Cuando un buscador necesita encontrar información, puede intentar entenderte de dos maneras, o interpretando el significado abstracto de lo que pides o buscando las palabras exactas que has utilizado. Ambos enfoques son potentes pero incompletos por sí solos.
En este artículo veremos qué es la búsqueda híbrida y las técnicas que los buscadores como Google llevan usando desde hace años (2015) y que también han incorporado a los grandes LLMs a la búsqueda impulsada por IA .
Índice de contenidos:
1. La búsqueda léxica (aka el mundo de las palabras exactas)
La búsqueda léxica o por palabras clave es el enfoque tradicional. Su misión es encontrar documentos que contengan los términos exactos de la búsqueda.
Primero se tokeniza el texto (se divide en palabras o subpalabras), y luego se aplican algoritmos como TF-IDF o su evolución, BM25, que calculan la relevancia basándose en la frecuencia de aparición de esos tokens. Estos algoritmos actúan como el índice de un libro, registrando qué tokens aparecen y dónde. Los sistemas modernos suelen usar tokenización a nivel de subpalabras en lugar de palabras completas, lo que les permite manejar mejor palabras nuevas, términos técnicos o errores tipográficos.
Pero también pueden usar SPLADE, que es una versión más avanzada de la búsqueda léxica. Aunque también se basa en encontrar palabras clave, utiliza redes neuronales para aprender qué términos son realmente importantes en un contexto. De esta forma, logra capturar un matiz de significado semántico sin dejar de ser un sistema léxico, preciso y eficiente.
Además de SPLADE, han surgido otras técnicas neurales que mejoran la búsqueda léxica sin perder precisión:
- uniCOIL y COIL: Crean representaciones contextualizadas para cada término. Mientras BM25 trata "banco" igual en "banco de peces" y "banco financiero", estas técnicas, como SPLADE entienden el contexto de cada palabra manteniendo la precisión del match exacto.
- DeepCT y DeepImpact: Usan BERT para recalcular la importancia de cada término. Si un documento habla de "automóviles" sin mencionar "Tesla", estos modelos pueden inferir que Tesla es relevante y ajustar los pesos.
- Doc2query y docTTTTTquery: Técnicas de expansión que predicen qué preguntas podría responder un documento y las añaden como metadata invisible. Un documento sobre "paracetamol" automáticamente se expande con queries como "dolor de cabeza medicamento" o "fiebre tratamiento".
Estas técnicas resuelven el problema del *vocabulary mismatch* (cuando el usuario y el documento usan palabras diferentes para lo mismo) sin sacrificar la precisión quirúrgica de la búsqueda léxica.
- Lo bueno de la búsqueda léxica es que ofrece una precisión quirúrgica. Es perfecta para encontrar identificadores únicos, nombres propios o jerga técnica.
- Lo malo de la búsqueda léxica es que es rígida y literal, por lo que no entiende sinónimos ni contexto. Si solo buscas "coche", nunca encontrará un documento que solo diga "automóvil".
2. La búsqueda semántica (aka el mundo de los significados)
La búsqueda semántica se centra en comprender la intención y el contexto. Su objetivo es capturar la idea que hay detrás de las palabras y para ello utiliza embeddings densos.
Cómo se crean los embeddings
La arquitectura más común es el modelo Two-Tower que funciona así: una "torre" procesa tu consulta de búsqueda y la otra procesa cada documento de la base de datos. Ambas torres son redes neuronales entrenadas para convertir el texto en vectores numéricos de longitud fija que capturan su significado.
Es necesario que ambas torres generen vectores en el mismo espacio vectorial compartido. De esta forma se podrá medir la relevancia entre una búsqueda y un documento usando métricas simples como el "dot product" (que usa Google por eficiencia) o la similitud del coseno. Cuanto mayor sea esta similitud, más relevante es el documento para esa búsqueda. Lo ingenioso es que las dos torres se entrenan juntas para maximizar la similitud entre consultas y sus documentos relevantes, mientras la minimizan para documentos irrelevantes.
Imagina que cada texto o frase se convierte en un punto en un vasto "mapa de significados". En este mapa, conceptos similares como "automóvil" y "coche" se sitúan muy cerca unos de otros.
