Las herramientas para medir visibilidad en la IA (prompt trackers) prometen medir algo que es imposible medir con precisión.
Este informe técnico examina por qué medir la visibilidad en IA es técnicamente problemático, qué dice la evidencia disponible y cómo evaluar las herramientas del mercado.
Mi objetivo es tratar reducir la asimetría de información, es decir, equilibrar la balanza y que sepas lo mismo que saben (o deberían saber) quienes te venden estas herramientas y agencias que ofrecen "GEO/AEO".
Índice del artículo
Qué es la visibilidad en IA y qué miden los prompt trackers
La visibilidad en IA es la frecuencia y prominencia con la que una marca aparece en las respuestas de modelos de lenguaje (ChatGPT, Perplexity, DeepSeek, AI Overviews de Google, Grok, Copilot...) cuando los usuarios hacen preguntas relacionadas con su sector.
Los prompt trackers son herramientas que ejecutan prompts predefinidos contra estos modelos y miden si tu marca aparece, en qué posición, y con qué frecuencia comparada con competidores. Prometen responder preguntas como: ¿Me recomienda ChatGPT cuando alguien pregunta por "mejores herramientas de email marketing"? ¿Con qué frecuencia? ¿Por encima o por debajo de mi competencia?
El problema es que estas preguntas asumen un nivel de consistencia y replicabilidad que los LLMs, por diseño, no tienen.
Algo que el propio Jesse Dwyer, CCO de Perplexity, confirma en el WSJ: la búsqueda IA personaliza los resultados según el usuario que pregunta, lo que los hace difíciles de predecir y de medir.
La evidencia científica
Los LLMs son inconsistentes por diseño
La investigación académica ha demostrado que los modelos de lenguaje son intrínsecamente no determinísticos, incluso con configuraciones supuestamente "determinísticas":
- Un paper de enero 2025 en ACM Transactions encontró que en el 75,76% de tareas de CodeContests, ChatGPT no produjo dos outputs idénticos con temperature=0, que muchos creen erróneamente que garantiza determinismo. Algo que demostré en esta charla el año pasado.
- El estudio de Wang y Wang (marzo 2025) analizó 3.4 millones de outputs a través de 50 ejecuciones independientes por tarea. Los modelos más avanzados no son más consistentes: GPT-4o produjo respuestas exactamente iguales solo el 3% del tiempo, mientras que GPT-3.5 Turbo alcanzó el 97%. La recomendación de los autores es ejecutar 3-5 ejecuciones para mejorar la consistencia estadística. Ninguna herramienta del mercado habla de esto.
- El paper de Anthropic (noviembre 2024) reveló un problema estadístico que afecta directamente a las herramientas de AI visibility: cuando ejecutas muchos prompts sobre temas relacionados los errores no son independientes. Si el modelo tiene un sesgo hacia o contra tu marca en el tema "software CRM", fallará sistemáticamente en todos los prompts sobre CRM de forma no aleatoria. Anthropic encontró correlaciones de 0.3 a 0.7 entre preguntas relacionadas, lo que significa que 30 prompts sobre temas similares no equivalen a 30 datos independientes, sino quizás a 5-10. Hay muy poca transparencia en el método/proceso exacto que usan los llm trackers para obtener las respuestas, por lo que no sabemos si esto podría ser un problema o no.
- La variabilidad no solo viene de la aleatoriedad inherente del modelo, sino también del formato del prompt. En la revisión que hice recientemente de la literatura científica documenté diferencias de hasta 76 puntos de precisión por cambios menores como espacios, puntuación o mayúsculas (FormatSpread, Sclar et al.).
Volatilidad medida: 40-60% de cambio mensual
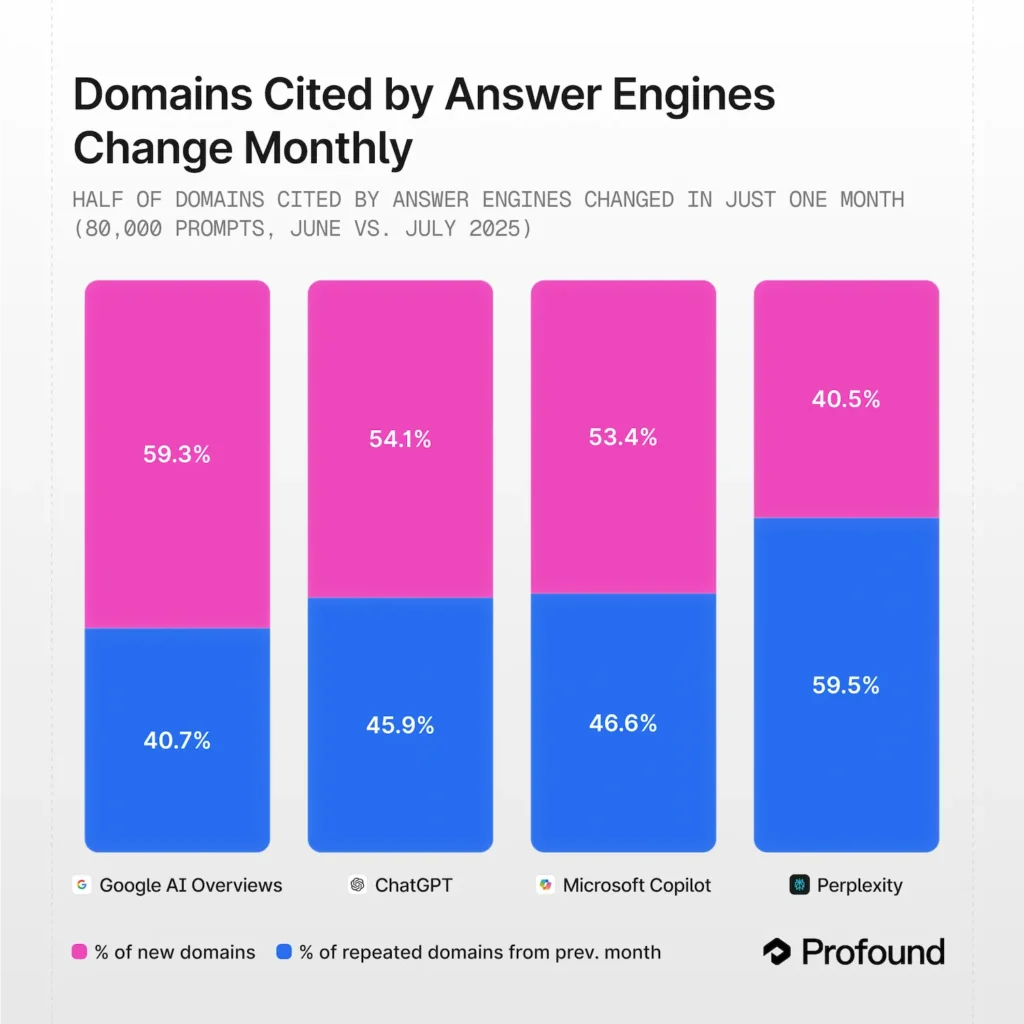
El estudio de Profound (julio 2025) analizó ~80.000 prompts por plataforma comparando junio con julio:
- Google AI Overviews: 59,3% de los dominios citados cambiaron
- ChatGPT: 54,1%
- Microsoft Copilot: 53,4%
- Perplexity: 40,5%
En periodos de 6 meses, la volatilidad se dispara al 70-90%.
