Google’s Algorithms Uncovered: How the Search Engine Works According to Leaked Documents
In this article, we delve into the inner workings of Google, a tool we all use daily but few truly understand. Following the recent leak of documents in an antitrust lawsuit against Google, we have a unique opportunity to explore Google’s algorithms. Some of these algorithms were already known, but what’s interesting is the internal information that had never been shared with us.
We will examine how these technologies process our searches and determine the results we see. In this analysis, I aim to provide a clear and detailed view of the complex systems behind each Google search.
Moreover, I will attempt to represent Google’s architecture in a diagram, taking into account the new discoveries.
Google’s Algorithms Uncovered
First, we're going to focus on extracting all the algorithms mentioned in four key documents from the U.S. antitrust trial against Google.
The first is about the testimony of Pandu Nayak (VP of Google Search). The second is about the rebuttal testimony of Professor Douglas W. Oard, regarding opinions offered by Google's expert, Prof. Edward A. Fox. The latter discusses the famous and controversial "Fox Report," where Google allegedly manipulated data from an experiment to try to prove that user data is not that important to them.
Additionally, we will add two documents from the final phase of the trial, where information about technologies like FastSearch was revealed. The third is the plaintiffs' final proposed remedies, which details the demands on Google and mentions these technologies for the first time. And the fourth, and perhaps the most revealing, is the final Memorandum Opinion from Judge Amit Mehta, an extensive document that details the proven facts and final decisions, offering an unprecedented look into the inner workings of Google's search technologies.
I will try to explain each algorithm based on official information, if available, and then I will post an image with the information extracted from the trial.
Navboost
It’s key for Google and one of the most important factors. This also came out in the 2019 «Project Veritas» leak because Paul Haar added it to his CV
Navboost collects data on how users interact with search results, specifically through their clicks on different queries. This system tabulates clicks and uses algorithms that learn from human-made quality ratings to improve the ranking of results. The idea is that if a result is frequently chosen (and positively rated) for a specific query, it probably should have a higher ranking. Interestingly, Google experimented many years ago with removing Navboost and found that the results worsened.
RankBrain
Launched in 2015, RankBrain it’s a Google AI and machine learning system, essential in processing search results. Through machine learning, it continually improves its ability to understand language and the intentions behind searches and is particularly effective in interpreting ambiguous or complex queries. It is said to have become the third most important factor in Google’s ranking, after content and links. It uses a Tensor Processing Unit (TPU) to significantly enhance its processing capability and energy efficiency.
I deduce that QBST and Term Weighting are components of RankBrain. So, I include them here.
QBST (Query Based Salient Terms) focuses on the most important terms within a query and related documents, using this information to influence how results are ranked. This means the search engine can quickly recognize the most important aspects of a user’s query and prioritize relevant results. For instance, this is particularly useful for ambiguous or complex queries.
In the testimony document, QBST is mentioned in the context of BERT’s limitations. The specific mention is that «BERT does not subsume large memorization systems such as navboost, QBST, etc.» This means that although BERT is highly effective in understanding and processing natural language, it has certain limitations, one of which is its capacity to handle or replace large-scale memorization systems like QBST.
Term Weighting adjusts the relative importance of individual terms within a query, based on how users interact with search results. This helps determine how relevant certain terms are in the context of the query. This weighting also efficiently handles terms that are very common or very rare in the search engine’s database, thus balancing the results.
DeepRank
Goes a step further in understanding natural language, enabling the search engine to better understand the intention and context of queries. This is achieved thanks to BERT; in fact, DeepRank is the internal name for BERT. By pre-training on a large amount of document data and adjusting with feedback from clicks and human ratings, DeepRank can fine-tune search results to be more intuitive and relevant to what users are actually searching for.
RankEmbed
RankEmbed probably focuses on the task of embedding relevant features for ranking. Although there are no specific details about its function and capabilities in the documents, we can infer that it is a deep learning system designed to improve Google’s search classification process.
RankEmbed-BERT
RankEmbed-BERT is an enhanced version of RankEmbed, integrating the algorithm and structure of BERT. This integration was carried out to significantly improve RankEmbed’s language comprehension capabilities. Its effectiveness can decrease if not retrained with recent data. For its training, it only uses a small fraction of the traffic, indicating that it’s not necessary to use all available data.
RankEmbed-BERT contributes, along with other deep learning models such as RankBrain and DeepRank, to the final ranking score in Google’s search system, but would operate after the initial retrieval of results (re-ranking). It is trained on click and query data and finely tuned using data from human evaluators (IS) and is more computationally expensive to train than feedforward models such as RankBrain.
FastSearch
FastSearch is a proprietary technology that Google uses internally for its Gemini models. It is based on RankEmbed signals and is designed to quickly generate an abbreviated set of highly relevant organic results that an AI model can use for the "grounding" process. I believe it might use a technology like PLAID or ColBERT for its operation and could be responsible for how AI Overviews and AI Mode work. FastSearch delivers results faster than a full web search because it retrieves fewer documents, albeit at the cost of slightly lower quality. Google does not offer it directly to third parties, but rather integrated into its Vertex AI product, where customers get the information from the results via its API, but not the ranked results themselves, to protect Google's intellectual property.
MUM
It’s approximately 1,000 times more powerful than BERT and represents a major advancement in Google’s search. Launched in June 2021, it not only understands 75 languages but is also multimodal, meaning it can interpret and process information in different formats. This multimodal capability allows MUM to offer more comprehensive and contextual responses, reducing the need for multiple searches to obtain detailed information. However, its use is very selective due to its high computational demand.
Tangram and Glue
All these systems work together within the framework of Tangram, which is responsible for assembling the SERP with data from Glue. This is not just a matter of ranking results, but organizing them in a way that is useful and accessible to users, considering elements like image carousels, direct answers, and other non-textual elements.
