HTML tips to enhance both accessibility and SEO
Headings are semantic elements in HTML that provide meaning to the content they enclose. By using headings accordingly, you help browsers, screen readers, and search engines understand the structure and importance of the content on a webpage.
It does help us [semantic HTML], but it’s not the only thing that we look for.
It’s important to really tag the content to help search engines to understand your content [in response to a semantic HTML question]. Mean H1 tag, H2 tag, H3 tag in a user-friendly form to tell the story about headings, about this is the head of a section. I think tables that are well-structured is also helps Search Engine to really understand the notion of table, the notion of list.
According to the following Google patent, terms appearing in headings or titles are considered semantically close to the terms that are below them in the document’s tree structure:
Headings and titles can be detected in the document’s tree structure as text associated with nodes that are above other nodes in the tree.
Text below a heading/title node in the tree structure can be considered to belong to that heading/title.
A term in the title of a document can be considered close to all other terms in the document, regardless of the number of words separating them.
Similarly, a term appearing in a heading can be considered very close to other terms that are below the heading in the tree structure.
Imagine you have a document with a main title and several subtitles or headings. For example:
TITLE AND SUBTITLES
<h1>Main Title: How to Grow Tomatoes</h1>
<h2>Subtitle 1: Preparing the Soil</h2>
<h2>Subtitle 2: Planting the Seeds</h2>
<h2>Subtitle 3: Watering Care</h2>
According to this patent, although the words of the Main Title are visually far apart from the words under Subtitles 2 and 3, they would be considered semantically close.
For instance, the word «tomatoes» from the Main Title would be treated as semantically close to words like «watering» that appear under Subtitle 3, despite the physical distance between them.
The same would apply for the subtitles. Words under a subtitle would be treated as semantically close to the words of that subtitle, regardless of how many words visually separate them.
Another example: In a list, all elements are at the same semantic distance from the header. So there’s no need to stuff the list with keywords, as in the following example 2.
<h2>Destinations</h2>
<ul>
<li>Hotels in destination 1</li>
<li>Hotels in destination 2</li>
<li>Hotels in destination 3</li>
</ul>
So basically, headings act as «semantic connectors» that bind the words below and above them, even when those words are visually far apart in the document.
2. Heading hierarchy is useful
Header hierarchy in semantic order is useful to Search Engines and accessibility:
Header hierarchy is not just useful to Google, it’s also important for accessibility.
(Google still has to deal with whatever weird things people throw up on the web, but being thoughful in your work always makes sense.)
Having your headings in semantic order is fantastic for screen readers, but from Google Search perspective, it doesn’t matter if you’re using them out of order. The web in general is not valid HTML, so Google Search can rarely depend on semantic meanings hidden in the HTML specification.
There’s also no magical, ideal amount of headings a given page should have. However, if you think it’s too much, then it probably is.
However, the size of headers must follow a hierarchical structure. No subheaders should be larger than the previous level, and no paragraph text should be larger than the headers. Google has also stated several times that the size of the text can influence how a page’s structure is interpreted, regardless of the headings. You can try, but you won’t be able to fool Google.
Aside from PageRank and the use of anchor text, Google has several other features. First, it has location information for all hits and so it makes extensive use of proximity in search. Second, Google keeps track of some visual presentation details such as font size of words. Words in a larger or bolder font are weighted higher than other words. Third, full raw HTML of pages is available in a repository.
Google – The Anatomy of a Large-Scale Hypertextual Web Search Engine – 1998
I can’t imagine that it would matter for SEO. Test it with your users instead.
Google’s John Mueller – Size Of Your H1 & Header Fonts Doesn’t Matter For SEO – 2022
When assessing headings, it’s important to consider both the document outline and the visual hierarchy of the elements. The document outline ensures that headings follow the correct order to reflect the structure of the content, while the visual hierarchy ensures that headings are visually distinguished according to their importance and that no text is larger than them.