Estudios sobre consistencia de marcas
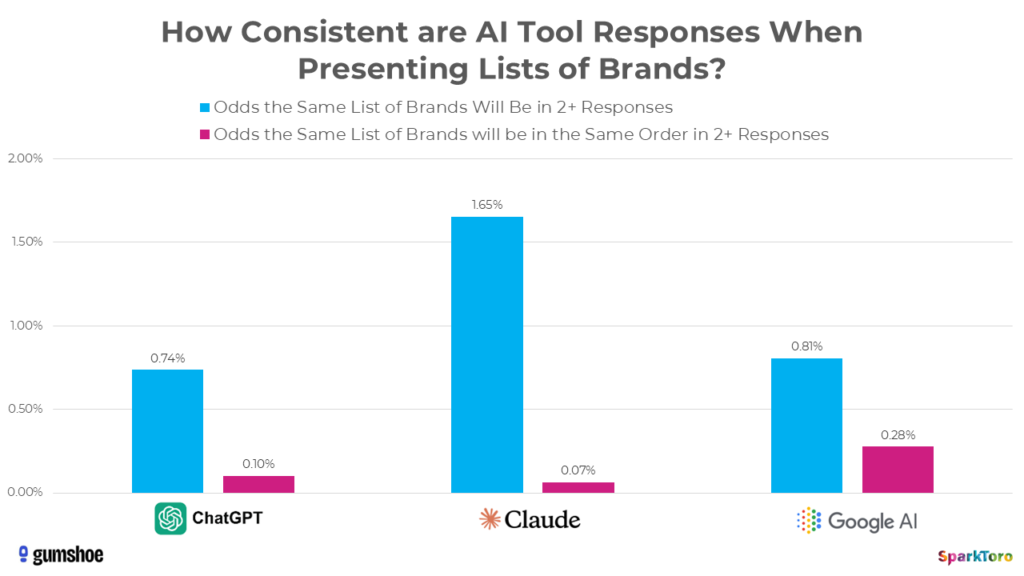
El estudio de SparkToro (enero 2026) ejecutó 2.961 prompts a través de 600 voluntarios usando ChatGPT, Claude y Google AI en 12 categorías. Resultados:
- Menos de 1 en 100 probabilidades de obtener la misma lista de marcas dos veces
- Menos de 1 en 1.000 probabilidades de obtener la misma lista en el mismo orden
La variabilidad depende del tamaño del espacio de consideración. Para queries con pocas opciones (concesionarios Volvo en Los Ángeles), la correlación es alta. Para espacios amplios (novelas de ciencia ficción), la variabilidad es extrema.
Rand Fishkin dice que que aunque las listas y rankings son aleatorios, el porcentaje de visibilidad (cuántas veces aparece una marca en múltiples ejecuciones) puede ser una métrica válida. "City of Hope hospital" apareció en el 97% de las respuestas sobre hospitales oncológicos en la costa oeste, aunque su posición variaba constantemente.
Mi opinión es que una métrica sea "menos aleatoria" no la convierte en útil. El porcentaje de visibilidad te da una foto borrosa de algo que no puedes controlar, porque está basada en prompts que no son los que hacen tus usuarios reales, ejecutados en condiciones que no reflejan su experiencia. Es el menos malo de los indicadores, pero sigue siendo un indicador de valor limitado.
Hay otro problema y es que la visiblidad tiene un sesgo estructural hacia las marcas ya establecidas. Las marcas conocidas (Booking, Amazon, MediaMarkt) muestran métricas más estables porque están sobrerrepresentadas en los datos de entrenamiento porque aparecen en miles de contextos diferentes, creando asociaciones robustas en los pesos del modelo. Para marcas emergentes o de nicho, el mismo % de visibility fluctúa tanto entre ejecuciones que es prácticamente ruido estadístico. Esto es una paradoja porque las herramientas son más "fiables" precisamente para quienes menos las necesitan (las marcas que ya saben que son visibles), y menos fiables para quienes más las necesitarían (marcas intentando ganar visibilidad).
Para tener una visibilidad "fiable" necesitas ejecutar cientos o miles de prompts múltiples veces. El coste computacional (y económico) de eso para conseguir un dato direccional que no correlaciona con tráfico ni conversiones es difícil de justificar.
El estudio de Mike Sonders (febrero 2026) analizó 1.200 interacciones con ChatGPT (12 prompts × 100 ejecuciones cada uno, con IP diferente por sesión) centrado en recomendaciones de software B2B y encontró lo siguiente:
- Cuanto más de nicho es una categoría, más fácil es aparecer de forma consistente en las respuestas de IA.