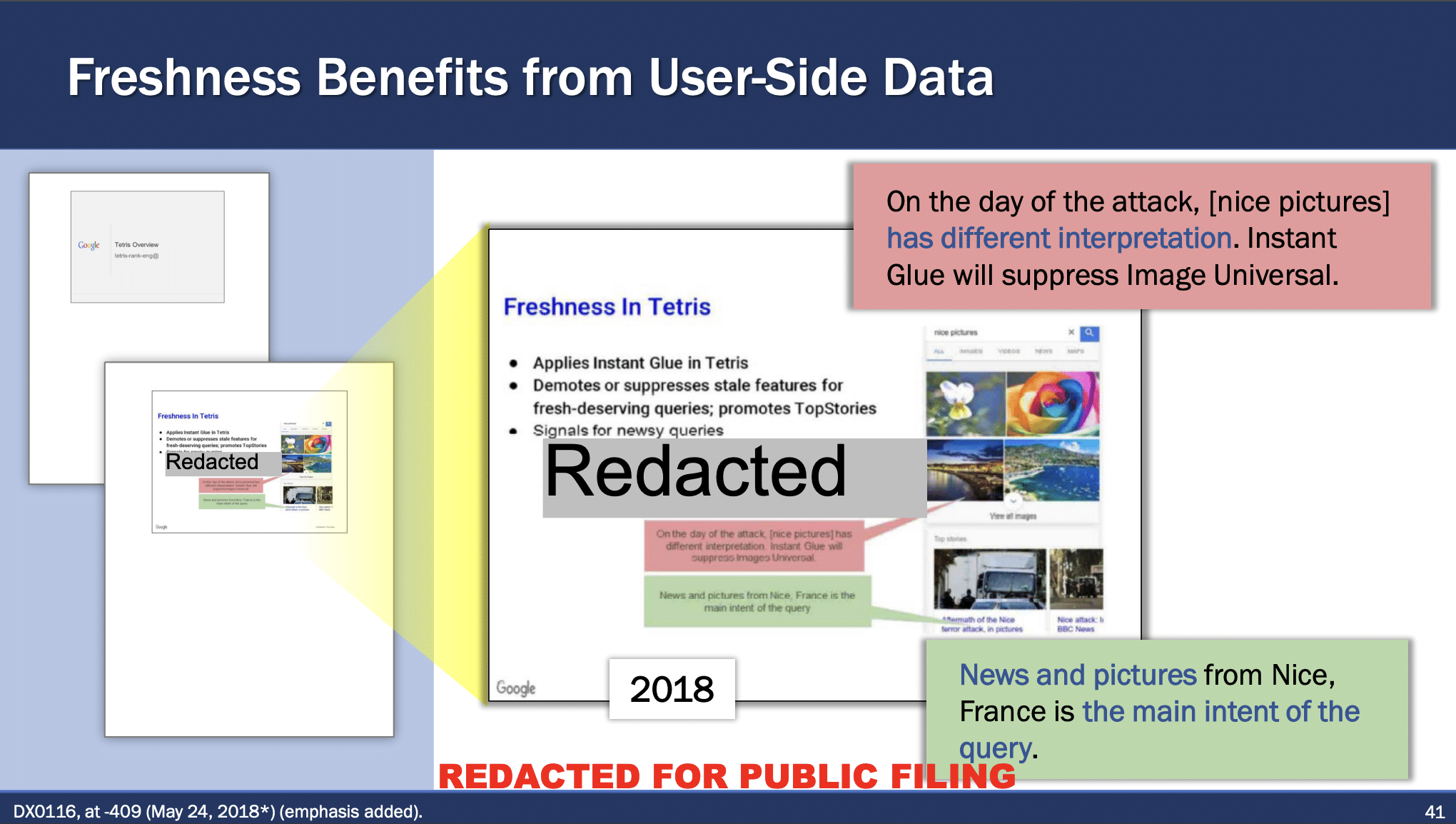
Finally, Freshness Node and Instant Glue ensure that the results are current, giving more weight to recent information, which is especially crucial in searches about news or current events.
In the trial, they make a reference to the attack in Nice, where the main intent of the query changed on the day of the attack, leading Instant Glue to suppress general images to Tangram and instead promote relevant news and photographs from Nice («nice pictures» vs «Nice pictures»):
With all this, Google would combine these algorithms to:
Understandthe query: Deciphering the intention behind the words and phrases users enter in the search bar.
Determine relevance: Ranking the results based on how the contents match the query, using signals from past interactions and quality ratings.
Prioritize freshness: Ensuring that the freshest and most relevant information rises in the rankings when it’s important to do so.
Personalizeresults: Tailoring search results not just to the query but also to the user’s context, such as their location and the device they are using. There’s hardly more personalization than this.
From everything we’ve seen so far, I believe Tangram, Glue, and RankEmbed-BERT are the only novel items leaked to date.
As we have seen, these algorithms are nourished by various metrics that we will now break down, once again, extracting information from the trial.
In one of the slides, it was shown that Google uses the following metrics to develop and adjust the factors its algorithm considers when ranking search results and to monitor how changes in its algorithm affect the quality of search results. The goal is to try to capture the user’s intent with them.
1. IS Score
Human evaluators play a crucial role in the development and refinement of Google’s search products. Through their work, the metric known as «IS score» (Information Satisfaction Score ranging from 0 to 100) is generated, derived from the evaluators’ ratings and used as a primary indicator of quality in Google.
It is evaluated anonymously, where evaluators do not know if they are testing Google or Bing, and it is used to compare Google’s performance against its main competitor.
These IS scores not only reflect perceived quality but are also used to train various models within Google’s search system, including classification algorithms like RankBrain and RankEmbed BERT.
According to the documents, as of 2021, they are using IS4. IS4 is considered an approximation of utility for the user and should be treated as such. It is described as possibly the most important ranking metric, yet they emphasize that it is an approximation and prone to errors that we will discuss later.
A derivative of this metric, the IS4@5, is also mentioned.
The IS4@5 metric is used by Google to measure the quality of search results, focusing specifically on the first five positions. This metric includes both special search features, such as OneBoxes (known as «blue links»). There is a variant of this metric, named IS4@5 web, which focuses exclusively on evaluating the first five web results, excluding other elements like advertising in the search results.
Although IS4@5 is useful for quickly assessing the quality and relevance of the top results in a search, its scope is limited. It does not cover all aspects of search quality, particularly omitting elements like advertising in the results. Therefore, the metric provides a partial view of search quality. For a complete and accurate evaluation of the quality of Google’s search results, it is necessary to consider a broader range of metrics and factors, similar to how general health is assessed through a variety of indicators and not just by weight.
Limitations of Human Evaluators
Evaluators face several issues, such as understanding technical queries or judging the popularity of products or interpretations of queries. Additionally, language models like MUM may come to understand language and global knowledge similarly to human evaluators, posing both opportunities and challenges for the future of relevance assessment.
Despite their importance, their perspective differs significantly from that of real users. Evaluators may lack specific knowledge or previous experiences that users might have in relation to a query topic, potentially influencing their assessment of relevance and the quality of search results.
From leaked documents from 2018 and 2021, I was able to compile a list of all the errors Google recognizes they have in their internal presentations.
Temporal Mismatches: Discrepancies can occur because queries, evaluations, and documents may be from different times, leading to assessments that do not accurately reflect the current relevance of the documents.
Reusing Evaluations: The practice of reusing evaluations to quickly evaluate and control costs can result in evaluations that are not representative of the current freshness or relevance of the content.
Understanding Technical Queries: Evaluators may not understand technical queries, leading to difficulties in assessing the relevance of specialized or niche topics.
Evaluating Popularity: There is an inherent difficulty for evaluators in judging the popularity among competitive query interpretations or rival products, which could affect the accuracy of their evaluations.
Diversity of Evaluators: The lack of diversity among evaluators in some locations, and the fact that they are all adults, does not reflect the diversity of Google’s user base, which includes minors.
User-Generated Content: Evaluators tend to be harsh with user-generated content, which can lead to underestimating its value and relevance, despite it being useful and relevant.
Freshness Node Training: They signal a problem with tuning freshness models due to a lack of adequate training labels. Human evaluators often do not pay enough attention to the freshness aspect of relevance or lack the temporal context for the query. This results in undervaluing recent results for queries seeking novelty. The existing Tangram Utility, based on IS and used to train Relevance and other scoring curves, suffered from the same problem. Due to the limitation of human labels, the scoring curves of the Freshness Node were manually adjusted upon its first release.
The new launch of Google Notes, I believe, also points to this reason. Google is incapable of knowing with 100% certainty what constitutes quality content.
I believe that these events I’m discussing, which have occurred almost simultaneously, are not a coincidence and that we will soon see changes.