3. Multiple H1 for SEO and accessibility is technically valid, but not semantically correct
The use of multiple <h1> tags is technically allowed in HTML5 and can be properly handled by search engines. However, for semantic correctness and accessibility, it’s best to use them in a structured way that maintains the logical hierarchy of the page’s content.
Our systems don’t have a problem when it comes to multiple H1 headings on a page. That’s a fairly common pattern on the web.
Let’s now look at 3 different ways to implement them:
1 – ALLOWED
2 – ALLOWED
3 – ALLOWED
<body>
<h1>Hello</h1>
<article>
<h1>Whats is it?</h1>
<p>I don´t know!</p>
</article>
<article>
<h1>Do you know me?</h1>
<p>Maybe</p>
</article>
</body>
<body>
<h1>Hello</h1>
<article>
<h1>Whats is it?</h1>
<p>I don´t know!</p>
</article>
<section>
<h1>This is true love</h1>
<p>Nope</p>
</section>
</body>
<body>
<h1>Hello</h1>
<h1>Whats is it?</h1>
<p>I don´t know!</p>
<h1>Do you know me?</h1>
<p>Maybe</p>
</body>
Allowed does not mean «semantically correct» because no browser implements HTML5 outlining. HTML5 introduced an outline algorithm meant to generate the document structure based on headings and sectioning elements. However, many browsers and tools do not implement this algorithm, which can alter the resulting structure for screen readers. More on:
Visually, some browsers compose it well, but not internally as we can see in the computed properties:
First example
Example 1: <H1> elements within <article> tags are smaller in size but still represent Level 1 headings.
Second example
Example 2: <H1> elements within <section> tags are smaller in size but still represent Level 1 headings.
Third example
Example 3: All <H1> with the same size and marked Level 1.
From an SEO perspective, options 1 and 2 are both acceptable, and I haven’t seen any improvement by replacing H1 headings within HTML5 tags with H2.
4. Do not skip heading levels
Skipping heading levels creates navigation barriers for screen reader users. For instance, if a level 3 heading is skipped between a level 2 and a level 4, users are informed that no level 3 headings exist and often assume there are no levels 4, 5, or 6, making those headings hard to find.
The six heading elements, H1 through H6, denote section headings. Although the order and occurrence of headings is not constrained by the HTML DTD, documents should not skip levels (for example, from H1 to H3), as converting such documents to other representations is often problematic.
5. Headings must not be used to markup subheadings, subtitles, and taglines
In HTM5, H1-H6 elements must not be used to markup subheadings, subtitles, alternative titles and taglines unless intended to be the heading for a new section or subsection. The following is an example of a poor implementation of this rule:
This <H2> is not permitted; it should be replaced with a <p> or <div> instead
Recommendations
Use the following recommendations to help create a clear, user-friendly, and search-engine-friendly document structure:
Use headings to clarify and structure content for readers and search engines, rather than stuffing them with keywords.
Do not skip heading levels. Ensure that the hierarchy of <h1> to <h6> elements is followed, providing a clear structure to the page content.
Visually, ensure that no paragraph text is larger than its respective heading. Maintain consistency in the sizes of headings, with lower-numbered headings (like <h2>) being larger than higher-numbered ones (like <h3>), to keep the visual hierarchy clear.
Using multiple <H1> tags is permitted, but if you choose to use them, it’s best to place them within an <article> rather than a <section>. However, the ideal approach is to use a single <H1> as the main title of the document to establish a clear hierarchy and focus for the content.
The tag <article> often offers better semantic meaning and accessibility support than <section>. It provides a more meaningful way to structure self-contained content.