- Solo el ~11% de las marcas que un LLM menciona en una categoría aparecen de forma consistente. El resto rota de forma casi aleatoria entre respuestas.
- Cuanto más específico es el prompt (con rol, contexto o caso de uso), más difícil es entrar en el grupo de marcas dominantes, porque el modelo se compromete más con menos opciones. Esto genera más ruido en las mediciones, y es un problema para los trackers porque los usuarios reales hacen prompts complejos y contextuales, no las preguntas genéricas tipo "best X software" que usan la mayoría de herramientas. Una única ejecución por prompt es casi inútil dada la variabilidad. Sonders recomienda un mínimo de ~5 ejecuciones por prompt en la sesión, algo que las herramientas de tracking no hacen, por desconocimiento y, de saberlo, no lo harán porque se les multiplicaría por x5 el coste.
Cómo deciden los LLMs qué información mostrar
El sistema QDF de los modelos
La filtración del system prompt de GPT-5 revela que ChatGPT usa un sistema QDF (Query Deserves Freshness) con escala de 0 a 5:
- 0: Histórico, no importa que esté actualizado
- 1: Relevante si es de los últimos 18 meses
- 2: Relevante si es de los últimos 6 meses
- 3: Relevante si es de los últimos 90 días
- 4: Relevante si es de los últimos 60 días
- 5: Lo más reciente de este mes
No todas las queries activan búsqueda web. En ChatGPT Existe un parámetro use_freshness_scoring_profile evalúa para cada query si necesita información externa. Además, descubrí que ChatGPT ejecuta un clasificador probabilístico llamado Sonic que calcula una search_prob (la probabilidad de que la query necesite datos frescos) y la compara contra un umbral (force_search_threshold), actualmente en torno al 65%.
Los leaks de Claude Sonnet 4.5 muestran un patrón similar donde el modelo categoriza consultas en "nunca buscar" (hechos estables, definiciones), "single search" (términos desconocidos), y "research" (2-20 llamadas con contraste multi-fuente).
Reranking y señales de contexto
El sistema de reranking de ChatGPT (ret-rr-skysight-v3) aplica señales adicionales de detección de intención, terminología de dominio, filtrado por tipo de fuente. Si hay herramientas internas disponibles (Google Drive, Slack, CRM), los modelos las priorizan sobre búsqueda web. Todo esto depende del contexto de tu conversación.
Las patentes de Google: por qué los prompts sintéticos no funcionan
Estas dos patentes demuestran por qué las herramientas externas no pueden replicar cómo Google genera query fan-out y organiza resultados.
- Query Fan-Out (US20230281193A1): Cuando alguien busca algo Google no se limita a esa query literal, lo que hace es generar variantes usando modelos entrenados con el comportamiento real de millones de usuarios (qué buscaron, en qué hicieron clic, qué reformulaciones hicieron después). Además, tiene en cuenta cosas que una herramienta externa simplemente no puede saber como dónde está el usuario, qué estaba haciendo antes o su historial de sesión. Todo esto se procesa en tiempo real, adaptándose al contexto de cada búsqueda individual.
- Thematic Search (US12158907B1): Google analiza los documentos que considera relevantes para una búsqueda, genera resúmenes internos de cada uno, los agrupa en clusters temáticos y luego los ordena según criterios como calidad, autoridad o popularidad. El problema es que esas señales de ranking son completamente opacas desde fuera, es decir, no sabemos exactamente cómo pondera cada factor ni qué documentos considera relevantes antes de mostrarnos nada.
- SAGE de Google (enero 2026): los agentes de Google de deep search están siendo entrenados para ejecutar entre 2 y 10 hops de razonamiento por query, usando estrategias como resolución de conflictos entre fuentes, generación de hipótesis y razonamiento temporal. Todo esto ocurre internamente antes de que veas la respuesta. Los prompts sintéticos de las herramientas externas ni siquiera se aproximan a esta complejidad.
Los datos empíricos confirman esto. El estudio de Ahrefs (marzo 2026) analizó 863.000 SERPs y 4 millones de URLs citadas en AI Overviews y encontró que solo el 38% de las páginas citadas en AI Overviews también aparecen en el top 10 orgánico para esa misma query. El 62% restante proviene de páginas que rankean más abajo o directamente no aparecen en los resultados orgánicos de la query original. En julio de 2025, esa cifra era del ~76%. Es decir, con Gemini 3, Google está tirando cada vez más del fan-out interno para seleccionar fuentes, no de los resultados directos. Si ni siquiera rankeando en el top 10 tienes garantía de ser citado, imagina lo que puede capturar un prompt tracker lanzando queries desde fuera sin acceso a las sub-queries internas.
El propio artículo de Ahrefs reconoce que los AI Overviews son probabilísticos, y su contenido, citaciones, entidades y fan-outs cambian con cada consulta.
Por qué no puedes replicar la experiencia del usuario
Memoria del modelo vs búsqueda web
Hay un problema que creo que ninguna herramienta de prompt tracking resuelve y es que no te dicen si el LLM buscó en la web o respondió desde su conocimiento interno.
*Update 01/02/2026: He encontrado que Wikay.io sí que lo hace.
*Update 02/2026: Bing Webmaster Tools ha lanzado AI Performance, que resuelve parcialmente este problema al reportar solo citaciones visibles en respuestas de Copilot y Bing AI. Si tu URL aparece ahí, sabes que fue retrieval, no conocimiento paramétrico. Es el primer dato de primera parte que confirma esta distinción.
Esta decisión depende de la configuración del modelo (versión, temperatura, system prompts, si tiene search habilitado), de la volatilidad del tema y cómo se formula el prompt (para precios o noticias busca siempre, para definiciones o conceptos estables responde de memoria), del umbral de confianza interno (si el modelo "cree" que sabe la respuesta, no busca), y del método de acceso, porque API e interfaz web tienen comportamientos de búsqueda distintos.
Y cuando sí busca, hay otra capa de opacidad porque el modelo no ejecuta tu prompt literal. Como vimos antes, genera múltiples subqueries internas (fan-out), busca en paralelo, y sintetiza. Tu marca puede aparecer en el resultado final, pero no sabes qué subquery fue responsable. No puedes optimizar para algo que desconoces.
