En este artículo nos adentramos en el funcionamiento interno de Google, una herramienta que todos usamos a diario pero que pocos comprendemos realmente. A raíz de la reciente filtración de documentos en un juicio antimonopolio contra Google, tenemos una gran oportunidad para explorar los algoritmos de Google. De algunos de ellos ya teníamos información, pero lo interesante es ver información interna que nunca había sido compartida con nosotros.
Examinaremos cómo estas tecnologías procesan nuestras búsquedas y determinan los resultados que vemos. En este análisis pretendo ofrecer una visión clara y detallada de los complejos sistemas que están detrás de cada búsqueda en Google.
Además, trataré de representar la arquitectura de Google en un diagrama, teniendo en cuenta los nuevos descubrimientos.
Los algoritmos de Google al descubierto
Primero, nos vamos a centrar en extraer todos los algoritmos mencionados en 2 documentos. El primero es sobre el testimonio de Pandu Nayak (VP Alphabet) y el segundo es sobre el testimonio de Refutación del Profesor Douglas W. Oard, sobre opiniones ofrecidas por el experto de Google, el Prof. Edward A. Fox, en su informe del 3 de junio de 2022. En este último se debatió el famoso y controvertido «Informe Fox», donde Google manipularon los datos del experimento realizado para tratar de demostrar que los datos de usuarios no son tan importantes para ellos.
Trataré de explicar cada algoritmo según información oficial, en caso que la haya, y luego pondré en una imagen la información extraída del juicio.

Navboost
Es clave para Google y uno de los factores más importantes. Esto también salió en el leak de «Project Veritas» de 2019, porque lo añadió Paul Haar a su CV:

Navboost recoge datos de cómo los usuarios interactúan con los resultados de búsqueda, específicamente a través de sus clics en diferentes consultas. Este sistema tabula los clics y utiliza algoritmos que aprenden de las valoraciones de calidad hechas por humanos para mejorar la clasificación de los resultados. La idea es que si un resultado es frecuentemente elegido (y valorado positivamente) para una consulta específica, probablemente debería tener una clasificación más alta. Como curiosidad, Google experimentó hace muchos años quitando Navboost y comprobó como los resultados empeoraron.

RankBrain
Lanzado en 2015, RankBrain es un sistema de inteligencia artificial y aprendizaje automático de Google, esencial en el procesamiento de resultados de búsqueda. A través del aprendizaje automático, mejora continuamente su capacidad para entender el lenguaje y las intenciones detrás de las búsquedas y es especialmente eficaz en interpretar consultas ambiguas o complejas. Se dice que se ha convertido en el tercer factor más importante en el ranking de Google, después del contenido y los enlaces. Utiliza una Unidad de Procesamiento Tensorial (TPU) para mejorar significativamente su capacidad de procesamiento y eficiencia energética.

Deduzco que QBST y Term Weighting son componentes de RankBrain. Así que los incluyo aquí.
QBST (Query Based Salient Terms) se centra en los términos más importantes dentro de una consulta y los documentos relacionados, utilizando esta información para influir en cómo se clasifican los resultados. Esto significa que el motor de búsqueda puede reconocer rápidamente cuáles son los aspectos más importantes de la consulta del usuario y priorizar resultados relevantes. Por ejemplo, esto es especialmente útil para consultas ambiguas o complejas.
En el documento del testimonio, QBST se menciona en el contexto de las limitaciones de BERT. La mención específica es que «BERT no integra grandes sistemas de memorización como navboost, QBST, etc.». Esto significa que, aunque BERT es altamente eficaz en entender y procesar el lenguaje natural, tiene ciertas limitaciones, una de las cuales es su capacidad para manejar o reemplazar sistemas de memorización a gran escala como QBST.

Term Weighting ajusta la importancia relativa de los términos individuales dentro de una consulta, basándose en cómo los usuarios interactúan con los resultados de búsqueda. Esto ayuda a determinar qué tan relevantes son ciertos términos en el contexto de la consulta. Esta ponderación también permite manejar eficientemente términos que son muy comunes o muy raros en la base de datos del motor de búsqueda, equilibrando así los resultados.

DeepRank
Va un paso más allá en la comprensión del lenguaje natural, permitiendo al buscador entender mejor la intención y el contexto de las consultas. Esto lo logra gracias a BERT, de hecho, DeepRank es el nombre interno de BERT. Al pre-entrenarse en una gran cantidad de datos de documentos y ajustarse con la retroalimentación de los clics y las calificaciones humanas, DeepRank puede afinar los resultados de búsqueda para que sean más intuitivos y relevantes a lo que los usuarios realmente están buscando.

RankEmbed
RankEmbed es un sistema de deep learning que probablemente se centre en la tarea de inclusión de características relevantes (embedding) para el ranking. Aunque no hay detalles específicos sobre su función y capacidades en los documentos, podemos inferir que es un sistema de aprendizaje profundo diseñado para mejorar el proceso de clasificación de búsquedas de Google.
RankEmbed-BERT
RankEmbed-BERT es una versión mejorada de RankEmbed, que integra el algoritmo y la estructura de BERT. Esta integración se realizó para mejorar significativamente las capacidades de RankEmbed en la comprensión del lenguaje. Su efectividad puede disminuir si no se reentrena con datos recientes. Para su entrenamiento, sólo utiliza una pequeña fracción del tráfico, lo que indica que no es necesario usar todos los datos disponibles.
Contribuye junto con otros modelos de aprendizaje profundo, como RankBrain y DeepRank, a la puntuación final de clasificación en el sistema de búsqueda de Google, pero operaría después de la recuperación inicial de resultados (re-ranking). Se entrena con datos de clics y consultas y se ajusta finamente utilizando datos de evaluadores humanos (IS) y su entrenamiento es más costoso computacionalmente que el de modelos feedforward como RankBrain.

MUM
Es aproximadamente 1.000 veces más potente que BERT y representa un gran avance en la búsqueda de Google. Se lanzó en junio de 2021 y no sólo entiende 75 idiomas, sino que también es multimodal, lo que significa que puede interpretar y procesar información en diferentes formatos. Esta capacidad multimodal permite a MUM ofrecer respuestas más completas y contextuales, reduciendo la necesidad de múltiples búsquedas para obtener información más detallada. Aunque su uso es muy selectivo debido a su alta demanda computacional.

Tangram y Glue
Todos estos sistemas trabajan juntos dentro del marco de Tangram, el cual es responsable de ensamblar la SERP con los datos de Glue. Esto no es sólo una cuestión de clasificar los resultados, sino de organizarlos de manera que sean útiles y accesibles para los usuarios, considerando elementos como carruseles de imágenes, respuestas directas y otros elementos no textuales.

Finalmente, el Freshness Node e Instant Glue garantiza que los resultados sean actuales, dándole más peso a la información reciente, lo cual es especialmente crucial en búsquedas sobre noticias o eventos actuales.

