Es probable que Google esté empezando a detectar y a tratar mejor el contenido duplicado que se produce por error dentro de una web y que afecta al SEO de la misma. Me refiero al contenido que suele aparece en webs grandes con filtros, categorías y demás. Porque para el que se produce para copar más resultados alrededor de una query y de baja calidad ya queda bien atado con Google Panda y la detección de n-gramas como podemos ver en esta patente.
Antecedentes
Os pongo en antecedentes para que veáis a qué me refiero. Justo el día que me encuentro con este nuevo aviso de Google Analytics:
Miguel Pascual me comenta (a mi y a otros) un caso extraño de SEO que se ha encontrado con un e-commerce hecho a medida y con bastante antigüedad. Los productos de este e-commerce tienen graves problemas de duplicados por mala definición de arquitectura y sin control de la misma mediante robots.txt, meta robots o canonical:
- /cat-1/subcat-1/prodID-12
- /cat-1/subcat-2/prodID-12
- /cat-2/subcat-1/prodID-12
- …
Esto provoca que un producto esté duplicado y que Google lo identifique como tal (hasta 8 veces en el producto del siguiente ejemplo):
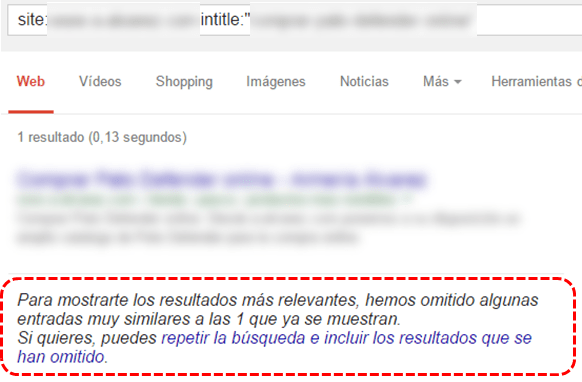
Si miramos la caché de todas las páginas duplicadas vemos que comparten la misma página en caché aunque las otras también estén en su índice. Curiosamente no muestra la caché de la página que debería ser la canónica, sino la que recibe más enlaces internos:

Ya sabemos que si existe un canonical en una página Google muestra la versión cacheada de la original, pero como he comentado al principio no existe canonical en ninguna página. Tampoco está implementado el canonical mediante HTTP y no han hecho redirecciones.
Toca SEO-investigar 🙂
Con todo esto me pongo a investigar y me encuentro que a Google en 2009 le concedieron la patente de un sistema de detección de contenido duplicado. En la patente se habla de varios sistemas para detectar contenido duplicado y de cómo identificar la mejor dirección (canónica) que representa al conjunto:
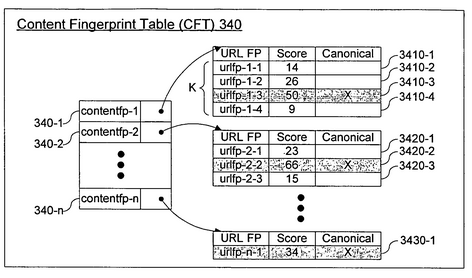
En la patente se menciona que a la hora de escoger el documento canónico no lo hace necesariamente por la que tiene más «Page Rank u otra métrica query-independiente». Con lo que no tiene porqué mostrar la que más enlaces internos o externos recibe (como antes he mencionado que ocurría en el ejemplo), pero tampoco lo excluye. Uno de los indicadores posiblemente usados según la patente sería el anchor text y el texto que se encuentra alrededor del enlace (¡semántica!).
También se comenta las razones de porqué es necesario para un buscador identificar este tipo de documentos idénticos (y por consecuencia al SEO):
For example, on the back end of a search engine, if duplicate copies of a same document are treated as different documents not related with one another in terms of their content, this would cause the search engine to waste resources, such as disk space, memory, and/or network bandwidth, in order to process and manage the duplicate documents. On the front end, retaining duplicate documents would cause the search engine to have to search through large indices and to use more processing power to process queries. Also, a user’s experience may suffer if diverse content that should be included in the search results is crowded out by duplicate documents.
Siguiendo con la investigación me encuentro que lo que se menciona en esta patente aparece incluso en el soporte para webmasters de Google:
Cuando Google detecta contenido duplicado, como pueden ser las páginas del ejemplo anterior, un algoritmo de Google reúne las URL duplicadas en una agrupación y selecciona la URL que el algoritmo cree que es la mejor para representar a la agrupación en los resultados de búsqueda (por ejemplo, Google podría seleccionar la URL con más contenido). A continuación, Google intenta consolidar lo que sabe acerca de las URL de la agrupación, como la popularidad de enlaces, en la URL representante para, en última instancia, mejorar la precisión de clasificación de la página y los resultados de búsqueda de Google.
Conclusión
Google hasta ahora no mostraba otra canónica si no se lo indicábamos nosotros con instrucciones SEO. Así que es muy probable que Google esté empezando a agrupar contenidos en clústers y a escoger mejor la página canónica sin tener que indicárselo nosotros.
Mi opinión es que no es nada recomendable permitir a Google que escoja la canónica (en el ejemplo hemos visto cómo lo hacía mal) y además si le dejamos hacer le haremos consumir recursos (algo que odian los buscadores). Entonces que exista esta nueva forma de detectar el contenido duplicado no quiere decir que no tengamos que seguir haciendo nuestro trabajo, y sobretodo sabiendo que el canonical es una sugerencia y no una directiva ¿qué caso le hará ahora? ¡Ojito con Google Panda!