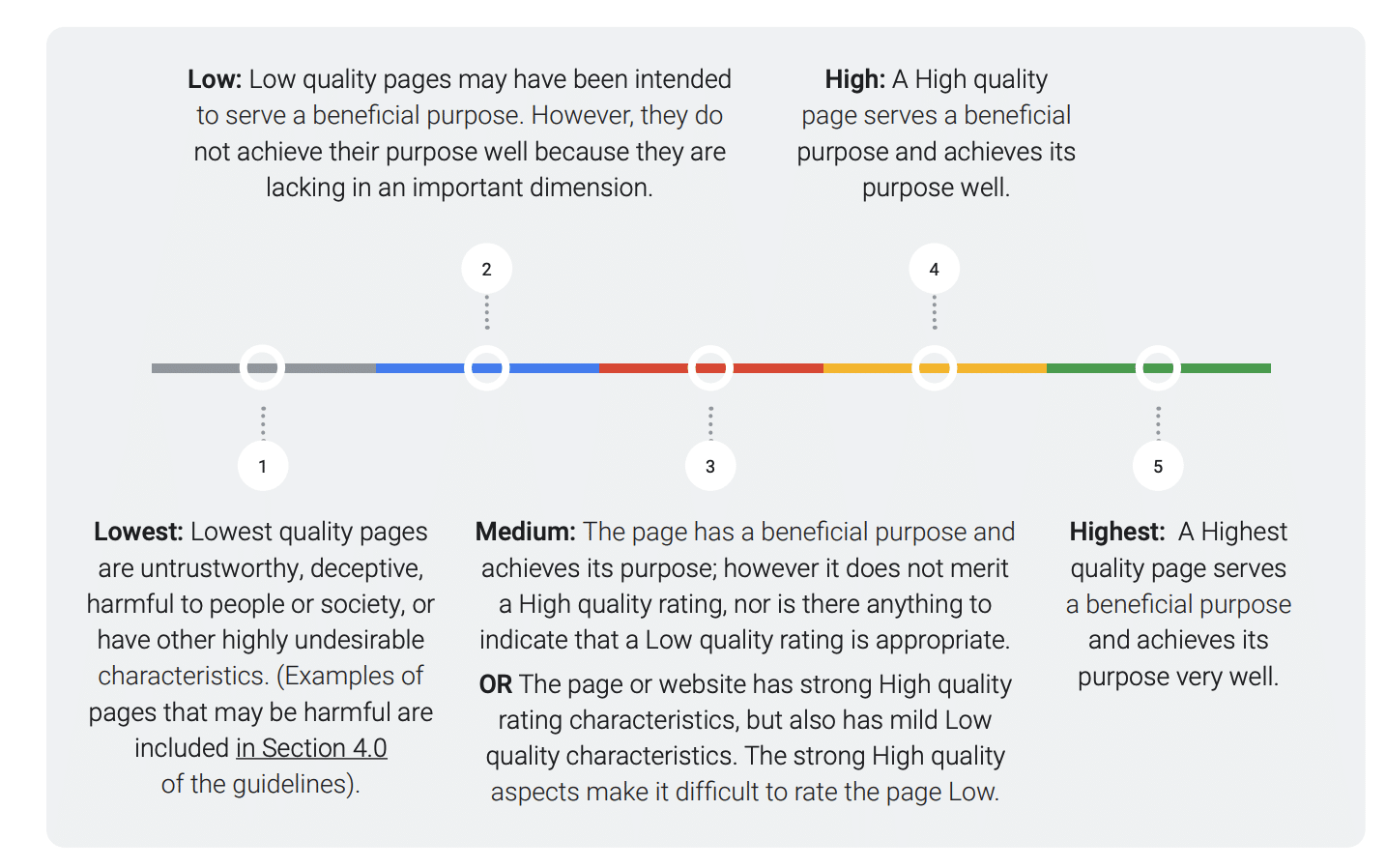
2. PQ (Page Quality)
Here I deduce they are talking about Page Quality, so this is my interpretation. If so, there is nothing in the trial documents beyond its mention as a used metric. The only official thing I have that mentions PQ is from Search Quality Rater Guidelines, which change over time. So, it would be another task for human evaluators.
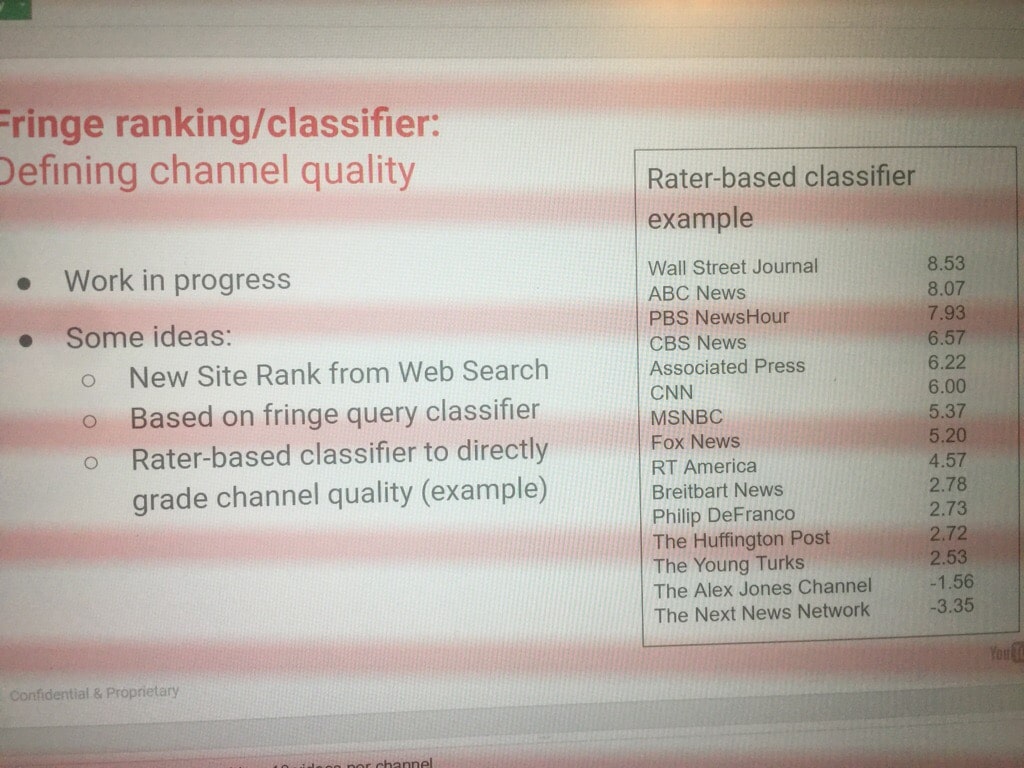
This information is also sent to the algorithms to create models. Here we can see a proposal of this leaked in the «Project Veritas»:
An interesting point here, according to the documents, quality raters only evaluate pages on mobile.
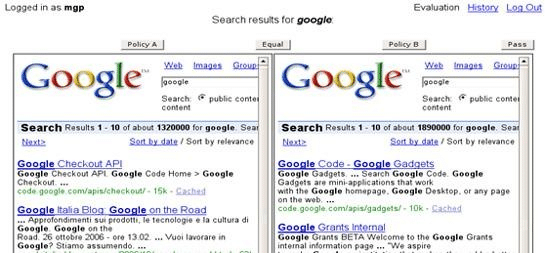
3. Side-by-Side
This probably refers to tests where two sets of search results are placed side by side so that evaluators can compare their relative quality. This helps determine which set of results is more relevant or useful for a given search query. If so, I remember that Google had its own downloadable tool for it, the sxse.
The tool allows users to vote for the set of search results they prefer, thus providing direct feedback on the effectiveness of different adjustments or versions of the search systems.
4. Live Experiments
The official information published in How Search Works says that Google conducts experiments with real traffic to test how people interact with a new feature before rolling it out to everyone. They activate the feature for a small percentage of users and compare their behavior with a control group that does not have the feature. Detailed metrics on user interaction with search results include:
Clicks on results
Number of searches performed
Query abandonment
How long it took for people to click on a result
This data helps measure whether interaction with the new feature is positive and ensures that the changes increase the relevance and utility of search results.
