Los algoritmos de los buscadores evolucionan a la vez que lo hacen las necesidades de las personas. Al principio la única manera que había de organizar la información era mediante directorios, ¿quién no se acuerda cómo era buscar en Ask y Yahoo?
La revolución de los buscadores vino cuando Sergey Brin y Larry Page fueron capaces de crear un algoritmo de IR que ordenaba las páginas por el número enlaces que recibían y te las ofrecía en una lista de 10 resultados. Gracias a este desarrollo del PageRank nació Google.
Poco a poco los buscadores fueron incorporando este sistema y añadiendo otros algoritmos de IR en paralelo (o reescribiendo directamente el core). Por ejemplo algoritmos centrados en las páginas y sus relaciones (como el HITS, TrustRank, Okapi 25, Tf-idf…), evolucionando hacia el contenido y calidad (los de NLP; LSI, LDA, Spamdexing…) para llegar a las entidades (con el AuthorRank, el SocialGraph…).
Hasta ahora vivimos en un mundo de 10 links azules donde, para encontrar la información que buscas, tienes que leer los snippets de texto y con un poco de suerte encuentras la respuesta a tus preguntas. Durante mucho tiempo esto ha sido (y sigue siendo) una buena solución, pero no es suficiente para el usuario cuyas necesidades evolucionan (búsquedas más cortas en móvil, más búsquedas locales, búsquedas por voz…).
El problema sobretodo reside en que es muy difícil para un buscador capturar la intención real del usuario en una búsqueda y ofrecer un resultado óptimo. Y este problema es todavía más complejo de resolver por los algoritmos cuando hablamos de búsquedas de nombre de entidades y la intención que hay detrás ellas.
¿Qué es una entidad?
Muy sencillo, una entidad puede ser una persona, un lugar o una cosa. Y estas entidades se pueden asociar a fechas, acciones u otras entidades.
A día de hoy, una porción muy significativa de las búsquedas son nombres de entidades (20-30% según un estudio de Microsoft) y una porción aún más grande de las búsquedas son las que contienen nombres de entidades (71% según el mismo estudio). Como he mencionado antes, es complejo para un buscador detectar la intención que hay detrás de la búsqueda de una entidad. A continuación podemos un ejemplo de cuáles son las intenciones más comunes detrás de diferentes tipos entidades:
Intenciones más comunes para ciertos tipos de entidades
Incluso para búsquedas que contienen nombres de entidades cuya intención debería ser más clara, los usuarios escogen diferentes tipos de resultados. En la imagen siguiente podemos ver un ejemplo real de las intenciones que hay detrás de 4 tipos distintos de búsquedas que contienen la entidad «Seattle»:
Porcentaje de usuarios escogiendo diferentes resultados para cuatro búsquedas distintas que contienen la palabra «Seattle»
Otro problema que nos encontramos con las entidades pueden ser citadas por más de un nombre, o un mismo nombre puede ser referido a entidades distintas. Por ejemplo la entidad «Barcelona» puede ser referida a la ciudad española, al equipo de fútbol y en menor medida a la ciudad de Venezuela. También la Barcelona española es comúnmente conocida por «ciudad condal».
Os dejo un vídeo de los creadores de la Metaweb (Freebase) donde lo explican a la perfección:
Las entidades y los buscadores
Los principales buscadores están continuamente desarrollando y testeando diferentes soluciones para satisfacer las necesidades del usuario cuando hace una búsqueda con el nombre de una entidad. Por ejemplo, nada más entrar en Yahoo, nos encontramos con un apartado que nos muestra «lo más buscado», donde vemos curiosamente que la mayoría de search queries son nombres de entidades.
Lo más buscado en Yahoo
En Google para resolver estas necesidades se usa el Knowledge Graph (KG o copia de Wikipedia para los amigos). Podemos ver para la query «Barcelona» que la principal tarea que viene a realizar el usuario es más la futbolística que cultural/turística, pero no por ello no se incluye la segunda por su peso:
Google Knowledge Graph para la búsqueda «Barcelona»
Bing también tiene su propio KG, pero si no está seguro no te lo muestra y te ofrece en el lateral queries relacionadas antes de mostrártelo.