In this article, we delve into the inner workings of Google, a tool we all use daily but few truly understand. Following the recent leak of documents in an antitrust lawsuit against Google, we have a unique opportunity to explore Google’s algorithms. Some of these algorithms were already known, but what’s interesting is the internal […]
Making accurate decisions in the volatile world of SEO can be challenging, especially when facing complex and unfamiliar situations. In this scenario, the Cynefin framework can guide us in managing SEO projects in an increasingly VUCA (Volatile, Uncertain, Complex, and Ambiguous) or BANI (Brittle, Anxious, Non-linear, and Incomprehensible) environment. At the end of this article, […]
 Named anchors as «fraggles»
Named anchors as «fraggles»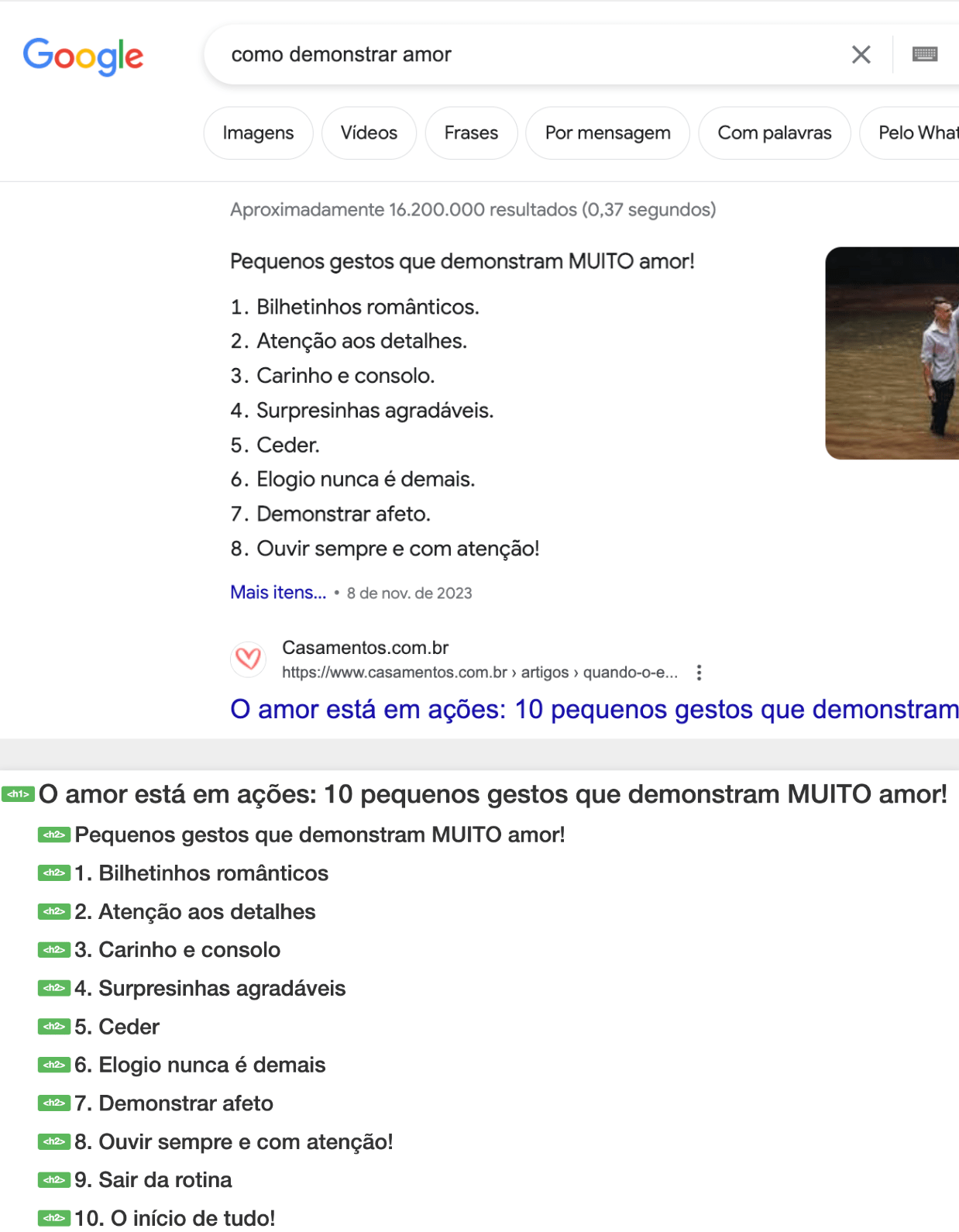 Headings in featured snippets