En el juicio hacen una referencia al ataque en Niza, donde la intención principal de la consulta cambió en el día del ataque, lo que llevó a Instant Glue a suprimir las imágenes generales a Tangram y en su lugar promover noticias y fotografías relevantes de Niza («Nice pictures» vs «Nice pictures»):

Con todo esto, Google combinaría estos algoritmos para:
- Entender la consulta: Descifrando la intención detrás de las palabras y frases que los usuarios ingresan en la barra de búsqueda.
- Determinar la relevancia: Clasificando los resultados en función de cómo los contenidos coinciden con la consulta, utilizando señales de interacciones pasadas y valoraciones de calidad.
- Priorizar la actualidad: Asegurándose de que la información más fresca y relevante suba en los rankings cuando es importante hacerlo.
- Personalizar los resultados: Adaptando los resultados de búsqueda no sólo a la consulta sino también al contexto del usuario, como su ubicación y el dispositivo que está utilizando. Apenas hay más personalización que esta.
De todo lo que hemos visto hasta al momento, creo que Tangram, Glue y RankEmbed-BERT es lo único novedoso filtrado hasta la fecha.
Como hemos podido ver, estos algoritmos se nutren de varias métricas que vamos a desengranar ahora, una vez más, sacando información del juicio.
Métricas que usa Google para evaluar la calidad de la búsqueda
En este apartado, nos centraremos de nuevo en el testimonio de Refutación del Profesor Douglas W. Oard e incluiré información de un leak anterior, el del «Project Veritas».
En una de las diapositivas, se mostró que Google utiliza las siguientes métricas para desarrollar y ajustar los factores que su algoritmo considera al clasificar los resultados de búsqueda y para monitorear cómo los cambios en su algoritmo afectan la calidad de los resultados de búsqueda. El objetivo es tratar de capturar la intención del usuario con ellas.
1. IS Score
Los evaluadores humanos desempeñan un rol importantísimo en el desarrollo y refinamiento de los productos de búsqueda de Google. A través de su labor, se genera la métrica conocida como «IS score» (Information Satisfaction Score que va de 0 a 100), que se deriva de las valoraciones de los evaluadores y es utilizada como un indicador principal de la calidad en Google.
Es evaluado de manera anónima, quienes no saben si están probando Google o Bing y se utiliza para comparar el rendimiento de Google vs su principal competidor.
Estos IS scores no solo reflejan la calidad percibida sino que también se utilizan para entrenar diversos modelos dentro del sistema de búsqueda de Google, incluyendo algoritmos de clasificación como RankBrain y RankEmbed BERT.
Según los documentos en 2021 van por la IS4. Se considera que el IS4 es una aproximación de la utilidad para el usuario y hay que tratarla como tal. La describen como posiblemente la métrica de ranking más importante, pero aún así recalcan que es una aproximación y propensa a errores que luego comentaremos.

También se menciona un derivado de esta métrica, la IS4@5.
La métrica IS4@5 es utilizada por Google para medir la calidad de los resultados de búsqueda, centrándose específicamente en las primeras cinco posiciones. Esta métrica incluye tanto características especiales de búsqueda, como los OneBoxes (conocidos como «enlaces azules»). Existe una variante de esta métrica, denominada IS4@5 web, que se enfoca exclusivamente en evaluar los cinco primeros resultados web, excluyendo otros elementos como la publicidad en los resultados de búsqueda.

Aunque IS4@5 es útil para evaluar rápidamente la calidad y relevancia de los primeros resultados en una búsqueda, su alcance es limitado. No abarca todos los aspectos de la calidad de búsqueda, particularmente omitiendo elementos como la publicidad en los resultados. La métrica, por tanto, proporciona una visión parcial de la calidad de búsqueda. Para una evaluación completa y precisa de la calidad de los resultados de búsqueda de Google, es necesario considerar una gama más amplia de métricas y factores, de manera similar a cómo se evalúa la salud general mediante una variedad de indicadores y no sólo por el peso.
Limitaciones de los Evaluadores Humanos
Los evaluadores se enfrentan a varios problemas, tales como entender consultas técnicas o juzgar la popularidad de productos o interpretaciones de consultas. Además, modelos de lenguaje como MUM pueden llegar a comprender el lenguaje y el conocimiento mundial de forma parecida a los evaluadores humanos, lo que plantea tanto oportunidades como retos para el futuro de la evaluación de la relevancia.
A pesar de su importancia, su perspectiva difiere significativamente de la de los usuarios reales. Los evaluadores pueden carecer de conocimientos específicos o experiencias previas que los usuarios podrían tener en relación a un tema de consulta, lo que potencialmente puede influir en la valoración de la relevancia y la calidad de los resultados de búsqueda.
De documentos filtrados del 2018 y 2021 pude sacar una lista de todos los errores que Google reconocía que tienen en sus presentaciones internas.
- Desajustes Temporales: Pueden ocurrir discrepancias debido a que las consultas, valoraciones y documentos pueden ser de diferentes tiempos, lo que conlleva a evaluaciones que no reflejan con precisión la relevancia actual de los documentos.
- Reutilización de Valoraciones: La práctica de reutilizar valoraciones para evaluar rápidamente y controlar costes puede resultar en valoraciones que no son representativas de la frescura o relevancia actual del contenido.
- Comprensión de Consultas Técnicas: Los evaluadores pueden no entender consultas técnicas, lo que conduce a dificultades al evaluar la relevancia de temas especializados o de nicho.
- Evaluación de la Popularidad: Existe una dificultad inherente para los evaluadores al juzgar la popularidad entre interpretaciones de consultas competitivas o productos rivales, lo que podría afectar la precisión de sus valoraciones.
- Diversidad de Evaluadores: La falta de diversidad entre los evaluadores en algunos lugares, y el hecho de que todos son adultos, no refleja la diversidad de la base de usuarios de Google, lo que incluye a menores de edad.
- Contenido Generado por Usuarios: Los evaluadores tienden a ser severos con el contenido generado por usuarios, lo que puede llevar a subestimar su valor y relevancia, a pesar de que puede ser útil y relevante.
- Entrenamiento del Nodo de Frescura: Señalan un problema con la sintonización de modelos de frescura debido a la falta de etiquetas de entrenamiento adecuadas. Los evaluadores humanos a menudo no prestan suficiente atención al aspecto de frescura de la relevancia o carecen del contexto temporal para la consulta. Esto resulta en una subvaloración de los resultados recientes para consultas que buscan novedad. El texto también menciona que el Tangram Utility existente, basado en IS y utilizado para entrenar la Relevancia y otras curvas de puntuación, sufrió del mismo problema. Debido a la limitación de las etiquetas humanas, las curvas de clasificación del Nodo de Frescura se ajustaron manualmente en su primer lanzamiento.
Creo sinceramente que los evaluadores humanos han sido los responsables de que el «Parasite SEO» funcione tan bien, algo que por fin ha llegado a las manos de Danny Sullivan y que comparte en este tuit

Si observamos los cambios en las últimas guías de calidad, podemos ver cómo por fin han ajustado la definición de las métricas de Needs Met e incluyen un nuevo ejemplo para que los evaluadores tengan en cuenta que, aunque un resultado sea autoritario, si no contiene la información que busca el usuario, no debería evaluarse tan bien.