Esto cambia completamente la accionabilidad:
- Si la respuesta viene de búsqueda web: puedes crear y optimizar contenido, digital PR... pero sin saber para qué subquery exacta.
- Si la respuesta viene del conocimiento paramétrico: no hay nada que hacer a corto plazo. Dependes del próximo ciclo de entrenamiento y de cambiar la narrativa del corpus general sobre tu marca.
Es como saber que tu cartera subió un 5% sin saber qué activo lo causó...
Y no solo desconoces la subquery porque ni siquiera sabes en qué idioma se hizo. Un estudio de Peec AI (febrero 2026) analizó más de 10 millones de prompts y 20 millones de query fan-outs y encontró que el 43% de las subqueries internas de ChatGPT para prompts no-inglés se ejecutan en inglés. En el 78% de sesiones no-inglés, ChatGPT complementa con búsquedas en inglés. Un usuario español preguntando en español desde España recibe resultados influenciados por fuentes anglófonas. Los prompt trackers que lanzan prompts en español no capturan esta capa de opacidad adicional.
Personalización por contexto
ChatGPT implementa dos sistemas de memoria (Saved Memories y Chat History) que influyen en cada respuesta. Experimentos del AEO Agency Team demostraron que incluso bajo "condiciones de testing absolutamente idénticas, las respuestas a veces difirieron".
Para queries geo-dependientes, ChatGPT convierte internamente los prompts. Un usuario en Nueva York que pregunta "mejores tiendas de electrónica" recibe una consulta procesada como "trusted electronics brands NYC store". Usuarios de pago reciben además respuestas "significativamente mejores" que los gratuitos.
Google ahora lleva las preguntas de seguimiento de AI Overviews directamente a AI Mode, manteniendo el contexto de la conversación. La búsqueda ya no es una query aislada, es una conversación donde cada pregunta influye en la siguiente.
Integración con datos privados
Robby Stein (VP de Producto en Google) anunció que usarán datos de Gmail, Drive y Calendar para personalizar respuestas. Una búsqueda de "mejores hoteles en Londres" tendrá en cuenta reuniones en Calendar, vuelos en Gmail, presupuestos en Sheets.
Google lanzó Personal Intelligence (enero 2026), que conecta Gemini con Gmail, Photos, YouTube y Search history. La función usa "context packing" para analizar repositorios de usuarios que superan el millón de tokens. Un ejemplo de Google: preguntar por neumáticos para tu coche y Gemini extrae la matrícula de una foto en Google Photos, busca especificaciones en emails de Gmail, y sugiere opciones basándose en fotos de viajes anteriores.
MCPs y herramientas instaladas
Claude, ChatGPT y otros LLMs permiten conectar herramientas externas (MCPs) que modifican el comportamiento del modelo. Un usuario con MCP de su CRM instalado recibirá respuestas completamente diferentes. Las herramientas de visibility no pueden saber qué MCPs ni qué contexto tiene cada usuario.
Esto, sumado a AI Mode generando interfaces al vuelo, los chats grupales en ChatGPT, y las memorias en todas las IAs... Si ya no tenían sentido los LLM trackers de 50 prompts, ahora menos.
Un pequeño cambio en system prompt, memorias o herramientas cambia completamente el resultado. No hay forma confiable de trackear la experiencia real de usuarios de LLM.
Prompt Trackers: Herramientas para medir visibilidad en IA
Las herramientas del mercado difieren en cuatro dimensiones: escala (cuántos prompts ejecutan), fuente de prompts (demanda real vs sintéticos), método de acceso (API vs scraping), y modelo de negocio.
Escala de datos
Escala masiva (millones de prompts):
- SISTRIX: 10 millones de prompts por idioma × 5 idiomas = 50M prompts totales. Google AI (AI Overviews & AI Mode), Perplexity, ChatGPT, DeepSeek.
- Ahrefs Brand Radar: ~190 millones de prompts/mes. ChatGPT (10,6M), Perplexity (13,1M), Gemini (7,2M), Copilot (13,3M), AI Overviews (134M), AI Mode (13,5M).
- Semrush AI Visibility: 100+ millones de prompts globales, incluyendo 90M+ en EEUU y 29M+ específicos de ChatGPT. ChatGPT, Perplexity, Gemini, Google AI Overviews/AI Mode.
Escala pequeña (decenas a cientos de prompts):
Fuente de los prompts
Demanda real (derivados de búsquedas web):
- SISTRIX: sugerencias de prompts de ChatGPT + "People Also Ask"
- Ahrefs: base de 28,7 mil millones de keywords + "People Also Ask"
- Semrush: compra clickstream data de paneles de terceros (quizás mediante data de prompts substraida de extensiones de Google o Microsoft), agrupa los prompts en topics, anonimiza y simplifica, así que técnicamente es sintético porque no son los prompts exactos
Sintéticos (inventados por el cliente o la herramienta):
- Conductor, Gumshoe, Otterly, Peec, Promptwatch, Profound, Wikay: el cliente define sus propios prompts (por ejemplo, usan queries long tail de Search Console) o la herramienta los genera algorítmicamente (prompts sintéticos, simulaciones de query fan-out)
Aunque Ahrefs llama a todo sintético: "Todas las herramientas usan prompts sintéticos ya que los datos de queries reales de usuarios no están disponibles." La diferencia es si esos prompts sintéticos derivan de señales de demanda real (PAA, keywords con volumen) o son completamente inventados.
Configuración de sesiones: La mayoría de herramientas ejecutan prompts en sesiones "limpias" (sin cookies, historial ni memoria). Gumshoe documenta explícitamente: "cada conversación empieza fresca, sin cookies ni historial, para asegurar resultados libres de sesgo". Esto es bueno para consistencia y replicabilidad, pero no refleja la realidad de usuarios con historial acumulado, memorias guardadas y contexto personalizado.