Entonces para que los buscadores puedan ofrecer las respuestas específicas más populares o una ayuda para que el usuario pueda completar su tarea inicial, no sólo tienen que capturar la intención, sino también las relaciones que hay entre las entidades. Para ello hace falta que esa información se extraiga, se relacione y se almacene en algún lugar. Y la mejor manera de lograrlo eficientemente es mediante grafos.
Del Knowledge Graph al Knowledge Vault
Los grafos que existen a día de hoy y de los cuales se nutren los buscadores son Freebase, DBpedia (extraen las entidades la Wikipedia), Facebook Entity Graph, YAGO, OpenIE y muchos otros genéricos y específicos (IMDb…). No solamente usan uno, Google por ejemplo hace un maching de toda la información disponible estructurada, semi-estructurada y sin estructurar en un Knowledge Vault para reducir el número de errores en el resultado ofrecido (porque los repositorios no son del todo exactos y tienen duplicados y errores).
Crowdsourcing para crear el Knowledge Vault
En Freebase existen 637 millones de resultados no redundantes. Con esto y otras fuentes Google ha hecho un Knowldege Vault de 302 millones de resultados con una posibilidad de ser ciertos mayor al 0.9 (aproximadamente el 35% de estos son de Freebase).
Comparación de repositorios de conocimiento
Este crowdsourcing de fuentes y diferentes métodos de extracción hace que la probabilidad de dar una buena respuesta aumente (AUC score del 0.927):
Aumento del AUC Score al incorporar diferentes extractores y fusionarlos
Para crear el Knowledge Vault, los extractores que se usan para montar las tripletas de información y mejorar la probabilidad de respuesta son:
Tablas (TBL): 570M de tablas que contienen información relacional.
Anotaciones (ANO): extraídos de las ontologías añadidas por nosotros en la página.
Texto (TXT): extraídos mediante métodos de NLP.
HTML trees (DOM): extraídos directamente de la página.
Sistemas de estracción usados en el Knowledge Vault
Tutorial on Constructing and Mining Web-scale Knowledge Graphs, New York, August 24, 2014
Stanford Seminar – Knowledge Vault and Knowlege-Based Trust
La implicación en el SEO
El trabajo de los SEO va a seguir siendo el mismo de siempre, dar mascada la información a Google. Nuestro trabajo consiste en hacer las páginas más relevantes y estructurar los datos para que los buscadores entiendan nuestro sitio. Por ejemplo para Google estructuramos con microformatos o microdatos (aunque Google recomiende microdata, a me funcionan mejor los microformatos) y para Facebook con RDFa y OpenGraph. Pero también existe el RDFa lite y el JSON-LD.
Desambiguar entidades
Como el trabajo de los buscadores es el de extraer las entidades que existen de forma implícita (análisis del texto) y explícita (datos estructurados) mediante los «Data Janitors» (o como dice Alberto Talegón, los «Juanitos»), no sólo basta con trabajar los datos estructurados cuando hablamos de entidades y de optimización semántica. Uno de los principales problemas de los Data Janitors es que tienen problemas para desambiguar las entidades, así que nosotros debemos de hacer ese trabajo por ellos. Yo llevo un tiempo haciendo este trabajo de desambiguación de entidades y los resultados son increíbles.
Usar los grafos del conocimiento
Ya que sabemos que los buscadores usan los grafos para ofrecer mejores resultados, podemos usarlos para incluir nuestra información si no la tienen ya. Google en 2010 compró Freebase, así que si no estás corre a subir tu información, tu empresa, tus productos y conectarla con tu grafo social. Y si ya estás, revisa de qué forma apareces y edita la información incorrecta y añade toda la nueva que puedas (nota: si Freebase ha extraído la información de otra fuente como la Wikipedia no podrás editar Freebase, tendrás que editar la Wikipedia). No nos olvidemos de Google Plus que no deja de ser el Freebase de personas y empresas de Google, así que en este aspecto sigue siendo útil.