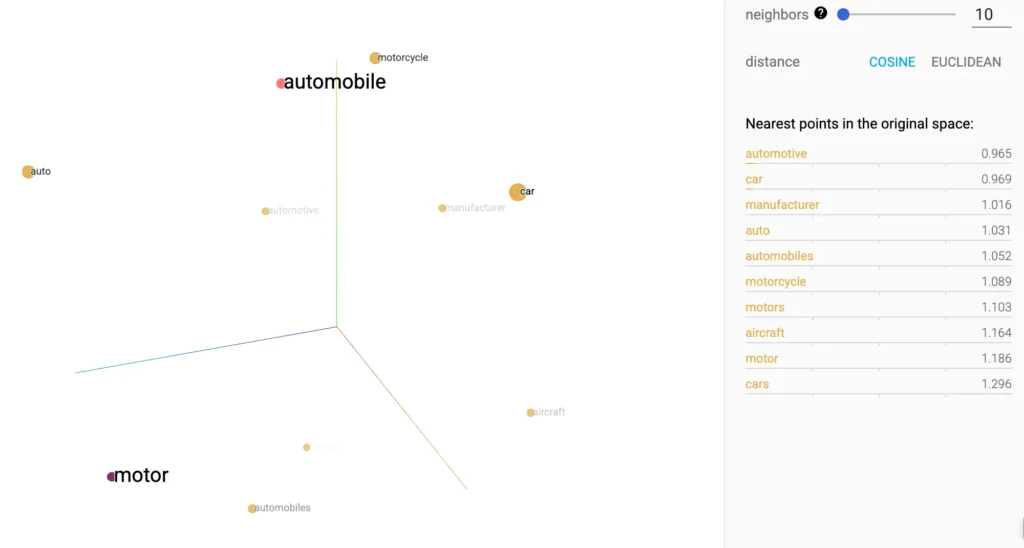
- Lo bueno de la búsqueda semántica es que es excepcional para el lenguaje natural. Permite que una búsqueda de "ropa para jóvenes" encuentre resultados que hablen de "moda para adolescentes", ya que el sistema entiende la generalización semántica.
- Lo malo de la búsqueda semántica es que falla con términos que no tienen un significado conceptual o que son demasiado específicos (lo que se conoce como datos "fuera de dominio"). Por ejemplo, un código de producto como "SKU 8-XYZ-45" es solo ruido para este sistema.
Para curiosos: Los embeddings de Two-Tower generan un vector único por documento, pero buscar entre millones requiere índices especializados:
- HNSW: Construye grafos multicapa para navegación rápida. Usado por Weaviate y Qdrant.
- ScaNN : Cuantización asimétrica optimizada para billones de vectores. Lo usa Google y ahora lo ofrece en Vertex AI
- FAISS: Combina clustering (IVF) con compresión (PQ). La elección de Meta. Yo lo uso en migraciones SEO complicadas.
- Annoy: Usa árboles binarios aleatorios. Más simple pero efectivo para datasets medianos. Escogido por Spotify.
Estos índices permiten buscar entre mil millones de vectores en milisegundos y son el motor invisible detrás de toda búsqueda semántica.
3. La búsqueda híbrida
Dado que ninguno de los dos enfoques anteriores es perfecto, la mejor solución combinarlos mediante búsqueda híbrida.
La búsqueda híbrida es un sistema que aprovecha la similitud léxica de la búsqueda por palabras clave y la similitud semántica de la búsqueda vectorial. Se ha convertido en una pieza indispensable de los sistemas modernos de recuperación de información, y utilizada también en aplicaciones de Retrieval-Augmented Generation (RAG).

El buscador de Google es el ejemplo más famoso de buscador híbrido. Con la introducción de RankBrain en 2015, Google añadió una potente capa semántica a su estructura, que ya funcionaba (demasiado) bien encontrando palabras exactas, creando así un sistema híbrido a gran escala. Recordemos que RankBrain es un sistema de inteligencia artificial que ayuda a comprender las conexiones entre palabras y conceptos. Esto significa que Google puede ofrecer contenido más relevante incluso cuando no incluye exactamente las mismas palabras de la búsqueda, ya que entiende que el contenido está relacionado con otros términos y conceptos.