El nuevo lanzamiento de Notes, creo que también apunta a este motivo. Google es incapaz de saber al 100% lo que es un contenido de calidad.
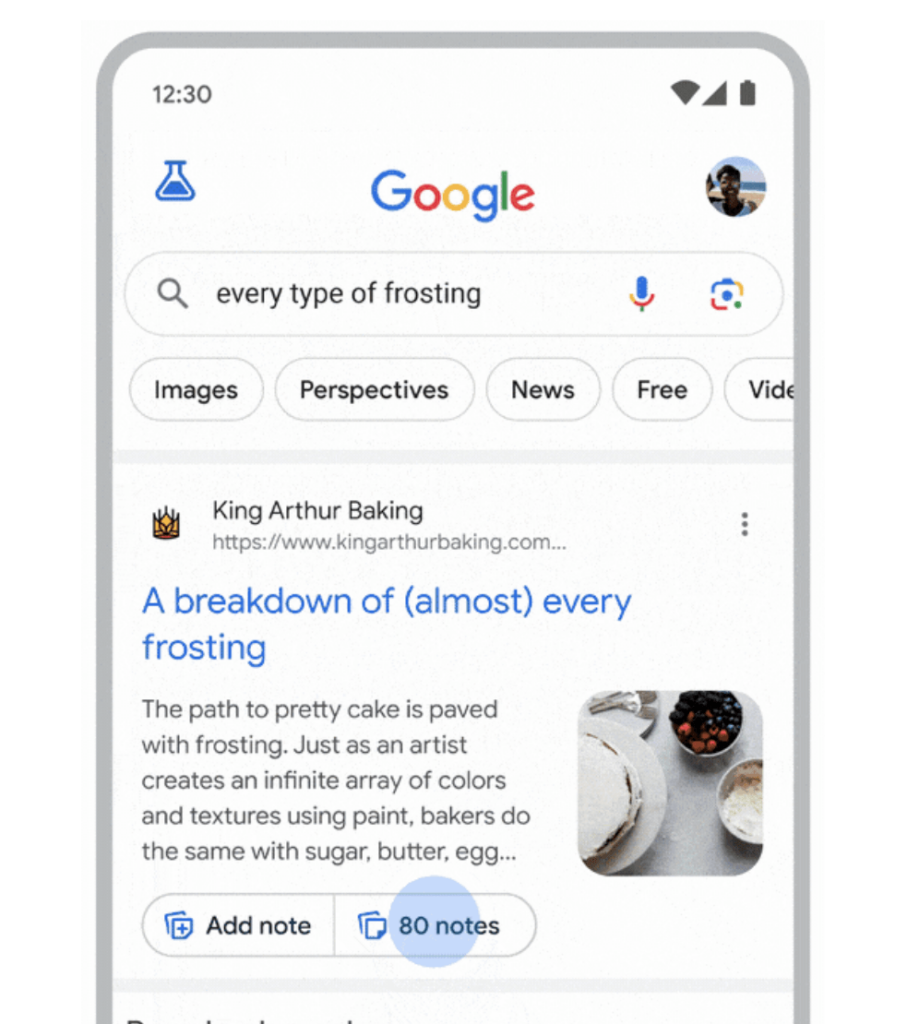
Creo que estos eventos que comento, que han ocurrido prácticamente a la vez, no son una casualidad y pronto veremos cambios.
2. PQ (Page Quality)
Aquí deduzco que hablan del Page Quality, así que es mi interpretación. Si es así, no hay nada en los documentos del juicio más allá de la mención como métrica usada. Lo único que tengo oficial que mencione el PQ son de las guías de evaluación para quality raters, que van cambiando con el tiempo. Así que sería otra tarea para evaluadores humanos.

Esta información también se le envía a los algoritmos para crear modelos. Aquí podemos ver una propuesta de ello filtrada en el «Project Veritas»:
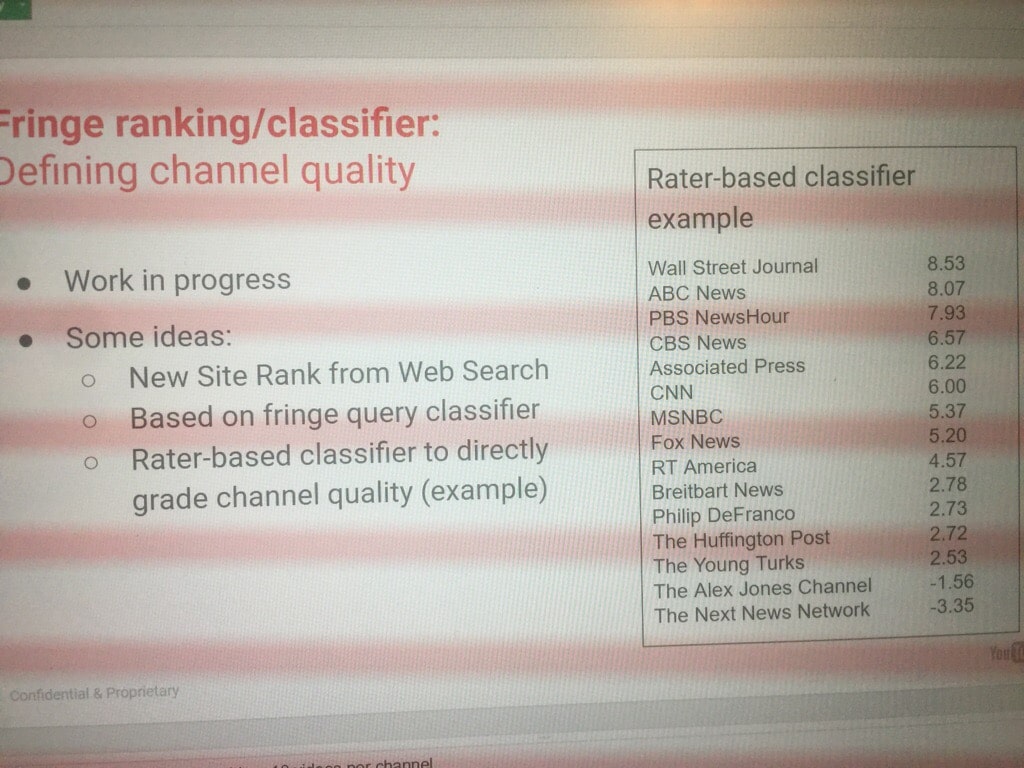
Una curiosidad aquí, según se indica en los documentos, los quality raters sólo evalúan las páginas en mobile.