Se podría decir que si estás en en estos grafos de conocimiento ya formas parte del algoritmo y esto tiene mucho más sentido con la llegada del Hummingbird. Si no existes en el Knowldege Vault entonces no existes como entidad y eres irrelevante para un buscador cada vez más semántico.
Estructurar los datos
A nivel de marcado la afectación en SEO es directa en imágenes y vídeos, en ecommerce, en News con la autoría, resultados locales, personalización (social graph). Y lo que todo el mundo conoce ya, el marcado también es usado por Google en la SERP mediante Rich Snippets, afectando a la visibilidad y al CTR de tus resultados. Cuando eres detectado como una entidad esto afecta directamente al brand awarness gracias a la visibilidad extra en el KG.
Pero el SEO no es sólo en Google, estructurar los datos puede ser útil para buscadores de voz como SIRI, EVI, Cortana, buscadores de mapas y sistemas de navegación, y otros tipos de buscadores que se basan en entidades. Como veis, las entidades están en prácticamente todo y cada vez lo van a estar más a medida que la semántica avanza.
Centrarse aún más en el usuario
También hay que hacer especial hincapié en el usuariocomo expliqué en el clinic SEO y es que yo no contemplo el SEO sin hacer un mapeado de las queries (entidad/keyword + intención) con los contenidos. Sobre todo recomiendo que en el keyword research se haga un user research con tareas de búsqueda específicas sobre el propio buscador para entender mejor las necesidades de los usuarios. Las keywords no mueren con las entidades, siguen siendo necesarias.
Podríamos resumir el trabajo del SEO en el campo semántico de la búsqueda en 5 pasos:
Encontrar las queries que resuelven las necesidades de información del usuario.
Mapear las entidades y las intenciones con nuestros contenidos.
Añadir estas entidades de forma visible en la página (implícitas) evitando ambiguaciones.
Añadir a estas entidades el marcado semántico (explícitas).
Añadir las entidades a los repositorios si no existen y corregir las incorrectas.
Herramientas para ver entidades en una web
Cómo ver entidades explícitas
Para ver los datos estructurados añadidos en los sitios podemos usar estos plugins gratuitos para Chrome:
Yo os recomiendo usar todas las que podáis porque cada una utiliza un repositorio distinto y depende de lo bien limpia que esté la información dará mejores o peores resultados. También algunas son mejores que otras según el idioma.
Si queremos hacer cosas más potentes con sus APIs habrá que pagar (no está demás pagar por usar las cosas :P)
Auditoría de entidades implícitas
Si yo me quiero posicionar sobre «SEO y HTTPS» y no aparecen estas entidades y sus relacionadas en el artículo, ese artículo no es semánticamente relevante. A continuación podemos ver un ejemplo de las entidades de mi anterior post sobre SEO y HTTPS usando AlchemyAPI:
Entidades del artículo SEO, HTTPS y la desinformación
Y luego podemos hacer uso de KwMap (edición: ya no existe esta herramienta) para encontrar entidades y keywords relacionadas. Para «HTTPS» la herramienta KwMap me muestra lo siguiente que puedo usar para enriquecer el artículo:
Keyword Map para «HTTPS»
Mi consejo es que no sólo os quedéis con las cercanas, hacer el mismo ejercicio con las de alrededor para encontrar nuevas relacionadas. Puesto que es así como funcionan los Data Janitors a la hora de clasificar la información. Por ejemplo, con «HTTPS» tengo cercana «SSL» y para «SSL» me salen «certificados SSL» que no aparecían al principio.
