Siempre digo que es mejor remar a favor que ir en contra de los algoritmos de los buscadores y este post es un ejemplo de ello. En él os voy a enseñar el concepto de «frecuencia de rastreo» y lo vital que es su optimización (sobre todo en sitios de gran tamaño) para mejorar el tráfico orgánico.
Entendiendo la frecuencia de rastreo
Tal y como nos cuenta Google en el apartado de Rastreo e Indexación de Inside Search: «Los programas informáticos [refiriéndose a los algoritmos de Google] determinan qué sitios rastrear, con qué frecuencia y cuál es el número de páginas que se deben explorar en cada sitio.» Es decir, todas las páginas tienen asignado un crawl budget o crawl rate que como explicó Matt Cutts en 2010, es directamente proporcional al PageRank (autoridad) de la página.
Estamos ante un término que no es nuevo y que por desgracia muy pocos SEOs conocen, ya no tanto el término en sí como el impacto que tiene la optimización del crawl rate en incremento de tráfico orgánico.
Como hemos visto los sitios tienen asignado un crawl budget que está determinado por la autoridad del sitio, pero también por la facilidad de crawleo y calidad de la página. Hay una serie de trabas que los bots como Google odian porque les hacen consumir una cantidad enorme de recursos, con lo cual tu crawl rate se verá reducido. Entre ellas se encuentran:
- URLs poco accesibles
- porcentaje alto de URLs inservibles o poco efectivas (mala UX en página, poco tráfico por URL, duplicados…)
- porcentaje alto de URLs con errores (4XX, 5XX, 7XX ) o excesivas 3XX.
- tiempo de descarga del HTML de la página más alto de 500ms.
Así que nuestro trabajo como SEOs es hacer que Google consuma menos recursos y si le ayudamos nos premiará. Porque aunque Google pueda rastrear e indexar todas las páginas de tu sitio, él se reserva el derecho de hacerlo si considera que tu sitio no lo merece:
Las mejores páginas se rastrean más
Todo el mundo sabe que Caffeine aceleró la velocidad de crawleo e indexación para contenidos nuevos, pero lo que no sabe es que también sirve para mantener frescas las mejores páginas de su índice. Google sabe perfectamente qué es una URL efectiva y se encarga de crawlearla más porque es una página que le interesa tener actualizada siempre en su índice. Y esto ocurre gracias al Percolator, el sistema que se encarga de este mecanismo desde el Caffeine (aquí la patente: Large-scale Incremental Processing Using Distributed Transactions and Notifications).
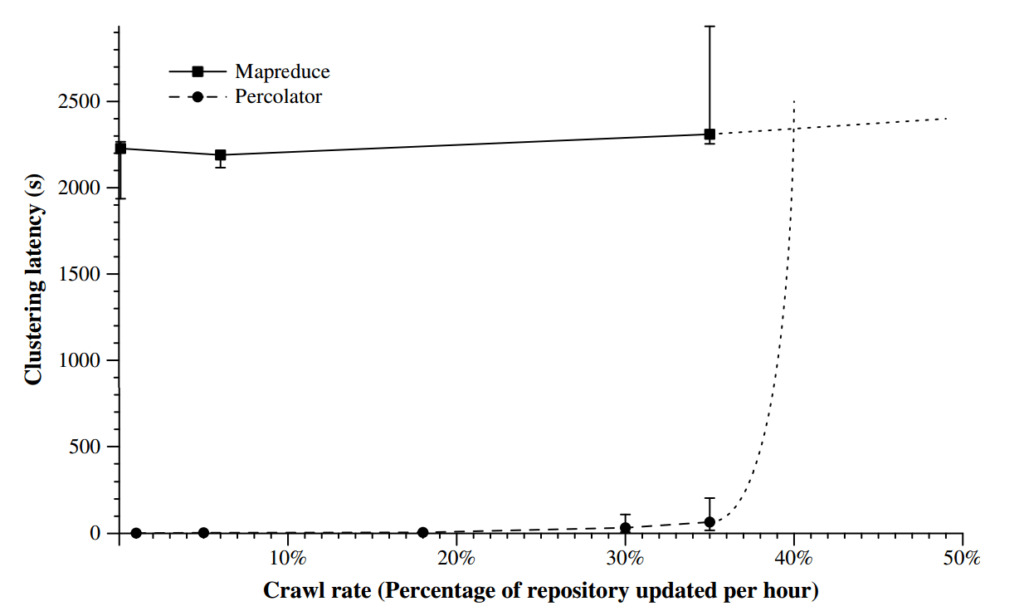
Si analizáis en vuestros logs los accesos de Google a vuestra web veréis que las secciones que se crawlean menos reciben menos tráfico y al revés, las secciones que se crawlean más reciben más tráfico. Aquí podéis pensar que es porque son páginas más enlazadas internamente y que reciben más enlaces externos pero esto no siempre es así. A parte de que es algo que cuentan las patentes y Matt Cutts ha explicado en entrevistas, este comportamiento lo he visto más de una vez con mis socios en FunnelPunk (Daniel Pinillos y Lino Uruñuela). Nos hemos encontrado con secciones que sin ser las más enlazadas suelen ser las que reciben más tráfico orgánico y su frecuencia de rastreo es superior al resto. Nosotros mismos mejoramos a nuestros clientes el ranking de las URLs de las secciones efectivas incrementando el crawl rate hacia ellas. ¿Y cómo se hace esto rastrear más una página? pues capando el acceso a las inefectivas, haciendo que su descarga sea rápida y que no haya un porcentaje de alto de URLs con errores. Aquí podemos ver un ejemplo del tráfico orgánico de uno de los verticales de un directorio que salió con todas las facetas abiertas permitiendo combinaciones que duplicaban y generaban thin content:

Al principio todo va bien y hay un boost de tráfico orgánico, pero en el momento que Googlebot se cansa de crawlear páginas basura automáticamente reduce el crawl rate y te filtra. Una de las razones de Google Panda es hacer consumir menos recursos a GBot filtrando sitios con contenido basura, no lo olvidéis.