But the trial documents highlight only two metrics:
Position weighted long clicks: This metric would consider the duration of clicks and their position on the results page, reflecting user satisfaction with the results they find.
Attention: This could imply measuring the time spent on the page, giving an idea of how long users are interacting with the results and their content.
Furthermore, in the transcript of Pandu Nayak’s testimony, it is explained that they conduct numerous algorithm tests using interleaving instead of traditional A/B tests. This allows them to perform rapid and reliable experiments, thereby enabling them to interpret fluctuations in rankings.
5. Freshness
Freshness is a crucial aspect of both results and Search Features. It is essential to show relevant information as soon as it is available and stop showing content when it becomes outdated.
For the ranking algorithms to display recent documents in the SERP, the indexing and serving systems must be able to discover, index, and serve fresh documents with very low latency. Although ideally, the entire index would be as up-to-date as possible, there are technical and cost constraints that prevent indexing every document with low latency. The indexing system prioritizes documents on separate paths, offering different trade-offs between latency, cost, and quality.
There is a risk that very fresh content will have its relevance underestimated and, conversely, that content with a lot of evidence of relevance will become less relevant due to a change in the meaning of the query.
The role of the Freshness Node is to add corrections to outdated scores. For queries seeking fresh content, it promotes fresh content and degrades outdated content.
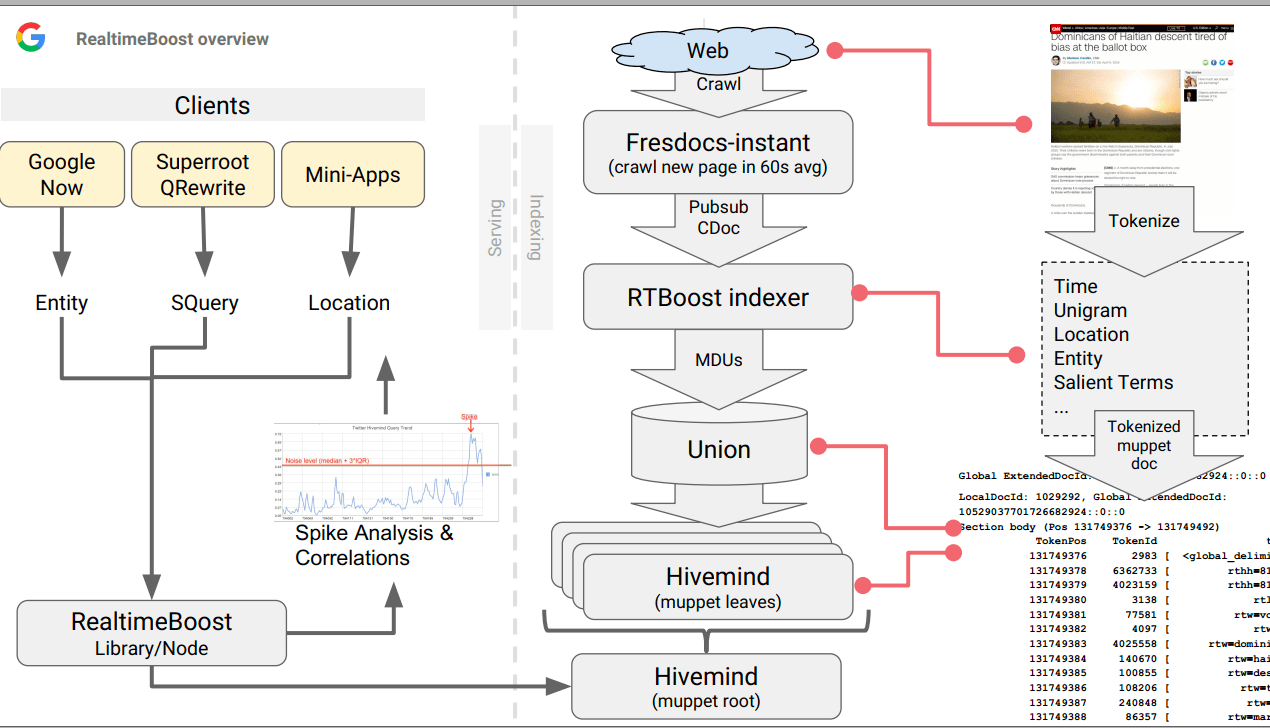
Not long ago, it was leaked that Google Caffeine no longer exists (also known as the Percolator-based indexing system). Although internally the old name is still used, what exists now is actually a completely new system. The new «caffeine» is actually a set of microservices that communicate with each other. It implies that different parts of the indexing system operate as independent but interconnected services, each performing a specific function. This structure can offer greater flexibility, scalability, and ease of making updates and improvements.
As I interpret part of these microservices would be Tangram and Glue, specifically the Freshness Node and Instant Glue. I say this because in another leaked document from «Project Veritas» I found that there was a proposal from 2016 to make or incorporate an «Instant Navboost» as a Freshness signal, as well as Chrome visits.
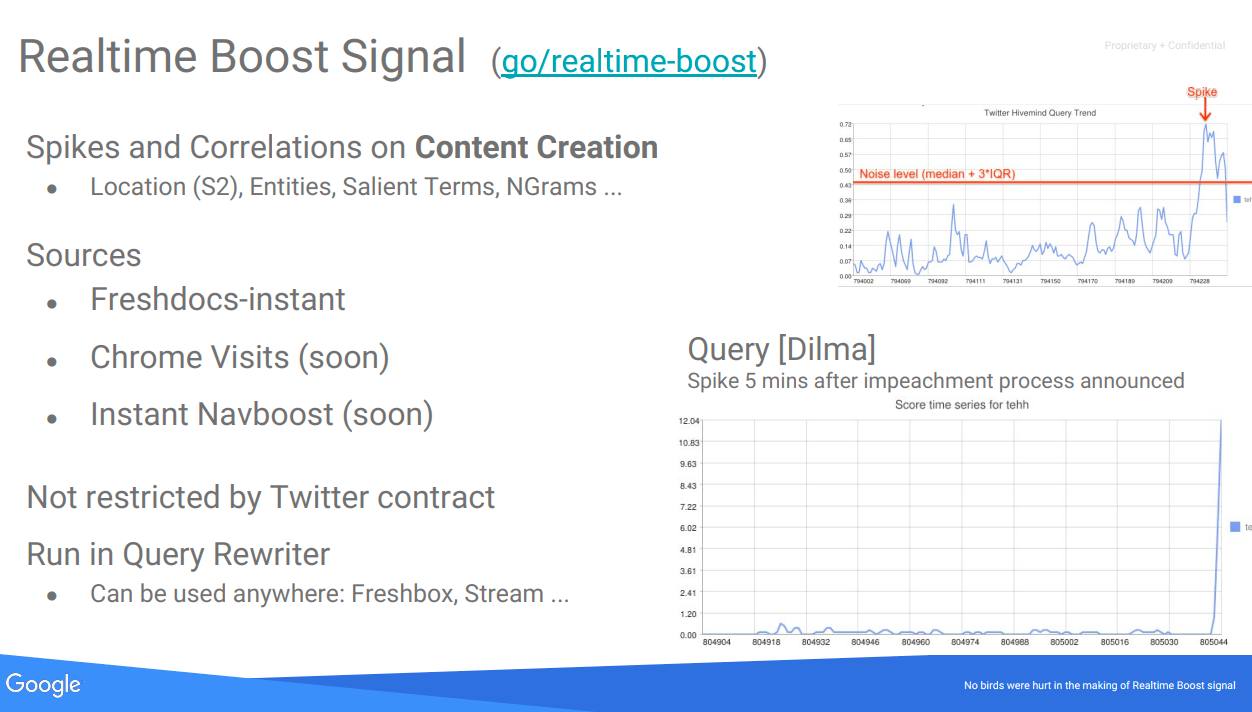
So far, they had already incorporated «Freshdocs-instant» (extracted from a list of pubsub called freshdocs-instant-docs pubsub, where they took the news published by those media within 1 minute from its publication) and search spikes and content generation correlations:
Within the Freshness metrics, we have several that are detected thanks to the analysis of Correlated Ngrams and Correlated Salient Terms:
Correlated NGrams: These are groups of words that appear together in a statistically significant pattern. The correlation can suddenly increase during an event or trending topic, indicating a spike.