Otra cosa que podemos hacer para revisar las entidades (que me ha recordado mi amigo y socio Daniel Pinillos) es mirar las palabras clave de contenido dentro de Google Webmaster Tools y, si ahí no aparecen las entidades y sus relacionadas con tu actividad, mal vamos. Aquí podemos ver un ejemplo de lo nada relevante que es una página de formación a distancia:
Entidades en Google Webmaster Tools
Patentes de los principales buscadores sobre entidades
Ya para acabar, y para aquellos que queráis profundizar, os dejo una lista de algunas patentes sobre entidades donde se puede aprender mucho. Yo personalmente me he leído varias y es como desnudar al buscador. Y sobre todo os recomiendo el blog de Bill Slawski sobre patentes. Porque si no sabes como funcionan los buscadores no eres SEO.
Cuando un buscador necesita encontrar información, puede intentar entenderte de dos maneras, o interpretando el significado abstracto de lo que pides o buscando las palabras exactas que has utilizado. Ambos enfoques son potentes pero incompletos por sí solos. En este artículo veremos qué es la búsqueda híbrida y las técnicas que los buscadores como Google […]
En este artículo te voy a dar una serie de recursos imprescindibles de SEO semántico muy necesarios si te dedicas al SEO y quieres evolucionar a la vez que lo hacen los buscadores hacia la web semántica. Espero que os resulten útiles y que por lo menos quede claro que el seo semántico es mucho más que estructurar los […]
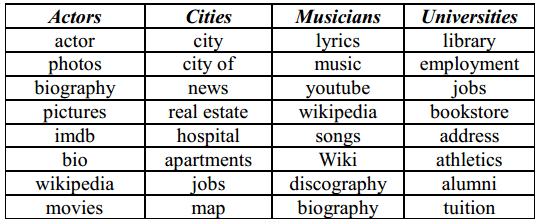 Intenciones más comunes para ciertos tipos de entidades
Intenciones más comunes para ciertos tipos de entidades Porcentaje de usuarios escogiendo diferentes resultados para cuatro búsquedas distintas que contienen la palabra «Seattle»
Porcentaje de usuarios escogiendo diferentes resultados para cuatro búsquedas distintas que contienen la palabra «Seattle»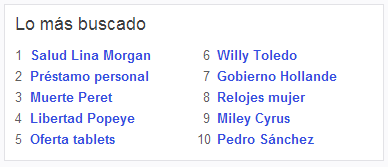 Lo más buscado en Yahoo