Personas/perfiles: Gumshoe usa un "enfoque persona-first", modelando cómo distintos segmentos de usuarios (roles, objetivos, pain points) formularían los prompts. El resto de herramientas trata todos los queries igual, ignorando que un CTO pregunta diferente que un marketing manager. Sin embargo, añadir personas introduce otra variable: o bien no cambian significativamente los resultados (según el estudio de Surfer que probó con system prompts filtrados), o bien añaden otra capa de variabilidad que hace los datos menos comparables entre herramientas.
Método de acceso: API vs Scraping
El estudio de Surfer SEO (diciembre 2025) comparó ambos métodos con 1.000 prompts:
- ChatGPT vía API: promedio de 7 fuentes citadas
- ChatGPT vía scraping: promedio de 16 fuentes citadas
- Perplexity: coincidencia de fuentes entre métodos del 8%
- 8% de llamadas API fallan en detectar menciones que sí aparecen en la interfaz
Conclusión de Wojciech Korczyński: "Monitorear respuestas desde API como proxy de tu AI visibility es totalmente erróneo."
Herramientas que documentan usar interfaces web (scraping):
- Ahrefs: documentan que todas las solicitudes se ejecutan a través de las interfaces web gratuitas y disponibles públicamente de ChatGPT, Gemini, Perplexity y Copilot.
- Otterly: usa Firecrawl.dev y SerpApi como subprocesadores de scraping
- SISTRIX: usa exclusivamente web scraping via interfaces reales de navegador, no APIs. Confirmado con su CEO, Johannes Beus
Herramientas que priorizan API: Conductor, Gumshoe , Wikay.
Metodología no especificada (o encontrada por mi) públicamente: Semrush, Peec, Promptwatch, Profound. Entiendo también que se oculte por incumplimento de ToS, así que es probable que usen scraping.
El problema del desfase de versiones
Las herramientas testean versiones de modelos que difieren de las que usan los usuarios (la última disponible), mientras muchas herramientas siguen usando GPT-4o, cuando la realidad es que actualmente solo el 0,1% de usuarios lo elige a diario. Y los los estudios de Wang y Wang demostraron también que modelos más recientes son más variables.
SISTRIX documenta exactamente qué modelos testea: gpt-4o-mini, gpt-4.1-mini para ChatGPT; gemini-2.0-flash-lite, gemini-2.0-flash, gemini-2.5-flash para Gemini; v3 para DeepSeek. Actualizan sus datos cuando se lanza un nuevo foundation model, reconociendo que "consultar los modelos más frecuentemente no añade valor, ya que la información en estos foundation models es estática."
La mayoría de herramientas no documentan qué versión del modelo testean ni con qué frecuencia actualizan.
Umbrales de significancia: ¿cuántos prompts necesitas?
El estudio de Wang y Wang mencionado antes recomienda 3-5 ejecuciones por prompt para obtener consistencia estadística, pero esas ejecuciones deben ser simultáneas o en la misma sesión. Ejecutar un prompt una vez al día durante un mes no cumple este requisito: son 30 mediciones de 30 estados diferentes del sistema (modelo actualizado o estado del backend, contenidos diferentes recuperados en la inferencia, contexto temporal distinto), no 30 mediciones del mismo estado.
Si hay menos de 1 en 100 probabilidades de obtener la misma lista dos veces, una herramienta con 25 prompts no puede darte una imagen representativa de tu visibilidad real, independientemente de cuántas veces ejecute esos 25 prompts.
Aún así, el problema real no es tanto la frecuencia de ejecución, sino la escala y representatividad:
- 25 prompts ejecutados 30 veces cada uno siguen siendo 25 prompts. No representan el universo de queries que los usuarios reales hacen sobre tu sector.
- Los prompts sintéticos inventados por el cliente reflejan lo que el cliente cree que preguntan los usuarios, no lo que realmente preguntan.
SparkToro usó 2.961 prompts con 600 voluntarios para su estudio. Profound usó ~80.000 prompts por plataforma. SISTRIX usa 10 millones por idioma. La diferencia de escala determina si puedes detectar patrones reales o solo ruido estadístico.
Modelo de negocio y estructura de precios
La diferencia más relevante es si el tracking de IA es un producto independiente o una funcionalidad dentro de una suite más amplia.
Herramientas especializadas (tracking como producto principal):
- Otterly: desde $29/mes (15 prompts) hasta $489/mes (400 prompts)
- Peec AI: €89/mes por 25 prompts hasta $217/mes (100 prompts)
- Promptwatch: $89/mes (50 prompts), $199/mes (150 prompts), $499/mes (350 prompts)
- Waikay: desde $19,95/mes (120 prompts) hasta $444/mes (4.000 prompts)
- Profound: desde $99/mes
- SE Visible: desde $99/mes (150 prompts) hasta $355/mes (1.000 prompts)
- Gumshoe: $0,10 por conversación (pago por uso)
Suites con tracking incluido o como add-on:
- SISTRIX: desde $140/mes con AI Research incluido (50M prompts, 5 idiomas, 3 chatbots). Acceso a base de datos compartida y tracking de prompts personalizados.
- Ahrefs Brand Radar: desde $199/mes por plataforma individual o $699/mes por todas las plataformas (Google AI, ChatGPT, Perplexity, Copilot, Gemini). Incluye 271M queries/mes del dataset de Ahrefs + 2.500 custom prompts/mes (por un extra de $50).
- Semrush AI Visibility: $99/mes por dominio como add-on, o incluido en Semrush One desde $199/mes. Base de datos de 239M+ prompts; tracking personalizado de 25-50 prompts según plan.
- Conductor: estimado $10.000-50.000 anuales (orientado a Fortune 500)
El coste de ejecutar 100 prompts diarios con GPT-4o-mini es ~$2,04/mes. Los márgenes de las herramientas especializadas oscilan entre 85-95%.
Como dice Kevin Indig: "Tracking is a feature, not a company." Y su argumento no es que medir sea inútil, es que el tracking no es defendible como negocio porque se comoditiza. Amplitude ofrece monitoring en LLM gratis, Semrush lo añadió como checkbox, Sistrix lo incluye por defecto... Las plataformas establecidas absorben el tracking como feature y matan a los standalone. Eso es exactamente lo que está pasando.