Correlated Salient Terms: These are standout terms that are closely associated with a topic or event and whose frequency of occurrence increases in documents over a short period, suggesting a spike in interest or related activity.
Once spikes are detected, the following Freshness metrics could be being used:
Unigrams (RTW): For each document, the title, anchor texts, and the first 400 characters of the main text are used. These are broken down into unigrams relevant to trend detection and are added to the Hivemind index. The main text generally contains the main content of the article, excluding repetitive or common elements (boilerplate).
Half Hours since epoch (TEHH): This is a measure of time expressed as the number of half-hours since the start of Unix time. It helps establish when something happened with half-hour accuracy.
Knowledge Graph Entities (RTKG): References to objects in Google’s Knowledge Graph, which is a database of real entities (people, places, things) and their interconnections. It helps to enrich search with semantic understanding and context.
S2 Cells (S2): References to objects in Google’s Knowledge Graph, which is a database of real entities (people, places, things) and their interconnections. It helps enrich search with semantic understanding and context.
Freshbox Article Score (RTF): These are geometric divisions of the Earth’s surface used for geographic indexing in maps. They facilitate the association of web content with precise geographical locations.
Document NSR (RTN): This could refer to the News Relevance of the Document and appears to be a metric that determines how relevant and reliable a document is in relation to current stories or trending events. This metric can also help filter out low-quality or spam content, ensuring that the documents indexed and highlighted are of high quality and significant for real-time searches.
Geographical Dimensions: Features that define the geographical location of an event or topic mentioned in the document. These can include coordinates, place names, or identifiers such as S2 cells.
If you work in media, this information is key and I always include it in my trainings for digital editors.
Throughout this process, we see the fundamental importance of clicks in understanding user behavior/needs. In other words, Google needs our data. Interestingly, one of the things Google was forbidden to talk about was clicks.
Before starting, it’s important to note that the main documents discussed about clicks predate 2016, and Google has undergone significant changes since then. Despite this evolution, the basis of their approach remains the analysis of user behavior, considering it a quality signal. Do you remember the patent where they explain the CAS model?
Every search and click provided by users contributes to Google’s learning and continuous improvement. This feedback loop allows Google to adapt and «learn» about search preferences and behaviors, maintaining the illusion that it understands user needs.
Daily, Google analyzes over a billion new behaviors within a system designed to continuously adjust and surpass future predictions based on past data. At least until 2016, this exceeded the capacity of AI systems at that time, requiring the manual work we saw earlier and also adjustments made by RankLab.
RankLab, I understand, is a laboratory that tests different weights in signals and ranking factors, as well as their subsequent impact. They might also be responsible for the internal tool «Twiddler» (something I also read years ago from «Project Veritas»), with the purpose of manually modifying the IR-scores of certain results, or in other words, to be able to do all the following:
After this brief interlude, I continue.
While human evaluator ratings offer a basic view, clicks provide a much more detailed panorama of search behavior.
This reveals complex patterns and allows learning of second and third-order effects.
Second-order effects reflect emerging patterns: If the majority prefer and choose detailed articles over quick lists, Google detects it. Over time, it adjusts its algorithms to prioritize those more detailed articles in related searches.
Third-order effects are broader, long-term changes: If click trends favor comprehensive guides, content creators adapt. They start producing more detailed articles and fewer lists, thus changing the nature of content available on the web.
In the analyzed documents, a specific case is presented where search result relevance was improved through click analysis. Google identified a discrepancy in user preference, based on clicks, towards a few documents that turned out to be relevant, despite being surrounded by a set of 15,000 considered irrelevant documents. This discovery highlights the importance of user clicks as a valuable tool for discerning hidden relevance in large volumes of data.
Google «trains with the past to predict the future» to avoid overfitting. Through constant evaluations and data updating, models remain current and relevant. A key aspect of this strategy is localization personalization, ensuring that results are pertinent for different users in various regions.
Regarding personalization, in a more recent document, Google asserts that it is limited and rarely changes rankings. They also mention that it never occurs in «Top Stories». The times it is used is to better understand what is being searched for, for example, using the context of previous searches and also to make predictive suggestions with autocomplete. They mention they might slightly elevate a video provider the user frequently uses, but everyone would see basically the same results. According to them, the query is more important than user data.
It’s important to remember that this click-focused approach faces challenges, especially with new or infrequent content. Evaluating the quality of search results is a complex process that goes beyond just counting clicks. Although this article I wrote has several years, I think it can help to delve deeper into this.
Google’s Architecture
Following the previous section, this is the mental image I have formed of how we could place all these elements in a diagram. It’s very likely that some components of Google’s architecture are not in certain places or do not relate as such, but I believe it is more than sufficient as an approximation.
Possible functioning and architecture of Google. Click to make the image larger.