Lo más buscado en Yahoo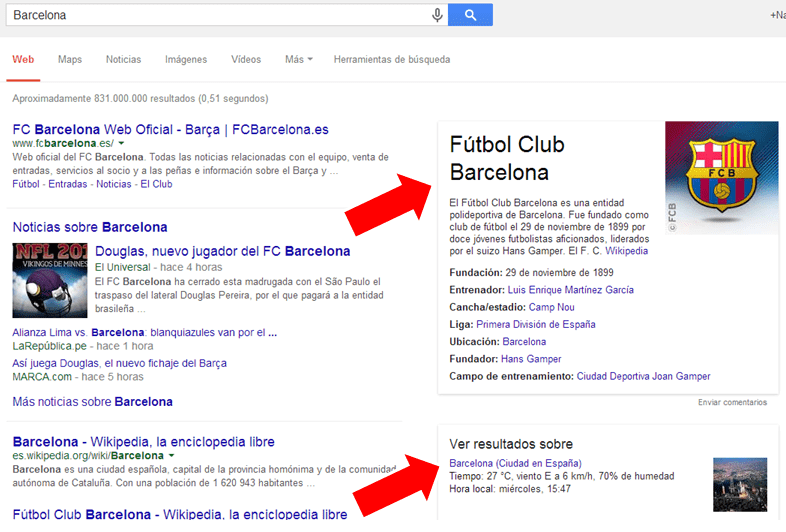 Google Knowledge Graph para la búsqueda «Barcelona»
Google Knowledge Graph para la búsqueda «Barcelona»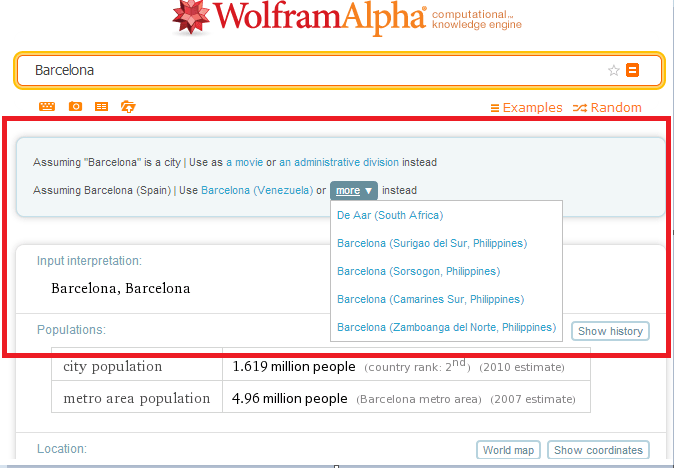 Wolfram Alpha para la búsqueda «Barcelona»
Wolfram Alpha para la búsqueda «Barcelona»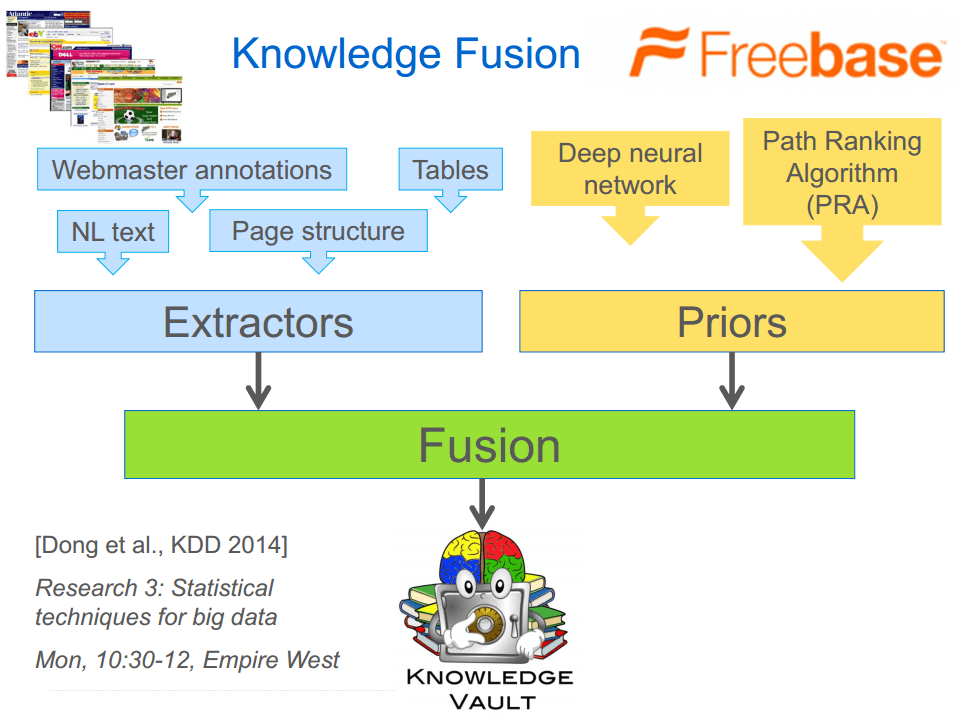 Crowdsourcing para crear el Knowledge Vault
Crowdsourcing para crear el Knowledge Vault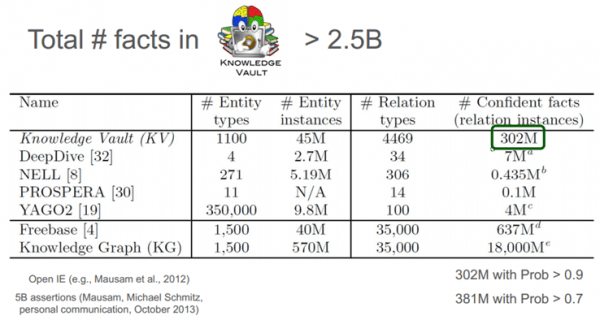 Comparación de repositorios de conocimiento
Comparación de repositorios de conocimiento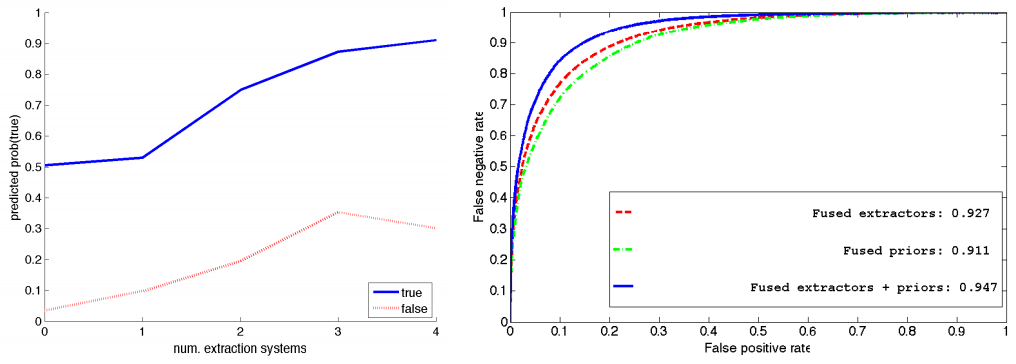
 Sistemas de estracción usados en el Knowledge Vault
Sistemas de estracción usados en el Knowledge Vault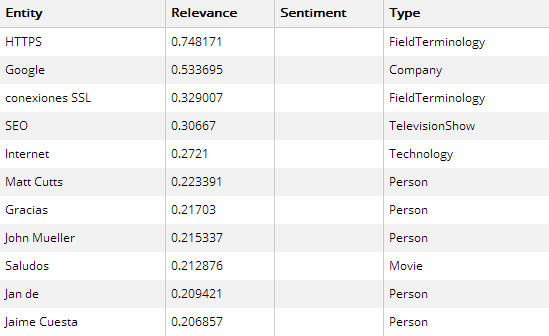 Entidades del artículo SEO, HTTPS y la desinformación
Entidades del artículo SEO, HTTPS y la desinformación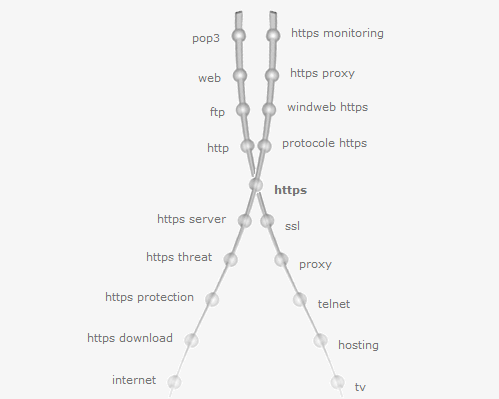 Keyword Map para «HTTPS»
Keyword Map para «HTTPS»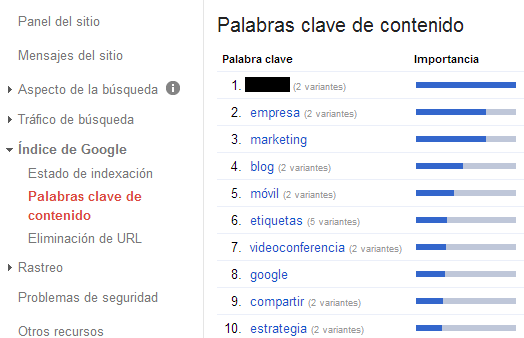 Entidades en Google Webmaster Tools
Entidades en Google Webmaster Tools