Dirás: "pero Ahrefs también empezó como rank tracker." Sí, con dos diferencias. Primera: el rank tracking tradicional tenía un moat real y una correlación demostrada con tráfico orgánico y conversiones. Segunda: precisamente porque el rank tracking se commoditizó, esas empresas sobrevivieron convirtiéndose en suites completas.
Las herramientas que dependen únicamente del tracking de IA como producto tienen incentivos para exagerar su valor y para abusar del desconocimiento del cliente. Como he escrito antes, lanzar 50 prompts para "medir tu visibilidad en IA" es como hacer una encuesta electoral preguntando a tus amigos. Aunque estén bien escogidos y sean 50 prompts especializados en tu industria equivaldrían a 2-15 datos independientes según Anthropic. Necesitas millones de prompts para extraer patrones significativos. Eso solo pueden hacerlo herramientas como SISTRIX, Ahrefs o Semrush que operan a escala masiva.
Es más, Rand Fishkin calificó las respuestas de IA como "loterías estadísticas" y este mercado alcanzará los $200 millones en 2026, con "casi cero ROI".
En conversaciones privadas con varios founders de prompt trackers que me han pedido ayuda para desarrollar su tool y que no he citado aquí (algunos ya con inversiones millonarias), he encontrado un patrón preocupante y es que muchos desconocían problemas metodológicos básicos como la diferencia entre prompts sintéticos y derivados de demanda real, api vs interfaz, la posibilidad de comprar datos de prompts, o las limitaciones estadísticas que he documentado aquí, entre otras cosas. Algunos me reconocieron que "por algo hay que empezar". Otros ya han pivotado con su tool al darse cuenta de la magnitud del problema. Es decir, el mercado se está construyendo más rápido de lo que se está entendiendo.
Y, a día de hoy, cualquiera puede montar una herramienta de tracking en un fin de semana. Hasta puedes hacerte la tuya propia en un momento con FireGEO open-source. Creo que muchas tools de seguimiento de IA buscan aprovecharse del desconocimiento técnico, el FOMO y el hype para ganar dinero en este momento de incertidumbre.
Todas las herramientas anteriores son third-party, es decir, ejecutan prompts desde fuera e intentan inferir lo que pasa dentro. Bing Webmaster Tools ha lanzado AI Performance, el Search Console de la IA, donde es el propio Microsoft diciéndote qué contenido citó Copilot y Bing AI en respuestas generadas para usuarios reales. Ofrece:
- Pages Cited: qué URLs de tu sitio fueron citadas en respuestas de IA, con frecuencia por página.
- Grounding Queries: las frases que el sistema usó al recuperar tu contenido. No son los prompts exactos del usuario, sino agrupaciones temáticas, pero son la primera aproximación real a saber para qué consultas te citan.
Esto elimina de golpe varios problemas que afectan a las herramientas externas: no hay desfase de versiones (mide el modelo que usan los usuarios reales), no hay problema de API vs scraping (son datos internos del sistema), no hay prompts sintéticos (refleja actividad real), y distingue citaciones visibles de grounding interno (solo reporta lo que el usuario ve). Datos reales, del sistema real, sobre usuarios reales.
Limitaciones importantes:
- Solo cubre Microsoft Copilot y Bing AI.
- Los datos son agregados y muestreados, no un log completo de cada citación, por lo que actividad muy baja puede no aparecer.
- Los grounding queries son frases generalizadas, no los prompts exactos que escribieron los usuarios.
- No mide tráfico, clicks ni conversiones. Una citación no implica que el usuario hiciera nada con tu enlace.
- No calcula rankings, authority ni visibility scores. Solo cuenta citaciones y ni tan mal.
La dirección lógica es que el resto de proveedores siga este camino. Google ya tiene infraestructura similar con Search Console y sería natural que extienda el informe de rendimiento a AI Overviews y AI Mode. OpenAI podría hacer lo mismo para ChatGPT para search ads. Hasta que eso ocurra, Bing AI Performance es el único dato de primera parte disponible para visibilidad en IA.
Por qué las métricas de visibilidad en la IA actuales no funcionan
Visibility score
Franco advierte que "no hay herramienta en el mercado con insight 100% preciso sobre lo que los usuarios escriben en herramientas de IA. Cualquier visibility score reportado es modelado, no medido."
El problema fundamental es que cada herramienta usa una fórmula diferente.
- Geneo calcula: presencia × 0,5 + prominencia × 0,3 + clicks esperados × 0,2
- Advanced Web Ranking asigna: posición 1 = 100%, posición 2 = 90%... posición 10 = 10%.
- Surfer usa menciones de marca ÷ respuestas IA analizadas.
- RankForLLM evalúa 7 categorías de 0-5 sobre un total de 35 puntos.
Cuatro fórmulas completamente diferentes. Un visibility score de 45 en una herramienta no significa nada comparado con un 45 en otra. Y ninguna te dice si ese número es "bueno" o "malo" porque no hay benchmark universal contra el que comparar. Dirás: "bueno, lo que importa es el trend y quedarte con una tool". He trabajado con varias herramientas y he obtenido trends distintos tanto para mi cliente como para los competidores. No hay correlación entre ellas.
Share of Voice
Cassie Clark documenta que esta métrica no asigna peso por posición o prominencia, no correlaciona con clicks o conversiones (las respuestas de IA satisfacen la intención sin requerir click), no combina múltiples prompts en un score compuesto. Es decir, mide presencia, no impacto.
Incluso LinkedIn, con acceso a datos propietarios de tráfico LLM hacia sus propias webs, reconoce que el reto está en el dark funnel y que no pueden cuantificar cómo la visibilidad dentro de respuestas LLM impacta el bottom line.