Cómo optimizar el rastreo de tu sitio
Si queremos que las páginas efectivas se rastreen más tenemos que:
Tener una URL por intención de búsqueda
el resto capadas a menos que exista mucho volumen de búsquedas y no canibalices.
Evitar la “canonicalitis” y la “noindex, followitis”
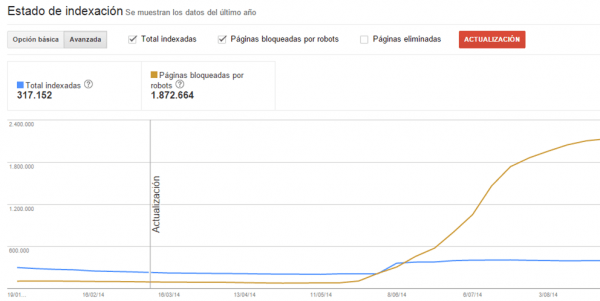
Estas instrucciones no bloquean el acceso al bot y siguen consumiéndole recursos. Y lo de usar “noindex, nofollow” siempre ha sido una chorrada como una casa. Aunque como siempre depende del caso, lo mejor es cortar de raíz con disallow. Aquí podemos ver otro ejemplo de exceso de URLs inservibles y es el propio Google quejándose a través de un aviso en Search Console.
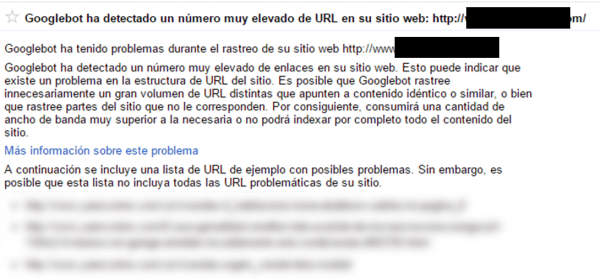
Tras recibirlo y ver la muestra de urls que nos enseñaba lo que hicimos para recuperar el site fue: primero eliminar directamente por robots todas las secciones duplicadas y segundo mover a subdominios con 301 los contenidos mal traducidos en otros idiomas mientras se acababan de traducir (si metíamos noindex, follow nos cargábamos un porcentaje que interesaba por negocio). Y ahora mismo a un cliente de ecommerce le voy a desindexar por robots el 80% de las URLs del sitio (unas 400K URLs de facetas duplicadas) que solo han aportado un 1,4% del tráfico orgánico.
Links que quieras que se rastreen siempre accesibles
Analiza siempre las páginas en modo texto en caché (o navega con Lynx) y no hagas caso del fetch & render para esto (observad la imagen)
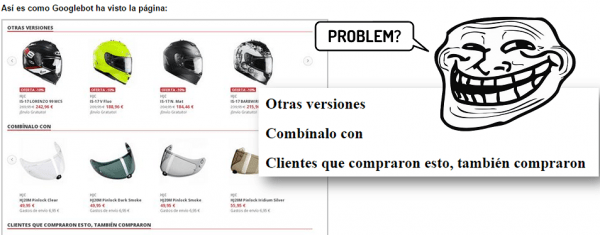
Tener cuidado con los parámetros (querystrings y sessions) Una web con 10K URLs finales podría generar 1 millón de ellas tranquilamente (muchas veces por culpa de las paginaciones que hacen crecer las combinaciones posibles hasta el infinito). Sobre los parámetros es mucho mejor usar # que ? siempre que se pueda para ahorrar trabajo al bot porque no rastrea URLs con #.