3. Side-by-Side
Esto probablemente se refiere a pruebas donde dos conjuntos de resultados de búsqueda se colocan uno al lado del otro para que los evaluadores puedan comparar su calidad relativa. Esto ayuda a determinar qué conjunto de resultados es más relevante o útil para una consulta de búsqueda dada.
Si es así, recuerdo que Google tenía su propia herramienta descargable para ello, la sxse:
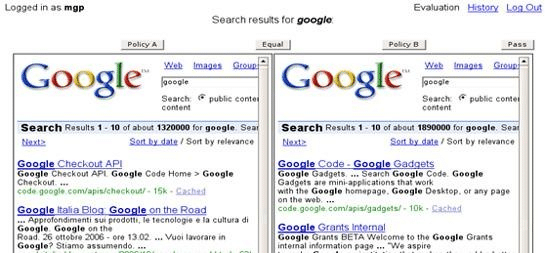
La herramienta permite a los usuarios votar por el conjunto de resultados de búsqueda que prefieren, ofreciendo así una retroalimentación directa sobre la eficacia de los diferentes ajustes o versiones de los sistemas de búsqueda.
4. Live Experiments
La información oficial publicada en How Search Works dice que Google realiza experimentos con tráfico real para probar cómo las personas interactúan con una nueva característica antes de lanzarla a todos. Activan la característica para un pequeño porcentaje de usuarios y comparan su comportamiento con un grupo de control que no tiene la característica. Las métricas detalladas sobre la interacción de los usuarios con los resultados de búsqueda incluyen:
- Clics en los resultados.
- Número de búsquedas realizadas.
- Abandono de consultas.
- Tiempo antes de hacer clic en un resultado.
Estos datos ayudan a medir si la interacción con la nueva característica es positiva y aseguran que los cambios aumentan la relevancia y utilidad de los resultados de búsqueda.
Pero en los documentos del juicio se destacan 2:

- Clics largos ponderados por posición: Esta métrica consideraría la duración de los clics y su posición en la página de resultados, lo que puede reflejar la satisfacción del usuario con los resultados que encuentran.
- Atención: Dicen que el equipo de evaluación mide la «atención» que los usuarios prestan a los resultados de búsqueda. Esto podría implicar medir el tiempo de permanencia en la página, proporcionando una idea de cuánto tiempo los usuarios están interactuando con los resultados y su contenido.
Además, en la transcripción de la comparecencia de Pandu Nayak, se explica que realizan muchos tests de algoritmos mediante interleaving en lugar de los A/B tests tradicionales. Esto les permite realizar experimentos rápidos y confiables, pudiendo así interpretar fluctuaciones en el posicionamiento.
5. Freshness
La frescura es un aspecto crucial tanto en los resultados como en las Search Features. Es esencial mostrar información relevante tan pronto como esté disponible y dejar de mostrar contenido cuando se vuelve obsoleto.
Para que los algoritmos de clasificación puedan mostrar documentos recientes en la SERP, los sistemas de indexación y servicio deben poder descubrir, indexar y servir documentos frescos con muy baja latencia. Aunque idealmente se quisiera que todo el índice sea lo más actualizado posible, hay restricciones técnicas y de costes que impiden indexar cada documento con baja latencia. El sistema de indexación prioriza documentos en rutas separadas, ofreciendo diferentes compensaciones entre latencia, coste y calidad.
Existe el riesgo de que el contenido muy fresco tenga su relevancia subestimada y, a la inversa, que un contenido con mucha evidencia de relevancia se vuelva menos relevante debido a un cambio en el significado de la consulta.