Pero hay un problema más básico y es que el cálculo depende de quién defines como competidor. La fórmula típica es: menciones de tu marca ÷ menciones totales (tu marca + competidores). Si añades un competidor nuevo a tu lista, tu Share of Voice baja automáticamente sin que haya cambiado nada real en el mercado. Si quitas uno, sube. El denominador es completamente arbitrario.
Además, el SoV varía significativamente entre plataformas porque una marca puede tener 20% en ChatGPT pero solo 10% en Copilot. ¿Cuál es tu "verdadero" Share of Voice? No hay respuesta.
En publicidad tradicional, el Share of Voice tiene una relación demostrada con cuota de mercado. En LLMs, esa correlación no se ha demostrado y menos la conexión con outcomes de negocio
Ranking position
El concepto de "posición" en una respuesta de IA carece de sentido. En una respuesta de 500 palabras que menciona 5 fuentes, ¿quién es "posición 1"? ¿La primera fuente mencionada? ¿La más citada? ¿La que aparece en el primer párrafo? SEO Testing confirma que "como los outputs de LLMs varían por sesión, modelo y formulación exacta del prompt, no hay un 'Posición 1' universal como había con el tracking de keywords."
Como vimos en el estudio de SparkToro, hay menos de 1 en 1.000 probabilidades de obtener la misma lista de marcas en el mismo orden. La posición es esencialmente aleatoria. Sin embargo, el porcentaje de aparición (cuántas veces aparece una marca en múltiples ejecuciones) puede ser más estable y potencialmente útil como métrica.
Prompt volume
Varias herramientas muestran métricas de "AI Search Volume" o "Prompt Volume" que dan apariencia de demanda real, pero esto es completamente modelado.
Semrush muestra "Related Topics AI Volume" que define como "estimated monthly AI search activity", es decir, una estimación, no datos reales. Ahrefs es más honesto: "No existen datos reales de demanda. Ninguna compañía tiene acceso a datos de volumen de búsqueda reales para ChatGPT."
Este problema del volumen de búsqueda es peor que en SEO tradicional porque:
- En Google, el volumen de búsqueda se basa en datos reales de queries (aunque agregados)
- En LLMs, nadie fuera de OpenAI, Google o Anthropic sabe qué preguntan los usuarios
- Los prompts trackeados suelen ser más específicos y de cola larga que las búsquedas tradicionales, así que incluso si hubiera datos, los volúmenes serían menores
- La propia monitorización cambia drásticamente el resultado: ejecutar el mismo prompt desde una cuenta de herramienta infla el volumen de forma desproporcionada.
Citations
Desambiguación
Hay un problema técnico que afecta a todas las métricas anteriores y es la detección de marca. "Stradivarius" puede ser la marca de ropa o el violín (o su creador). "Apple" la tecnológica o la fruta. "Corona" la cerveza, el virus, dental, solar, monárquica... ¿ves mi punto?
La mayoría de herramientas no hacen desambiguación de entidades, hacen simple string matching, es decir, buscan si aparece "Stradivarius" en la respuesta sin analizar el contexto. Esto genera falsos positivos que inflan artificialmente las métricas de visibilidad. Si tu marca comparte nombre con algo popular en otro dominio, tu visibility score puede incluir menciones que no tienen nada que ver contigo.
SISTRIX trabaja activamente en detección de marca contextual para resolver este problema, pero es una limitación que la mayoría de herramientas ni siquiera mencionan.
Hidden links
Existe otro problema técnico que afecta directamente a la fiabilidad de las métricas de citations. RESONEO identificó en el código de ChatGPT tres tipos distintos de URLs:
- Citations: enlaces visibles al final de las frases + panel de fuentes. Máxima visibilidad para el usuario.
- Other Sources: sección "Más" debajo de las citations. Visibilidad media.
- Hidden Links: URLs que ChatGPT usa internamente para grounding pero que nunca se muestran al usuario. Visibilidad cero.
Como comenta Olivier: "Los estudios que muestran Arxiv o YouTube como 'dominios más citados' probablemente no distinguieron entre citaciones reales y URLs de grounding interno invisibles."
Mi apuesta: El tracking de prompts masivo
Antes de nada quiero aclarar que incluso las herramientas con millones de prompts tienen un problema fundamental porque cada una usa un corpus diferente. SISTRIX trackea 10 millones de prompts por idioma, Ahrefs ~190 millones globales, Semrush 239 millones. Pero no son los mismos prompts.
Esto significa que la "visibilidad" de tu marca en SISTRIX no es comparable con la de Ahrefs o Semrush. Cada herramienta te dará un número diferente porque están midiendo universos distintos. No hay forma de saber cuál está "más cerca de la realidad" porque ninguna tiene acceso a los prompts reales de los usuarios.
Otro problema que tiene es que para clientes de nicho o marcas poco conocidas es muy probable que no encuentres nada en ellas.
GAPs por topics
Eso sí, estas herramientas de escala masiva para mi sí son útiles para algo concreto: detectar posibles gaps de visibilidad por topics. Si Ahrefs te muestra que tu competidor aparece en en un cluster de prompts sobre "software de contabilidad para autónomos" y tú no, eso es una señal que merece la pena investigar, independientemente del número exacto de visibilidad. La clusterización por temas permite identificar áreas donde tu contenido no está siendo citado, aunque el "score" absoluto sea arbitrario. En ocasiones he encontrado que el cluster realmente no estaba cubierto o, si lo estaba, tenía problemas accesibilidad o estructura. Puedes leer más sobre esto aquí:
- Trocear contenido para IA y SEO
- Agentes web y la importancia del HTML semántico y accesible
- Extracción de contenido HTML en LLMs con search tool
- Tráfico agéntico: así navegan los agentes de IA y qué tienes que saber tú
- SEO para IA: Guía práctica para que tu PYME sea citada en los LLM
- No es GEO ni AEO es sólo SEO: cómo hacer SEO para la IA
Pero también es cierto que, si ese topic no estaba cubierto, lo podrías habrías detectado haciendo un keyword GAP de toda la vida. Ahora bien, hay un caso donde estas herramientas sí aportan algo que el keyword gap tradicional no puede y es cuando la cita no proviene de tu dominio, sino de un tercero que te menciona.