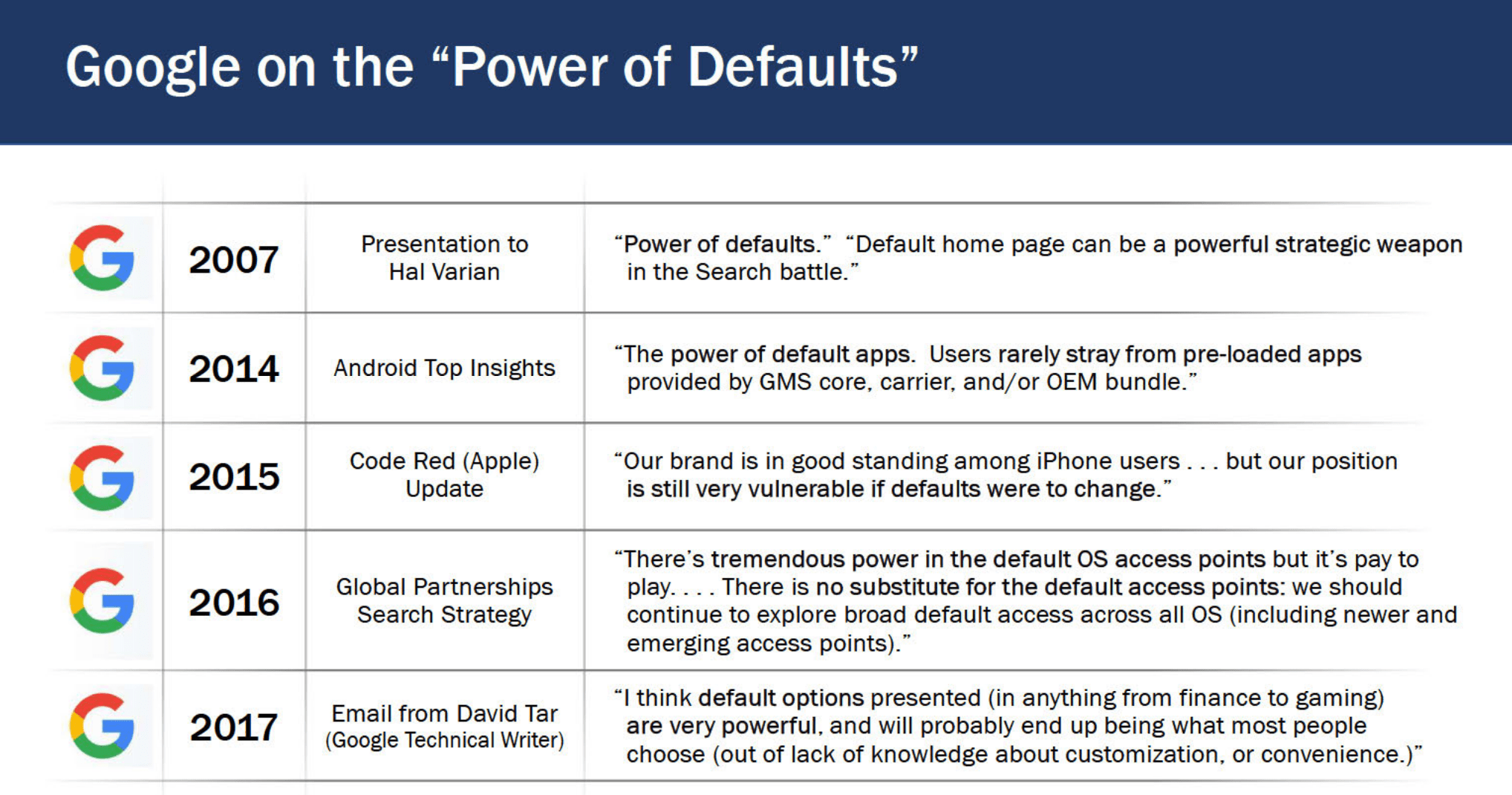
Google and Chrome: The Struggle to Be the Default Search Engine and Browser
As Jim Kolotouros reveals in internal communications, Chrome is not just a browser, but a key piece in Google’s search dominance puzzle.
Among the data Google collects are search patterns, clicks on search results, and interactions with different websites, which is crucial for refining Google’s algorithms and improving the accuracy of search results and the effectiveness of targeted advertising.
For Antonio Rangel, Chrome’s market supremacy transcends its popularity. It acts as a gateway to Google’s ecosystem, influencing how users access information and online services. Chrome’s integration with Google Search, being the default search engine, grants Google a significant advantage in controlling the flow of information and digital advertising.
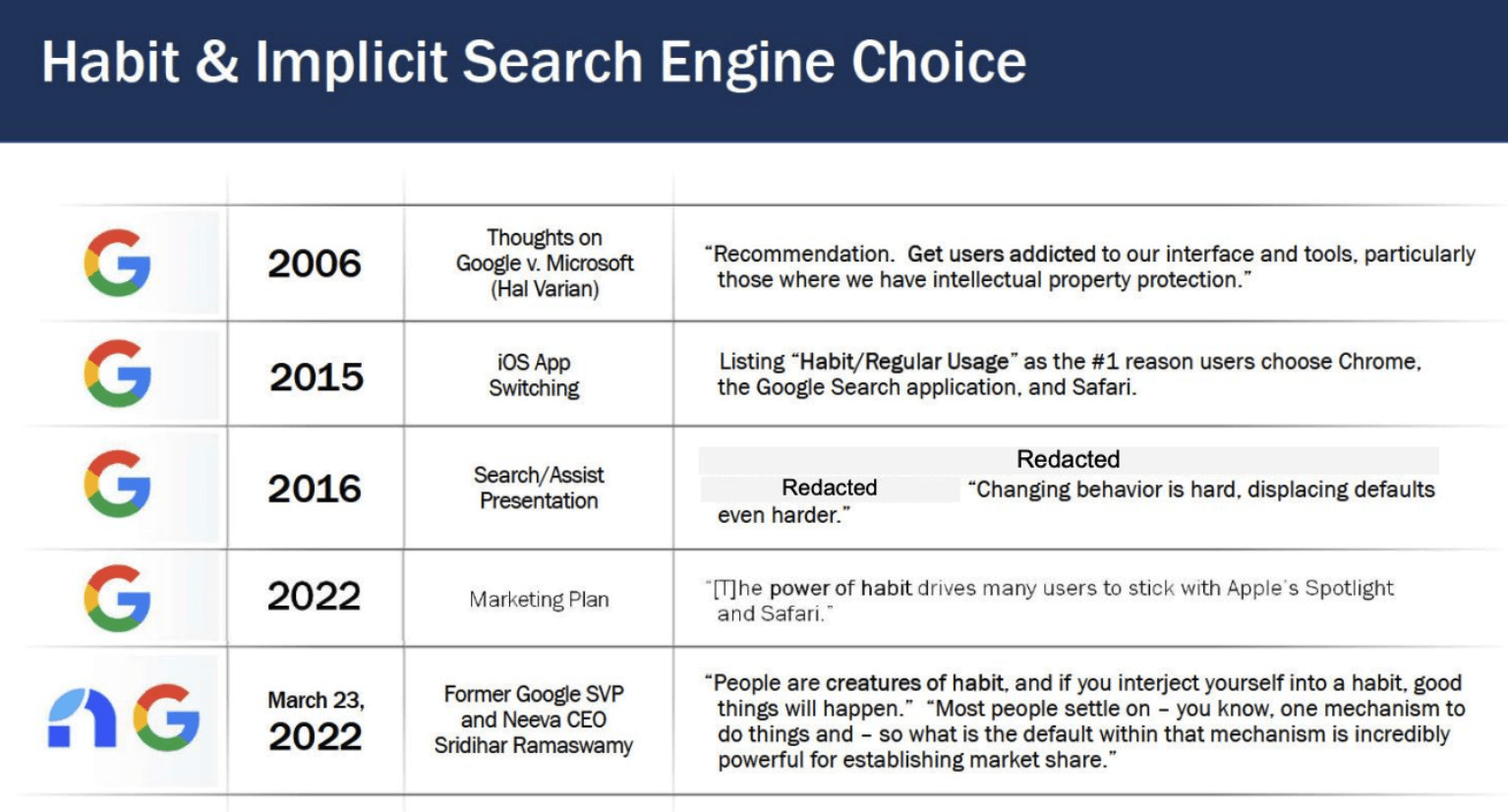
Despite Google’s popularity, Bing is not an inferior search engine. However, many users prefer Google due to the convenience of its default configuration and associated cognitive biases. On mobile devices, the effects of default search engines are stronger due to the friction involved in changing them; up to 12 clicks are required to modify the default search engine.
This default preference also influences consumer privacy decisions. Google’s default privacy settings present significant friction for those who prefer more limited data collection. Changing the default option requires awareness of available alternatives, learning the necessary steps for change, and implementation, representing considerable friction. Additionally, behavioral biases like status quo and loss aversion make users lean towards maintaining Google’s default options. I explain all this better here.