El papel del Freshness Node es agregar correcciones a las puntuaciones desactualizadas. Para consultas que buscan contenido fresco, promueve contenido fresco y degrada contenido obsoleto.
Hace no mucho se filtró que Google Caffeine ya no existe (también conocido como Percolator-based indexing system). Aunque internamente se sigue utilizando el nombre anterior, en realidad lo que hay ahora es un sistema completamente nuevo. El nuevo «caffeine» es en realidad un conjunto de microservicios que se comunican entre sí. Implica que diferentes partes del sistema de indexación funcionan como servicios independientes pero interconectados, cada uno realizando una función específica. Esta estructura puede ofrecer mayor flexibilidad, escalabilidad y facilidad para realizar actualizaciones y mejoras.
Según interpreto parte de estos microservicios serían Tangram y Glue, en concreto el Freshness Node y el Instant Glue. Lo digo porque en otro documento filtrado del «Project Veritas» encontré que había una propuesta del 2016 para hacer o incorporar un «Instant Navboost» como señal de Freshness, así como las visitas de Chrome.
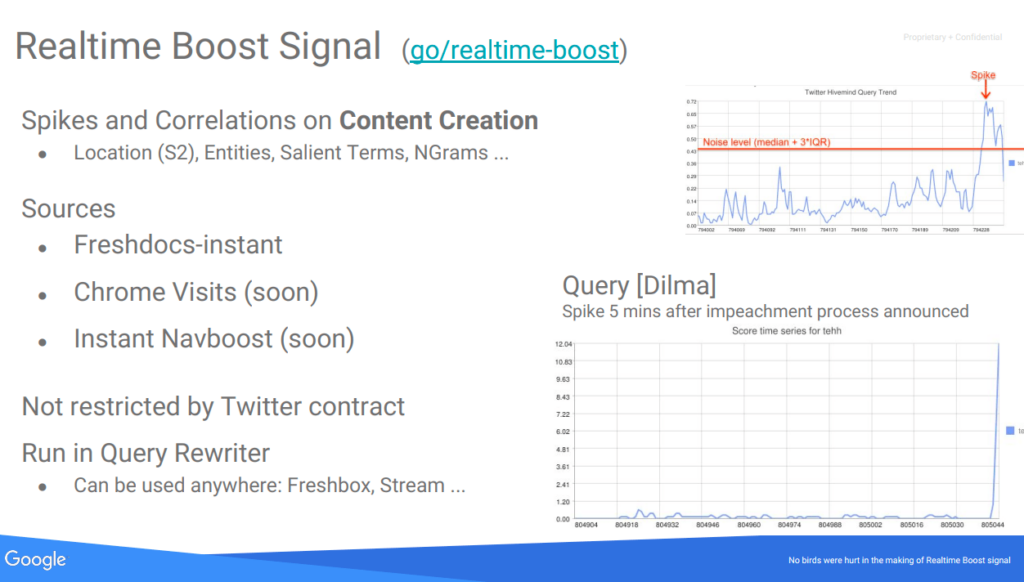
De momento ya incorporaban «Freshdocs-instant» (extraído de una lista de pubsub llamada freshdocs-instant-docs pubsub, donde cogían las noticas publicadas por esos medios en 1 minuto desde su publicación) y picos de búsquedas y correlaciones en generación de contenido:
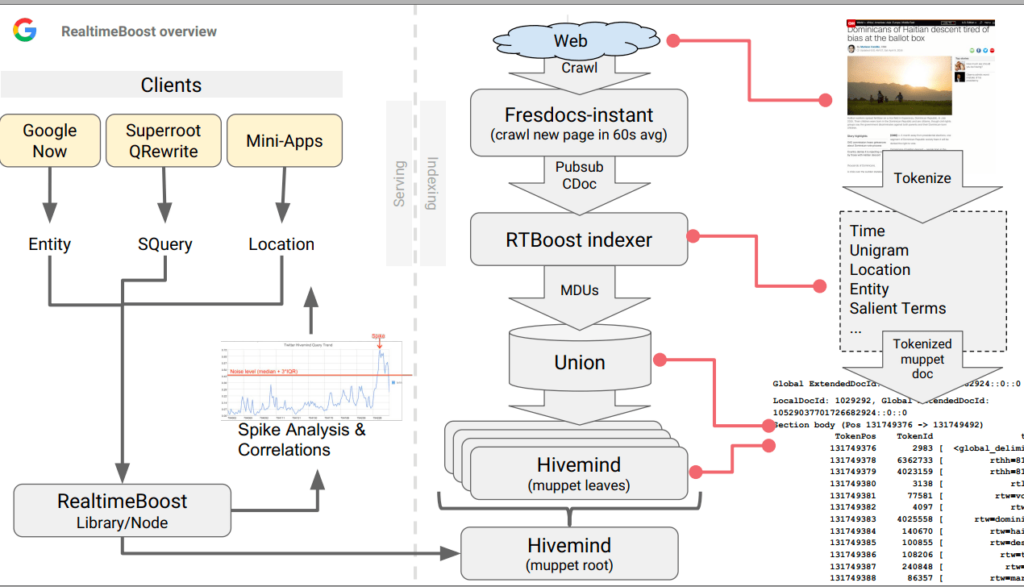
Dentro de las métricas de Freshness, tenemos varias que se detectan gracias al análisis de Correlated Ngrams y Correlated Salient Terms:
- Correlated NGrams: Son grupos de palabras que aparecen juntas en un patrón estadísticamente significativo. La correlación puede aumentar repentinamente durante un evento o tema de tendencia, indicando un pico.
- Correlated Salient Terms: Términos destacados que están estrechamente asociados con un tema o evento y cuya frecuencia de aparición se incrementa en los documentos durante un período corto, sugiriendo un pico de interés o actividad relacionada.
Una vez detectados los spikes, se podrían estar usando las siguientes métricas de Freshness:
- Unigrams (RTW): Para cada documento, se utilizan el título, los textos de anclaje y los primeros 400 caracteres del texto principal. Estos son divididos en unigramas relevantes para la detección de tendencias y son añadidos al índice de Hivemind. El texto principal generalmente contiene el contenido principal del artículo, excluyendo los elementos repetitivos o comunes (boilerplate).
- Half Hours since epoch (TEHH): Es una medida del tiempo expresada como el número de medias horas transcurridas desde la fecha de inicio del tiempo Unix. Ayuda a establecer cuándo ocurrió algo con una precisión de media hora.
- Knowledge Graph Entities (RTKG): Referencias a objetos del Knowledge Graph de Google, que es una base de datos de entidades reales (personas, lugares, cosas) y sus interconexiones. Ayuda a enriquecer la búsqueda con entendimiento semántico y contexto.
- S2 Cells (S2): Son divisiones geométricas de la superficie de la Tierra utilizadas para la indexación geográfica en mapas. Facilitan la asociación de contenido web con ubicaciones geográficas precisas.
- Freshbox Article Score (RTF): Esta métrica evalúa la frescura y relevancia de un artículo. Además, ayuda a identificar y potencialmente descartar contenido de baja calidad o spam, asegurando que los artículos de noticias promovidos en los resultados de búsqueda sean de alta calidad y relevantes.
- Document NSR (RTN): Podría referiste a Relevancia de Noticia del Documento y parece ser una métrica que determina cuán relevante y confiable es un documento en relación con las historias actuales o los eventos de tendencia. Esta métrica también puede ayudar a filtrar contenido de baja calidad o spam, garantizando que los documentos que se indexan y se resaltan son de alta calidad y significativos para las búsquedas en tiempo real.
- Geographical Dimensions: Características que definen la ubicación geográfica de un evento o tema mencionado en el documento. Estos pueden incluir coordenadas, nombres de lugares, o identificadores como las celdas S2.
Si trabajas en medios, esta información es clave y siempre la incluyo en mis formaciones a redactores digitales.
La importancia de los clics
En este punto nos vamos a centrar en la presentación interna de Google compartida en un email, llamada Unified Click Prediction, en la presentación Google is Magical, en la Search All Hands, en un email interno de Danny Sullivan y en los documentos del leak «Project Veritas».
En todo este proceso vemos la importancia de los clics en todo momento y es que Google se apoya fundamentalmente en el análisis de los clics para entender el comportamiento/necesidades de los usuarios. Mejor dicho, Google necesita nuestros datos. Curiosamente, de los clics es es una de las cosas que Google tenía prohibido hablar.
Antes de empezar, es importante destacar que los principales documentos discutidos sobre los clics son anteriores a 2016, y Google ha experimentado cambios significativos desde entonces. A pesar de esta evolución, la base de su enfoque sigue siendo el análisis del comportamiento del usuario, considerándolos señales de calidad. ¿Recordáis la patente donde explican el modelo CAS?