Mira este ejemplo: para la query "mba abroad" desde India, IESE aparece mencionado en el AI Overview. Pero si revisas las 9 fuentes citadas, ninguna es iese.edu, son sitios de terceros que mencionan a IESE en sus rankings o comparativas.
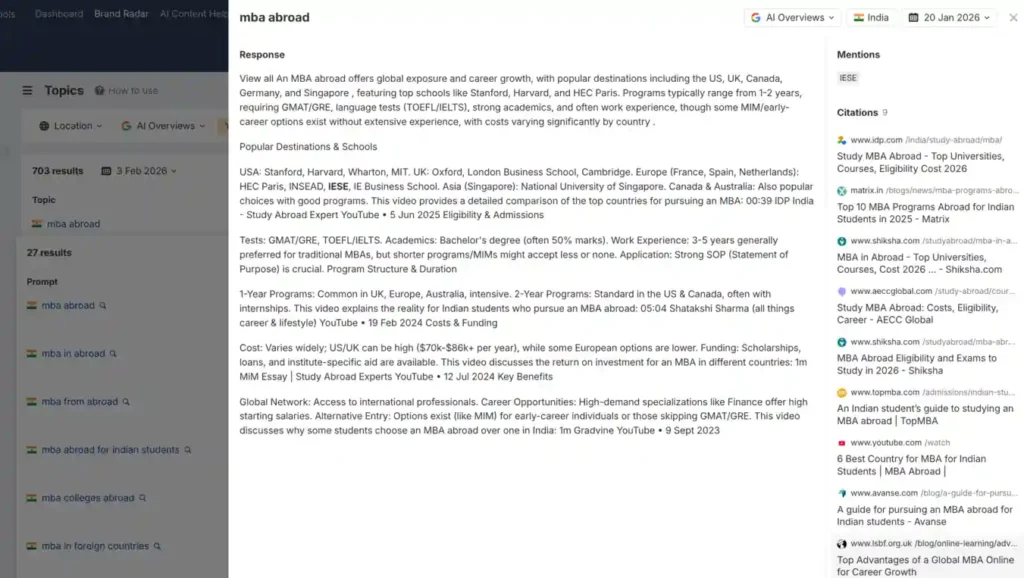
Esto significa que la visibilidad de IESE en este contexto depende de su reputación en el ecosistema, no de su propio contenido. Un gap de keywords comparando iese.edu contra esade.edu nunca te mostraría esto, porque estás comparando URLs propias, no menciones externas.
En ese sentido, estas herramientas funcionan más como un monitoreo de menciones contextualizado por intent que como un análisis SEO clásico. Te permiten ver dónde tu marca aparece (o no) en el "grafo de conocimiento" que el LLM ha construido a partir de múltiples fuentes y no solo de tu sitio.
Herramientas como Sistrix o Ahrefs también permiten monitorizar tus propios prompts personalizados. A mí personalmente no me resulta útil por las razones que he explicado, pero seamos realistas: siempre hay clientes a los que el jefe del jefe les pide "el informe de visibilidad de X prompts". Aunque sepas que las métricas absolutas no son fiables, al menos con estas herramientas tienes esa necesidad cubierta sin tener que montar algo desde cero.
Además me gusta su honestidad:
- SISTRIX reconoce que "la situación de datos para análisis LLM/IA son actualmente incluso más desafiantes que en Google o Amazon." Comparan el momento con los "primeros días del análisis de Google". Ofrecen su módulo de IA en beta gratuita sin prometer resultados de optimización. De hecho, el CEO de SISTRIX me confirma que están alejándose del concepto de "single prompt rankings" por carecer de validez estadística por la alta volatilidad y que están trabajando en Prompt Clustering como enfoque estratégico
- Ahrefs Brand Radar documenta sus limitaciones: "No existen datos reales de demanda. Ninguna compañía tiene acceso a datos de volumen de búsqueda reales para ChatGPT." Admiten que "la atribución sigue siendo desafiante, trackear conversiones directas desde menciones de IA es casi imposible."
Datos de primera parte
Antes de Google Search Console, el mercado también dependía de herramientas externas que estimaban rankings y tráfico. La aparición de datos de primera parte no eliminó las herramientas externas, pero sí redefinió su rol porque pasaron de ser la fuente principal a ser complementos para análisis competitivo.
Si Google extiende Search Console a AI Overviews y AI Mode, y OpenAI ofrece algo similar para ChatGPT con search, el valor de las herramientas third-party de tracking se reducirá aún más a lo que ya he defendido, que es al análisis competitivo de gaps por topics a escala masiva, no medición de "tu" visibilidad con prompts sintéticos.
Conclusión
El mercado de herramientas de AI visibility tracking es una industria construida sobre fundamentos cuestionables. Las respuestas de LLMs son, por diseño, probabilísticas y personalizadas (lo opuesto de lo que se necesitaría para una medición precisa).
No argumento que no haya que medir. Argumento que hay que entender qué estás midiendo, con qué limitaciones y a qué escala tiene sentido.
Los rankings son esencialmente aleatorios. El porcentaje de visibilidad agregado puede tener cierta validez si ejecutas suficientes repeticiones, pero las APIs dan resultados diferentes a las interfaces reales, la personalización hace imposible replicar la experiencia del usuario, y ninguna herramienta tiene acceso a las búsquedas reales que hacen los usuarios en chatbots LLM. Los procesos internos de chatbots IA como el de Google (query fan-out, reranking, SAGE) son técnicamente imposibles de replicar desde fuera, la mayoría de herramientas no distinguen entre conocimiento interno y retrieval (algo que determina si puedes actuar o no), y el % de visibility es paradójicamente más estable para las marcas que ya son conocidas y menos lo necesitan.
Con márgenes brutos del 85-95%, el valor que capturan los vendors supera con creces el que entregan a los clientes. Este mercado vende certidumbre donde solo existe incertidumbre. Quien compre estas herramientas debe saber que está adquiriendo indicadores débiles y para nada verdades absolutas.