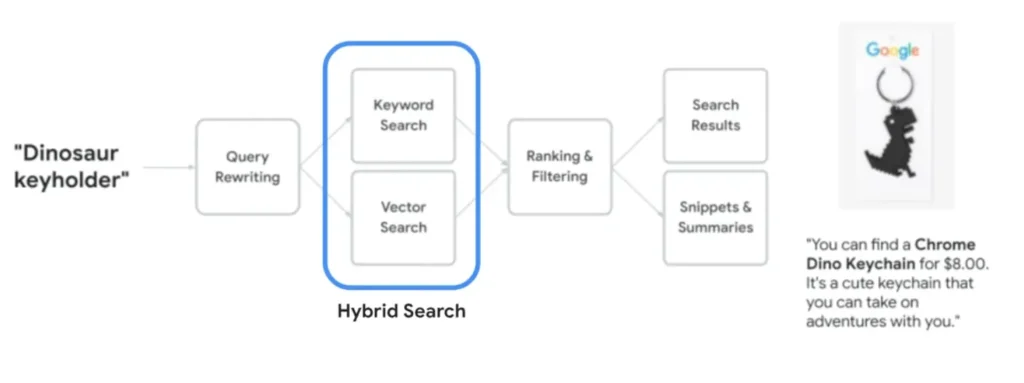
¿Cómo se combinan los resultados? El papel de Reciprocal Rank Fusion
Cuando tienes dos listas de resultados (una semántica, otra léxica), necesitas un método inteligente para fusionarlas. La solución más usada es el Reciprocal Rank Fusion (RRF).
RRF funciona de una forma muy simple, en lugar de intentar comparar las puntuaciones de relevancia de cada sistema (que no son compatibles), RRF solo se fija en la posición (el rango) que ocupa un documento en cada lista. Un resultado que aparece bien posicionado en ambas listas es recompensado y sube a la cima del ranking final.
Sistemas modernos como Google Vertex AI añaden un parámetro alpha (0 a 1) para controlar el peso entre búsqueda semántica y léxica antes de aplicar RRF. Con alpha=1 solo usas búsqueda semántica, con alpha=0 solo léxica (típicamente 0,5 para dar igual peso a ambas). En ChatGPT, el alpha está a 1.
Métodos como BM25 (léxico) y la búsqueda vectorial (semántica) producen puntuaciones en escalas totalmente incompatibles, por lo que sumarlas directamente no tiene sentido. RRF soluciona esto al basarse únicamente en la posición, lo que lo hace estable y resistente a valores atípicos.
RRF es básico en cualquier sistema de IA que utilizan RAG como las AI Overviews, AI Mode o ChatGPT. Recordemos que RAG es el proceso por el cual una IA, antes de responder, primero "busca" información en una base de datos para basar su respuesta en hechos. La búsqueda híbrida recupera los documentos, y RRF los ordena para que la IA sepa cuáles son los más importantes. Este proceso, también conocido como "grounding", es lo que pretende evitar que la IA invente información. Tal y como comentamos en el artículo sobre los leaks de ChatGPT, sistemas como ChatGPT también utilizan RRF internamente para mejorar la relevancia y la coherencia de sus respuestas.
4. Búsqueda multi-etapa
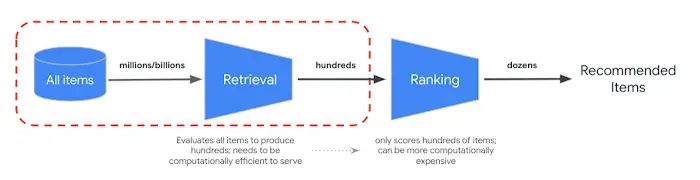
En los sistemas más avanzados, desde Google hasta los motores de IA generativa, el proceso no termina con la fusión. Operan con una arquitectura de dos fases (multi-etapa) para ser a la vez rápidos y precisos:
- Recuperación (Retrieval): La primera fase consiste en encontrar rápidamente un conjunto amplio de candidatos potencialmente relevantes de entre miles de millones de documentos. Es aquí donde se aplica la búsqueda híbrida, combinando resultados léxicos y semánticos mediante RRF. La velocidad es la prioridad absoluta.
- Re-ranking (Reranking): La segunda fase consiste en analizar en detalle solo ese conjunto de candidatos para ordenarlos con la máxima precisión. Aquí la prioridad es la calidad del resultado.
Ahora, veamos qué tecnologías y modelos específicos entran en cada etapa.
Retrieval
Para ser extremadamente rápido, esta fase utiliza una búsqueda híbrida, combinando la búsqueda léxica (palabras clave) y la semántica (significado). Aquí es donde entran tecnologías como ColBERT y PLAID, que es muy probable que sean las que estén en producción en Google. Muvera no, como explico aquí.