Cada búsqueda y clic proporcionado por los usuarios contribuye al aprendizaje y la mejora continua de Google. Este ciclo de retroalimentación permite a Google adaptarse y «aprender» sobre las preferencias y comportamientos de búsqueda, manteniendo la ilusión de que comprende las necesidades del usuario.
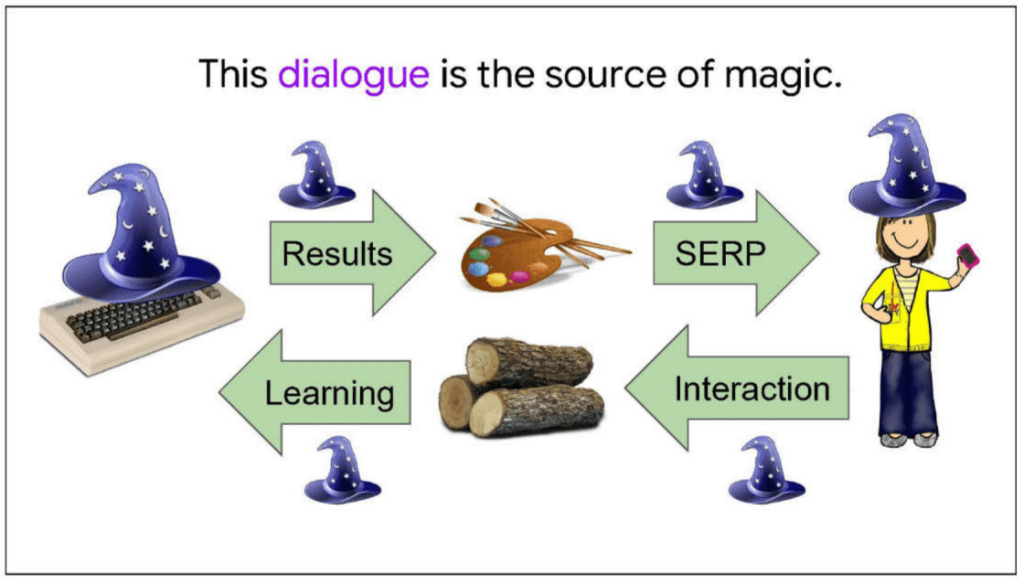
Diariamente, Google analiza más de mil millones de nuevos comportamientos dentro de un sistema diseñado para ajustar y superar continuamente las predicciones futuras basándose en datos anteriores. Por lo menos, hasta 2016, esto superaba la capacidad de los sistemas de IA de aquella época, por lo que requiere el trabajo manual que vimos anteriormente y ajustes de RankLab.
RankLab entiendo que es un laboratorio que testea diferentes pesos en señales y factores de ranking, así como su impacto posterior. Podrían ser también los encargados de la herramienta interna «Twiddler» (algo que también leí hace años del «Project Veritas»), con el propósito de modificar los IR-scores de ciertos resultados a mano, o lo que es lo mismo, para poder hacer todo lo siguiente:
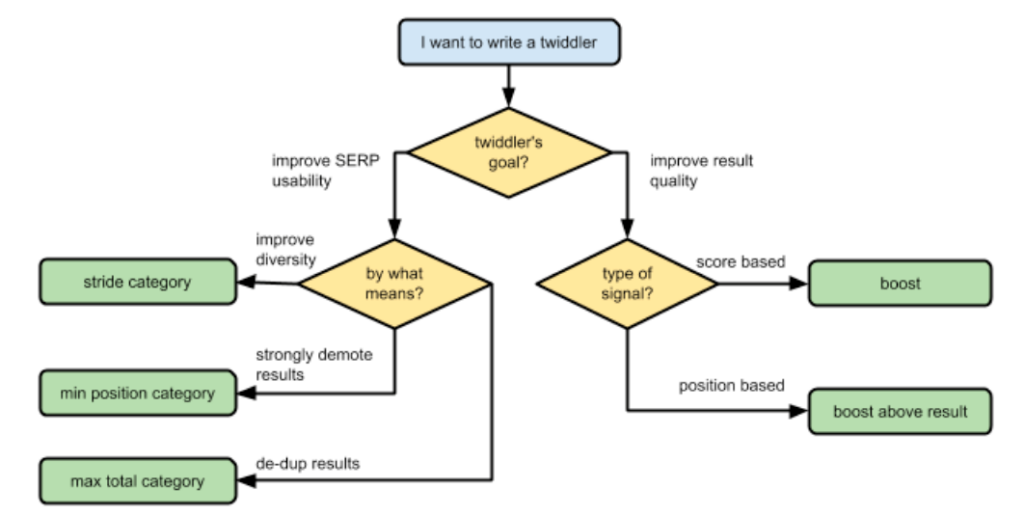
Después de este pequeño paréntesis, sigo.
Mientras que los ratings de evaluadores humanos ofrecen una visión básica, los clics proporcionan un panorama mucho más detallado del comportamiento de búsqueda.


Esto revela patrones complejos y permite aprender efectos de segundo y tercer orden.
- Los efectos de 2do orden reflejan patrones emergentes: Si la mayoría prefiere y elige artículos detallados sobre listas rápidas, Google lo detecta. Con el tiempo, ajusta sus algoritmos para priorizar esos artículos más detallados en las búsquedas relacionadas.
- Los de 3er orden son cambios más amplios y a largo plazo: Si las tendencias de clic favorecen guías exhaustivas, los creadores de contenido se adaptan. Empezarán a producir más artículos detallados y menos listas, cambiando así la naturaleza del contenido disponible en la web.
En los documentos analizados, se presenta un caso específico donde se mejoró la relevancia de los resultados de búsqueda gracias al análisis de los clics. Google identificó una discrepancia en la preferencia de los usuarios, basada en los clics, hacia unos pocos documentos que resultaron ser relevantes, a pesar de estar rodeados por un conjunto de 15.000 documentos considerados irrelevantes. Este descubrimiento destaca la importancia de los clics de los usuarios como una herramienta valiosa para discernir la relevancia oculta en grandes volúmenes de datos.