Limita al máximo el número de paginaciones
Intenta poner más productos en los listados (ojo con afectar el tiempo de carga). Prueba qué te consume menos recursos y que no te fastidie el SEO: rel next/prev, disallow por robots, view all o prueba con distintas combinaciones de estas instrucciones y/o aplicándolo solo ciertas páginas de la serie (ej: solo deja las 3 primeras páginas de la serie).
Enlaza internamente contra páginas finales
No enlaces en tu AI contra páginas que tengan rel=canonical o redirects, siempre contra páginas canónicas y con estado 200.
Controlar los errores y las redirecciones del sitio
Todo lo que no sea 200 OK hará perder el tiempo a Google en páginas que no existen o están detrás de varias redirecciones.
Tener una buena Arquitectura de la Información
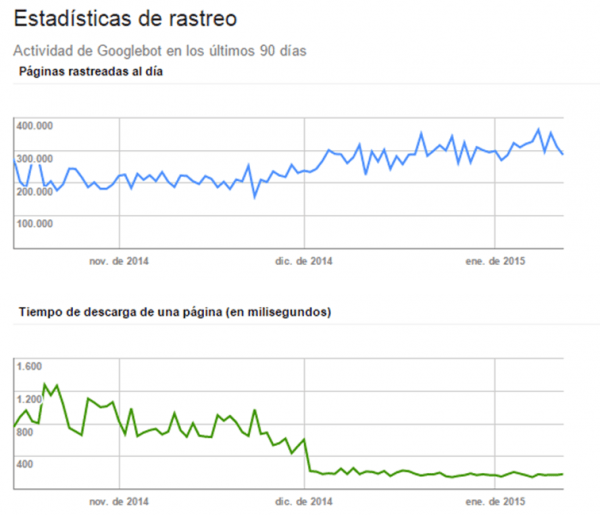
Para ello intenta conseguir una AI de 3 niveles de distancia desde la home (que es diferente del número de directorios). Si no puedes apóyate en en sitemaps HTML y sistemas de organización para acortar distancias. También es muy útil potenciar las zonas que interesen por negocio (link sculpting). En la siguiente imagen vemos como al mes de mejorar la AI de un sitio la frecuencia de rastreo se estabiliza y pasa a ser el doble de antes (manteniendo los tiempos de descarga).
Hacer que las páginas que se descarguen rápido
Sobre esto hay que saber diferenciar entre los tiempos de descarga de una página para el bot y para el usuario. Por ejemplo, una página puede tardar en descargarse 200ms para el bot y 20 segundos al usuario. Hay que intentar tener un TTFB (Time to First Byte) no más alto de 500ms (con en SSL es difícil). En la imagen siguiente los primeros tiempos de TTFB le encantan a GoogleBot, en cambio los segundos son un crimen.
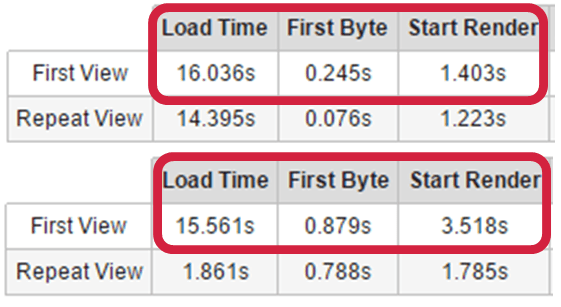
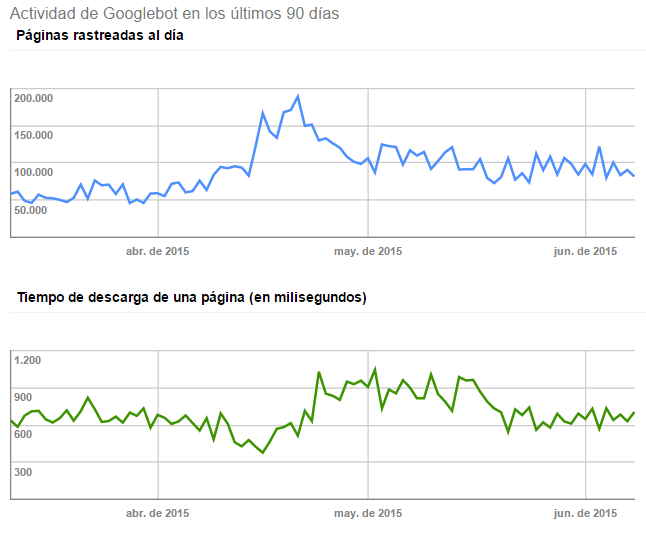
El impacto directo en SEO es lo que tarda una página en ser leída por el bot porque afecta al crawling (TTFB + descarga). En cambio el tiempo de descarga para el usuario, aunque también tiene impacto en SEO, no es de forma directa. Al existir una mala performance para el usuario, las probabilidades de rebotar contra la SERP son muy altas. Esto se llama pogo-sticking y el pogo-sticking es más importante que el CTR para el rankeo en Google. Al no haber ni un long-click ni un segundo click, Google considera la UX de esa página negativa y lo tiene en cuenta dentro de su proceso de machine-learning basado en los datos obtenidos del usuario de la SERP. Eso sí, Google es más restrictivo en mobile que en desktop y podría incluir el TTI (Time To Interact) en sus factores de ranking mobile, pero esto todavía no lo sabemos. En la siguiente imagen podemos ver cómo al mejorar la descarga de la página para Google el rastreo aumenta:
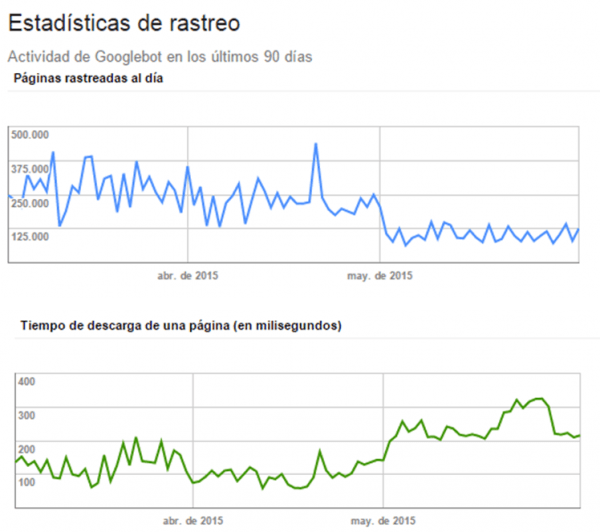
Y aquí lo que ocurre cuando en esa misma página se coloca un script síncrono, el crawl rate se va a tomar por culo y como consecuencia bajó el tráfico orgánico:
Analiza los logs dejados por Gbot antes de tomar una decisión
En la siguiente imagen podemos ver uno de los informes que sacamos a nuestros clientes. En él se puede ver en cuántas URLs ha accedido Googlebot de cada sección de la web y en cuántas los usuarios han accedido a ellas desde Google. En rojo podemos ver las URLs con un ratio muy negativo, lo que quiere decir que son URLs que tiene Google pero que no son útiles para el usuario. Lo primero que podemos pensar es porque no están lo suficientemente optimizadas a nivel onpage, pero no, se trata de secciones que son muy parecidas a otras que ya existen en el sitio (es otro directorio).
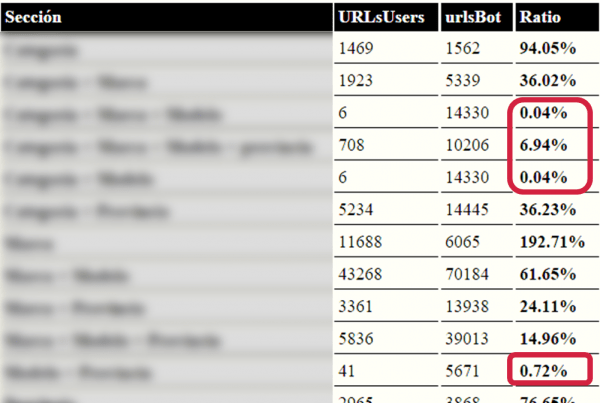
En este caso, si capas todas estas URLs duplicadas, automáticamente aumentas la velocidad de rastreo de las buenas y no solo eso, también harás que Google acceda a aquellas que no podía por la cantidad de crawl rate que tenía asignado. Con lo cual ya no solo ganarás tráfico por mejorar el rastreo, también por tener más páginas efectivas en su índice (en este caso prácticamente se doblaron):
Cuando montas una web desde cero es más sencillo plantear una arquitectura sin problemas de duplicados y con todo lo planteado aquí. El problema viene cuando te encuentras con webs que ta están hechas y tienes que tocar cosas con precisión de cirujano porque cualquier decisión errónea (y sobre todo con robots.txt de por medio) puede salirte caro. Ante la duda lo mejor es que me contactes a mi o a cualquier otro SEO con experiencia en este tipo de trabajos.
Conclusión
Como he dicho al principio el trabajo de un SEO es ayudar a que los buscadores consuman pocos recursos, y esto va desde hacerles las páginas fácilmente ‘entendibles’ a que usen bien el poco tiempo que se pasan en tu sitio. Si queréis aprender un poco más os comparto las charlas que dimos Daniel Pinillos, Lino Uruñuela y yo en el Congreso Web. ¡Os recomiendo que compréis los vídeos del streaming para entenderlo todo mejor!