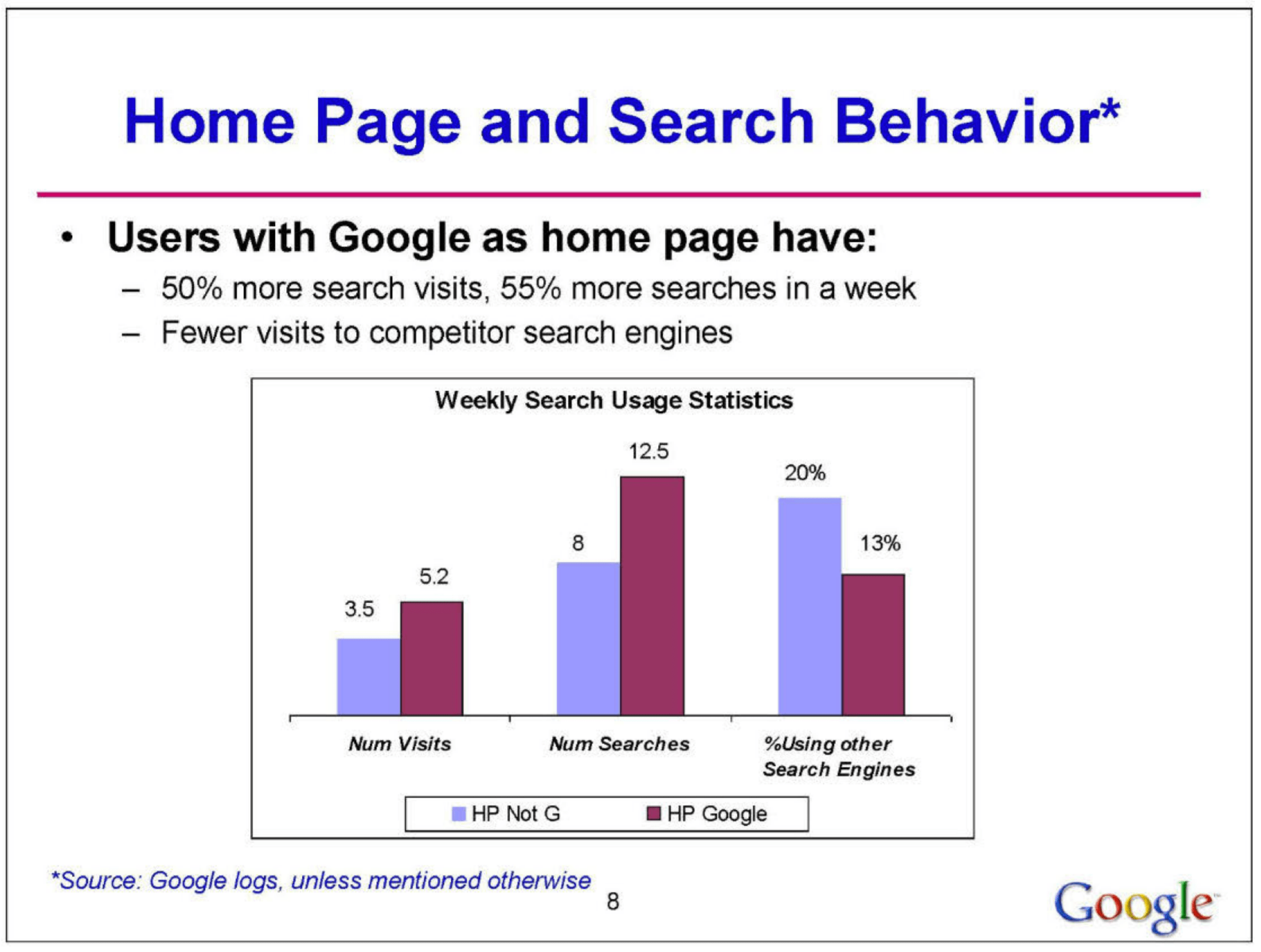
The testimony of Antonio Rangel directly resonates with Google’s internal analysis revelations. The document reveals that the browser’s homepage setting has a significant impact on the market share of search engines and user behavior. Specifically, a high percentage of users who have Google as their default homepage perform 50% more searches on Google than those who do not.
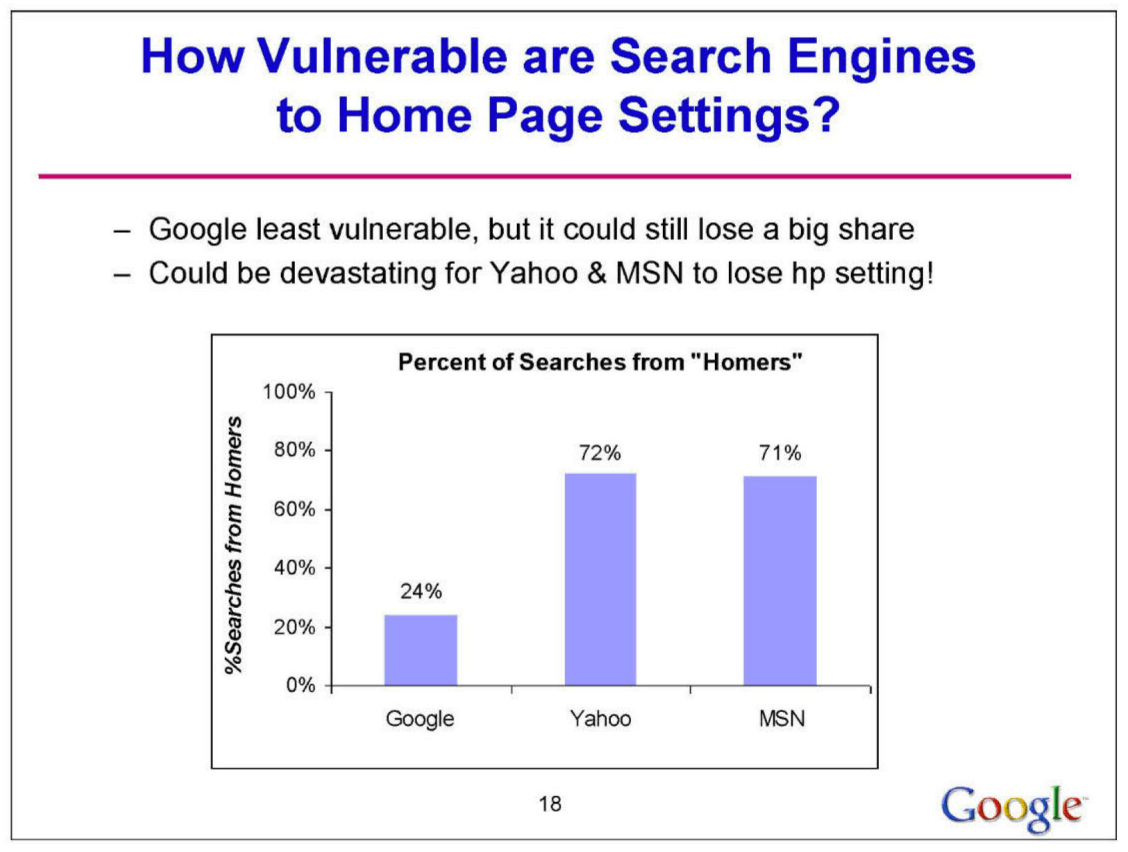
This suggests a strong correlation between the default homepage and search engine preference. Additionally, the influence of this setting varies regionally, being more pronounced in Europe, the Middle East, Africa, and Latin America, and less so in Asia-Pacific and North America. The analysis also shows that Google is less vulnerable to changes in the homepage setting compared to competitors like Yahoo and MSN, which could suffer significant losses if they lose this setting.
The homepage setting is identified as a key strategic tool for Google, not only to maintain its market share but also as a potential vulnerability for its competitors. Furthermore, it highlights that most users do not actively choose a search engine, but lean towards the default access provided by their homepage setting. In economic terms, an incremental lifetime value of approximately $3 per user is estimated for Google when set as the homepage.