- ColBERT: A diferencia de la búsqueda semántica tradicional con Two-Tower que crea un solo vector para todo el documento, ColBERT es mucho más granular. Crea un vector para cada palabra y luego, durante la búsqueda, compara cada palabra de la consulta con cada palabra del documento. Este método, llamado "interacción tardía", le da una precisión mucho mayor desde el inicio. Mientras que Two-Tower es más rápido pero menos preciso, ColBERT sacrifica algo de velocidad por mayor precisión semántica.
- PLAID: El método de ColBERT es muy potente pero computacionalmente caro. PLAID es un motor de indexación diseñado específicamente para resolver este problema en ColBERT. Organiza los vectores de ColBERT de una manera ultra eficiente, permitiendo que esas complejas comparaciones palabra por palabra se realicen a una velocidad increíble.
- FastSearch: Es una tecnología propietaria que Google utiliza internamente para sus modelos Gemini. Se basa en las señales de RankEmbed y está diseñada para generar rápidamente un conjunto abreviado de resultados orgánicos de alta relevancia que un modelo de IA puede usar para el proceso de "grounding". Creo que podría usar alguna de las 2 tecnologías anteriores para su funcionamiento y que podría ser la usada en las AI Overviews y AI Mode. FastSearch entrega resultados más rápido que la búsqueda web completa porque recupera menos documentos, aunque a costa de una calidad ligeramente inferior. Google no lo ofrece directamente a terceros, sino integrado en su producto Vertex AI, donde los clientes obtienen la información de los resultados a través de su API, pero no los resultados rankeados en sí mismos, para proteger la propiedad intelectual de Google.
Re-ranking
Una vez que la etapa de recuperación nos ha entregado unos cientos de buenos candidatos, es el momento de usar la artillería pesada para ordenarlos de forma definitiva. Aquí entran los grandes modelos de lenguaje, que son demasiado lentos para la primera fase pero perfectos para este análisis detallado.
- BERT fue pionero en entender el contexto y los matices de todas las palabras en una frase. Es un "analista de contexto" de alta precisión que se usa en esta fase para verificar si un documento candidato realmente responde a la intención específica de la consulta.
- MUM es la evolución. Es un modelo mucho más potente que no solo entiende el texto con más profundidad, sino que también es multilingüe (puede usar conocimiento de varios idiomas) y multimodal (puede entender la relación entre texto e imágenes). Es como un juez final que puede usar una gama mucho más amplia de señales para determinar el mejor resultado. Pero desde Google dice que sólo lo usan para los featured snippets, topics relacionados en vídeos, Google Lens y alguna que otra función.
- T5 y otros LLMs: En esta fase, pueden usarse para tareas muy sofisticadas, como generar un resumen "ideal" de la respuesta y puntuar a los candidatos según cuánto se parezcan a ese ideal.
Este proceso de dos etapas permite que los sistemas ofrezcan resultados que son, a la vez, instantáneos y extremadamente relevantes. Pero no nos podemos olvidar de la diversificación. En sistemas profesionales se aplican algoritmos como MMR (Maximal Marginal Relevance) o xQuAD para evitar redundancia. Si los top 5 resultados dicen básicamente lo mismo entonces MMR los penaliza y sube contenido complementario. Esto es especialmente crítico para AI Overviews y RAG, porque si alimentas un LLM con 5 documentos idénticos, desperdicias contexto valioso. MMR garantizaría que cada documento aporte información única, cubriendo diferentes aspectos de la query. Google casi seguro lo usa, por eso ves resultados variados incluso para búsquedas ambiguas.
Nota técnica: Este artículo simplifica conceptos complejos para hacerlos accesibles. Los sistemas de producción reales combinan estas técnicas de formas propietarias no siempre documentadas. Las implementaciones específicas de Google, OpenAI y otros son en gran parte especulativas basadas en papers públicos y comportamiento observable.
Artículos relacionados:
Por qué trocear tu contenido es malo para tu SEO y para la IA
¿Se puede hacer SEO para Muvera? ¿Existe el Muvera Update?
Lo que los leaks de ChatGPT nos enseñan sobre SEO para la IA
Los algoritmos de Google al descubierto. Cómo funciona el buscador según documentos filtrados