Google «entrena con el pasado para predecir el futuro» para evitar el sobreajustes. Mediante evaluaciones constantes y la actualización de datos, los modelos se mantienen actualizados y relevantes. Un aspecto clave de esta estrategia es la personalización por localización, asegurando que los resultados sean pertinentes para diferentes usuarios en distintas regiones.
Sobre la personalización, en un documento más reciente Google asegura que es limitada y rara vez cambia rankings. También comentan que nunca ocurre en «Top Stories». Las veces que se usa es para entender mejor lo que se busca, por ejemplo, usando el contexto de búsquedas anteriores y también para hacer sugerencias predictivas con el autocompletar. Mencionan que podrían elevar ligeramente algún proveedor de video que el usuario usa frecuentemente, pero todos verían básicamente los mismos resultados. Según ellos, la consulta es más importante para ellos consulta es más importante que los datos del usuario.
No hay que olvidar que este enfoque de clics enfrenta desafíos, especialmente con contenido nuevo o poco frecuente. La evaluación de la calidad de los resultados de búsqueda es un proceso complejo que va más allá de sólo contar clics. Aunque este artículo que escribí tiene varios años, creo que puede servir para profundizar en esto.
Arquitectura de Google
Después de la anterior, esta es la imagen mental que me he hecho de cómo podríamos colocar todos estos elementos en un diagrama. Es muy probable que hayan algunos componentes de la arquitectura de Google que no estén en ciertos lugares o no se relacionen así, pero creo que como aproximación es más que suficiente.
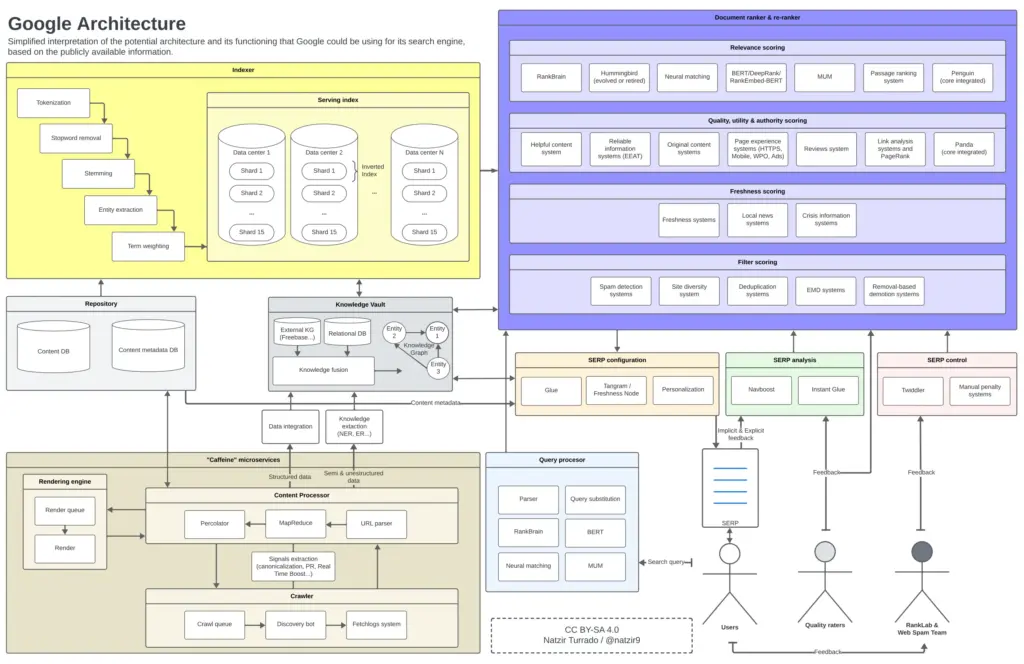 Posible funcionamiento y arquitectura de Google. Clica para hacer la imagen más grande.
Posible funcionamiento y arquitectura de Google. Clica para hacer la imagen más grande.
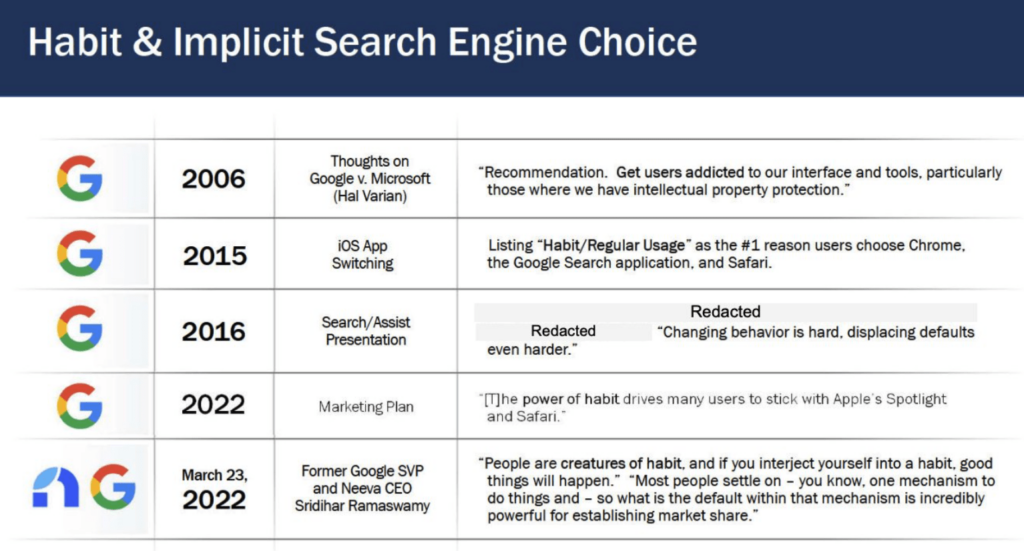
Google y Chrome, la lucha por ser el buscador y navegador «default»
En este último apartado nos vamos a centrar en la presentación del testigo experto, Antonio Rangel, Economista Conductual y Profesor en Caltech, sobre el uso de opciones predeterminadas para influir en las elecciones de los usuarios, en la presentación interna revelada «On Strategic Value of Default Home Page to Google» y en las afirmaciones de Jim Kolotouros, VP en Google, en un mail interno.
Como se revela Jim Kolotouros en comunicaciones internas, Chrome no es sólo un navegador, sino una pieza clave en el rompecabezas del dominio de búsqueda de Google.
Entre los datos que recoge Google se incluyen patrones de búsqueda, clics en resultados de búsqueda, e interacciones con diferentes sitios web, lo cual es crucial para refinar los algoritmos de Google y mejorar la precisión de los resultados de búsqueda y la eficacia de la publicidad dirigida.
Para Antonio Rangel, la supremacía de Chrome en el mercado trasciende su popularidad. Funciona como una puerta de entrada al ecosistema de Google, influenciando la forma en que los usuarios acceden a la información y a los servicios en línea. La integración de Chrome con Google Search, siendo este el motor de búsqueda predeterminado, otorga a Google una ventaja significativa en el control del flujo de información y la publicidad digital.