Conclusion
After exploring Google’s algorithms and internal workings, we have seen the significant role that user clicks and human evaluators play in the ranking of search results.
Additionally, human evaluators contribute a crucial layer of assessment and understanding that, even in the era of artificial intelligence, remains indispensable. Personally, I am very surprised at this point, knowing that evaluators were important, but not to this extent.
These two inputs combined, automatic feedback through clicks and human oversight, allow Google not only to better understand search queries but also to adapt to changing trends and information needs. As AI advances, it will be interesting to see how Google continues to balance these elements to improve and personalize the search experience in an ever-changing ecosystem with a focus on privacy.
On the other hand, Chrome is much more than a browser; it’s the critical component of their digital dominance. Its synergy with Google Search and its default implementation in many areas impact market dynamics and the entire digital environment. We will see how the antitrust trial ends, but they have been without paying about 10,000 million euros in fines for abuse of dominant position for more than 10 years.
Making accurate decisions in the volatile world of SEO can be challenging, especially when facing complex and unfamiliar situations. In this scenario, the Cynefin framework can guide us in managing SEO projects in an increasingly VUCA (Volatile, Uncertain, Complex, and Ambiguous) or BANI (Brittle, Anxious, Non-linear, and Incomprehensible) environment. At the end of this article, […]
More than a decade ago, heading optimization had a significant impact on ranking. While their influence has diminished, they remain useful for search engines. Additionally, headings not only indirectly affect SEO by improving content understanding and user engagement, but also influence how your content appears in search results and help new agents and assistants with […]





















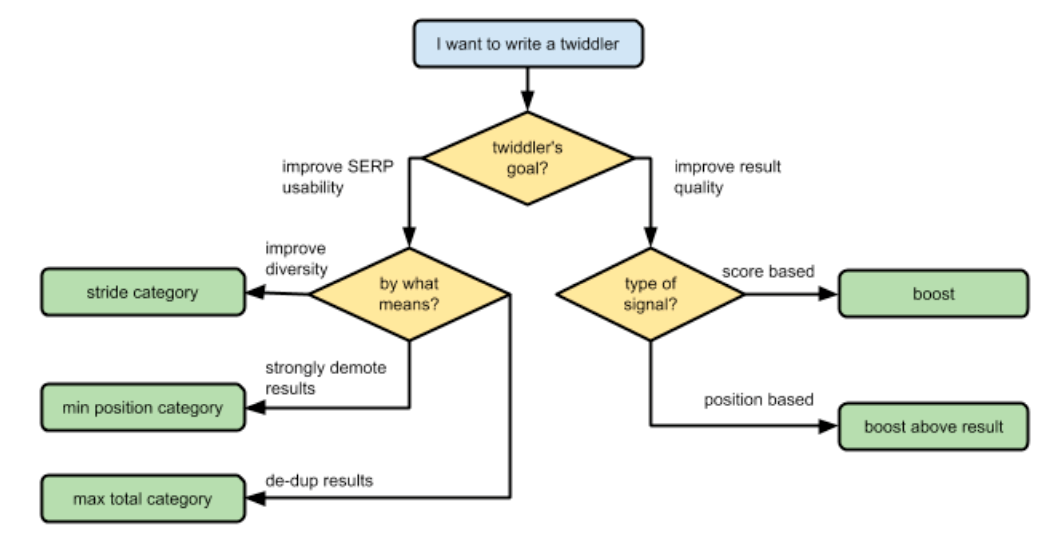



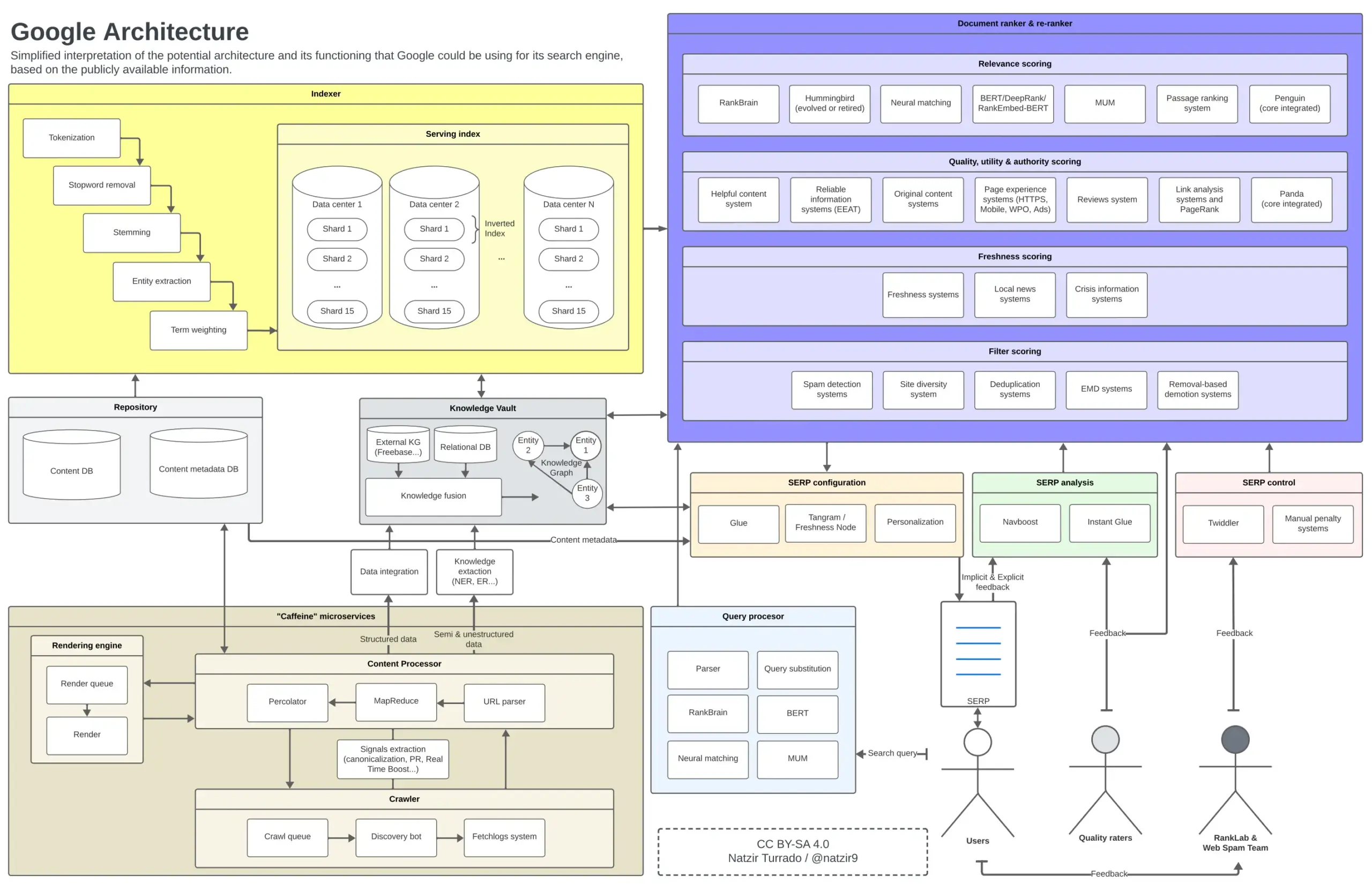 Possible functioning and architecture of Google. Click to make the image larger.
Possible functioning and architecture of Google. Click to make the image larger.