Headings in featured snippets Heading-level outline vs Structural outline
Heading-level outline vs Structural outline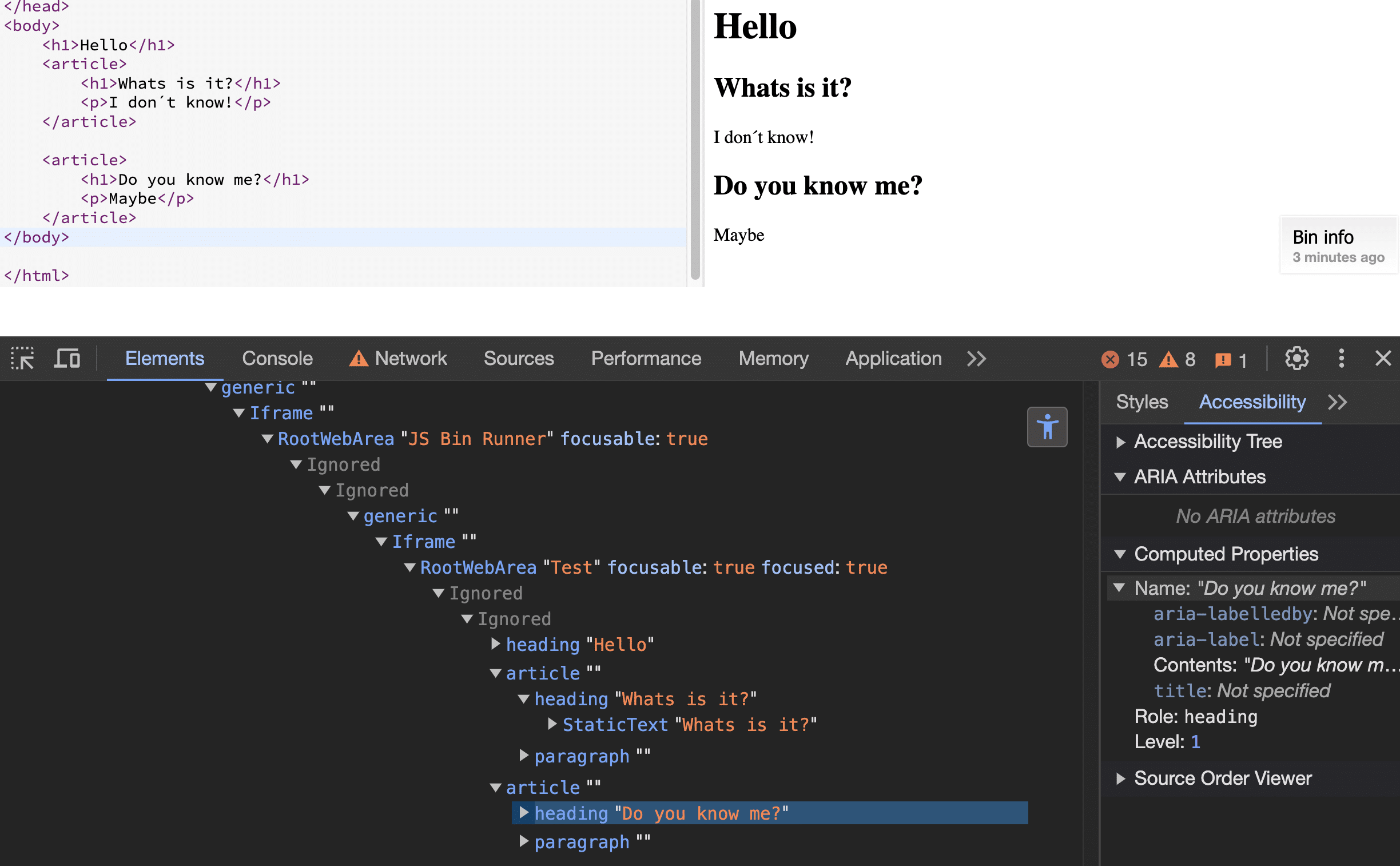 Example 1:
Example 1: 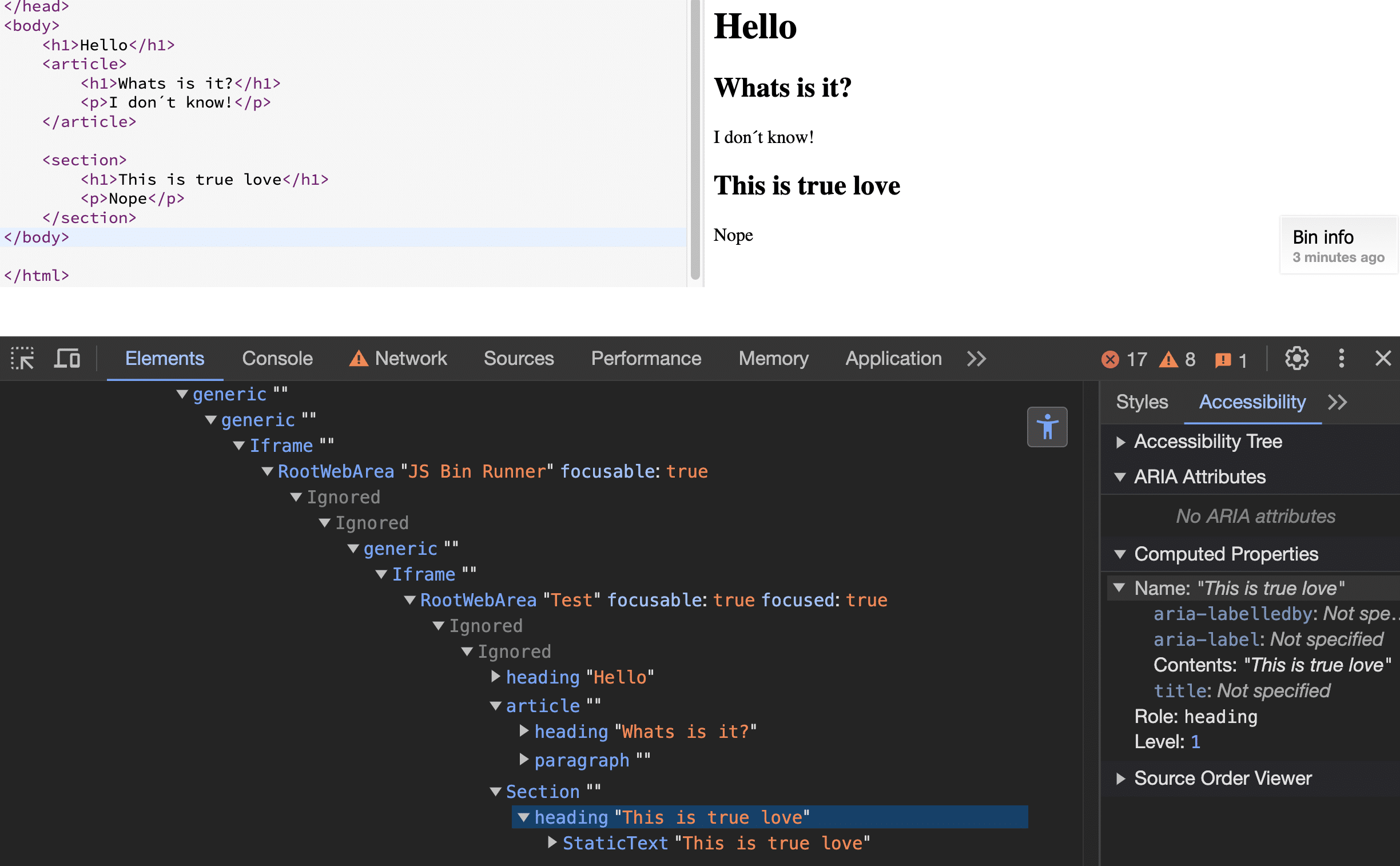 Example 2:
Example 2: 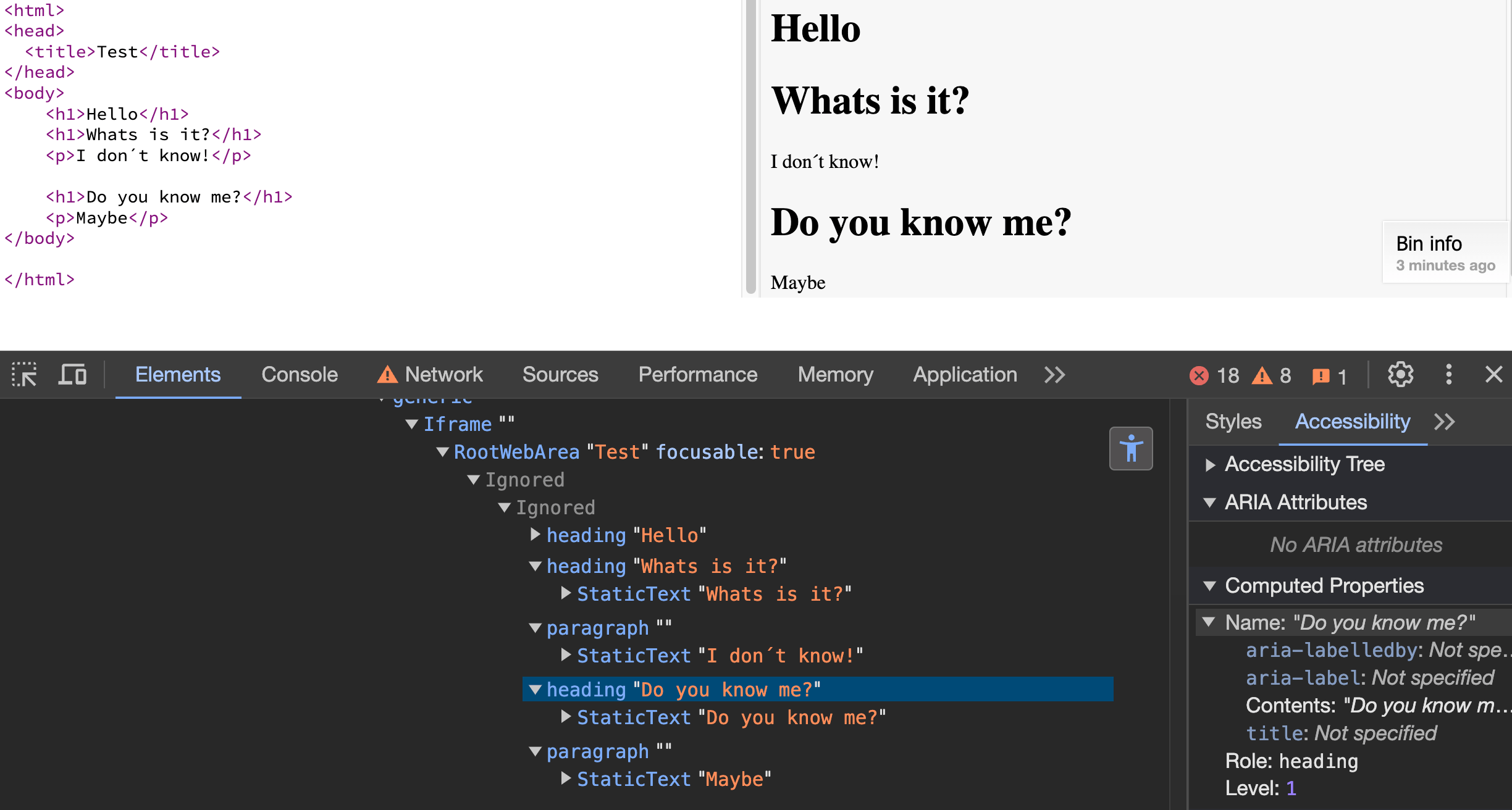 Example 3: All
Example 3: All  This
This