A pesar de la popularidad de Google, Bing no es un motor de búsqueda inferior. Sin embargo, muchos usuarios prefieren Google debido a la conveniencia de su configuración predeterminada y los sesgos cognitivos asociados. En dispositivos móviles, los efectos de los motores de búsqueda predeterminados son más fuertes debido a la fricción involucrada en cambiarlos; se requieren hasta 12 clics para modificar el motor de búsqueda predeterminado.
Esta preferencia por defecto también influye en las decisiones de privacidad de los consumidores. Los ajustes de privacidad predeterminados de Google presentan una fricción significativa para aquellos que prefieren una recolección de datos más limitada. Cambiar la opción predeterminada requiere conciencia sobre las alternativas disponibles, aprendizaje de los pasos necesarios para el cambio y su implementación, lo que representa una fricción considerable. Además, los sesgos conductuales como el estatus quo y la aversión a la pérdida hacen que los usuarios se inclinen por mantener las opciones predeterminadas de Google. Todo esto lo explico mejor aquí.
El testimonio de Antonio Rangel, resuena de forma directa en las revelaciones del análisis interno de Google. El documento revela que la configuración de la página de inicio en los navegadores tiene un impacto significativo en la cuota de mercado de los motores de búsqueda y en el comportamiento del usuario. Específicamente, un alto porcentaje de usuarios que tienen a Google como su página de inicio predeterminada realizan un 50% más búsquedas en Google que aquellos que no la tienen.
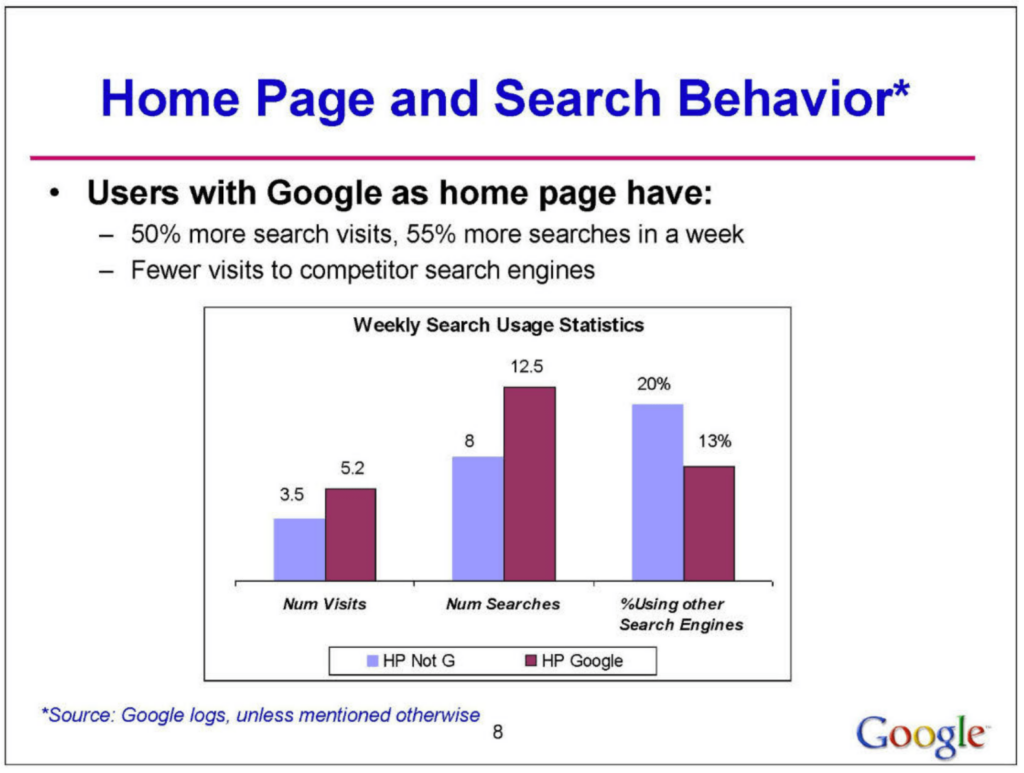
Esto sugiere una fuerte correlación entre la página de inicio predeterminada y la preferencia del motor de búsqueda. Además, la influencia de esta configuración varía regionalmente, siendo más pronunciada en Europa, Medio Oriente, África y América Latina, y menos en Asia-Pacífico y América del Norte. El análisis también muestra que Google es menos vulnerable a los cambios en la configuración de la página de inicio en comparación con competidores como Yahoo y MSN, que podrían sufrir pérdidas significativas si pierden esta configuración.
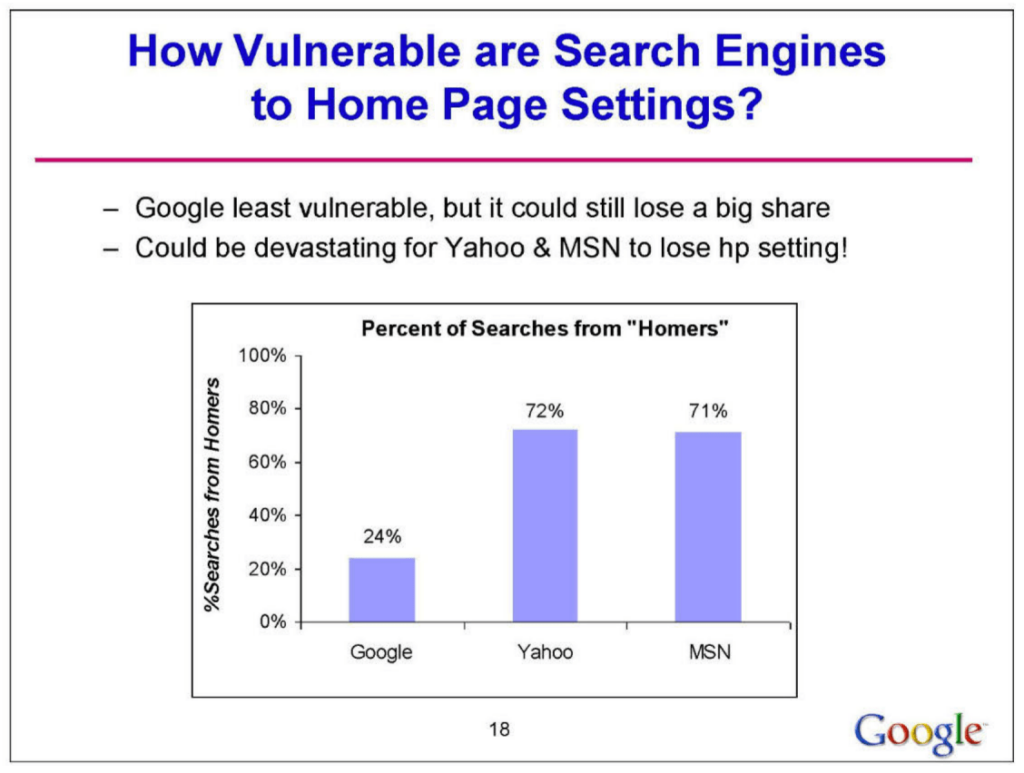
La configuración de la página de inicio se identifica como una herramienta estratégica clave para Google, no sólo para mantener su cuota de mercado, sino también como una posible vulnerabilidad para sus competidores. Además, se destaca que la mayoría de los usuarios no eligen activamente un motor de búsqueda, sino que se inclinan por el acceso predeterminado proporcionado por la configuración de su página de inicio. En términos económicos, se estima un valor de vida útil incremental de aproximadamente $3 por usuario para Google al ser configurado como la página de inicio.

Conclusión
Después de explorar los algoritmos y el funcionamiento interno de Google, hemos visto el significativo papel que juegan los clics de los usuarios y los evaluadores humanos en ranking de los resultados de búsqueda.
Los clics, como indicadores directos de las preferencias de los usuarios, son esenciales para que Google ajuste y mejore continuamente la relevancia y precisión de sus respuestas. Aunque a veces puedan querer lo contrario cuando los números no les salen…
Además, los evaluadores humanos aportan una capa crucial de evaluación y comprensión que, incluso en la era de la inteligencia artificial, sigue siendo indispensable. Personalmente estoy muy sorprendido en este punto, sabía que los evaluadores eran importantes, pero no tanto.
Estas dos inputs combinados, la retroalimentación automática a través de los clics y la supervisión humana, permiten a Google no sólo entender mejor las consultas de búsqueda, sino también adaptarse a las tendencias cambiantes y las necesidades de información. A medida que avance la IA, será interesante observar cómo Google continúa equilibrando estos elementos para mejorar y personalizar la experiencia de búsqueda en un ecosistema en constante cambio y con foco en la privacidad.
Por otro lado, Chrome es mucho más que un navegador, es el componente crítico de su dominio digital. Su sinergia con Google Search y su implementación por defecto en muchos ámbitos, impacta en las dinámicas del mercado y en todo el entorno digital. Veremos como termina el juicio antimonopolio, pero llevan más de 10 años sin pagar unos 10.000 millones de € en multas por abuso de posición dominante.