Cada vez que un nuevo concepto o sigla asoma en el mundo del marketing digital, GEO, AEO, LLMO, GAIO, LSO, LEO, etc. el debate gira en torno a si estamos ante una verdadera revolución o si es la misma estrategia de siempre con otro nombre. Mi experiencia es que la optimización para grandes modelos de lenguaje (LLMs) es, en esencia, la evolución lógica del SEO de toda la vida.
En este artículo repaso cómo adaptamos las técnicas de SEO para que motores como ChatGPT (o cualquier LLM) nos tengan en cuenta en sus respuestas. Y la clave, al final, sigue siendo la misma: contenido bien estructurado, legible y confiable.
1. El crecimiento del tráfico proveniente de las IA y su mayor conversión
El tráfico proveniente de los LLM convierte más. Comparto algunos datos que reflejan por qué conviene no perderlo de vista :
- Kevin Indig analizó más de 7 millones de sesiones (en ChatGPT, Copilot, Gemini, Perplexity, etc.) comparándolas con Google Search. Concluyó que la media de permanencia en página de un clic procedente de un chatbot es de casi 10.4 minutos, frente a los 8.1 minutos de Google. Además, la gente ve más páginas por sesión y está más predispuesta a comprar o contratar un servicio.
- Andrea Volpini compartió en X un caso donde el tráfico procedente de IA tenía una tasa de conversión del 1.378% frente al 0.201% del tráfico orgánico de Google. Eso es casi 7 veces más en conversiones. Comprobando con mis clientes he visto lo mismo, es un tráfico mucho mejor que el del resto de canales.
- Ahrefs: el tráfico proveniente de búsqueda por IA (ChatGPT, Copilot, Gemini…) representa solo el 0,5 % del total, pero genera el 12,1 % de los leads en los últimos 30 días. Esto significa que convierte unas 23 veces mejor que el tráfico orgánico tradicional.
- Vercel: aproximadamente el 10 % de sus nuevos registros provienen de ChatGPT, frente al 4,8 % del mes anterior y al 1 % de hace seis meses, lo que evidencia una fuerte tendencia al alza del tráfico AI en conversión
Es decir, no solo crece el uso de chatbots o “LLMs con interfaz de búsqueda,” sino que los pocos clics que generan parecen estar muy "cualificados" para convertir. No tiene ningún misterio, la razón es que llegan más preparados, porque ya han pasado por un proceso de exploración más profundo en la conversación con el LLM. Súmale que son queries más largas y complejas, por lo que están más "acotadas".
Esto te hace pensar: “¿Estoy preparando mi web para aparecer en las respuestas de la IA?”
2. Cómo aparecer en las “AI Overviews” y en los chatbot LLM
Antes de nada, debemos de distinguir dos escenarios en los que un LLM puede mostrar tu contenido:
-
Respuesta “desde la memoria del modelo”: En este caso, el LLM se entrenó previamente con una gran cantidad de textos (posiblemente incluyendo parte de tu contenido o del contenidos de otros hablando de ti) y, cuando genera una respuesta, lo hace “desde su memoria”, basado en patrones, sin acudir a fuentes externas en ese momento. Este escenario se parece a cuando alguien estudia un libro y, tiempo después, te explica un concepto sin necesidad de consultar nada. El modelo combina lo que aprendió, pero no necesariamente cita la fuente original. Eso sí, los grandes LLM se entrenan en "cortes" de la web, si tu empresa es nueva, no aparecerás hasta el siguiente ciclo (siempre y cuando hayas trabajado el Digital PR en sitios autoritarios).
-
Respuesta en la “fase de inferencia”: Aquí, el LLM no se limita a su conocimiento interno. En la fase de inferencia (el momento en el que el chatbot genera la respuesta), el modelo busca en fuentes externas para complementar o actualizar la información. Esto suele hacerse con técnicas como RAG, donde el sistema consulta bases de datos o páginas web y luego integra esos fragmentos a la respuesta final. Es en esta segunda modalidad donde tienes más opciones de ser citado directamente (o enlazado) porque el modelo “lee” el contenido actual de tu web y lo incluye explícitamente en la respuesta, en lugar de fiarse solo de su entrenamiento previo.
2.1 ¿Qué es GEO y en qué se diferencia del SEO?
Spoiler: en nada. GEO, de Generative Engine Optimization, es un término que define la manera de optimizar contenido para motores de búsqueda impulsados por IA generativa, originariamente pensado para Google SGE / AIO o Bing Chat. El concepto fue acuñado en el paper GEO: Generative Engine Optimization de Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, y Ameet Deshpande (2023).
Esta fue mi respuesta a aquello:
2.1.1 "GEO" en la práctica
Entre las técnicas que se proponen en paper para GEO destacan:
- Citar fuentes: Agregar citas y referencias claras de fuentes confiables aumenta la credibilidad y, por ende, la visibilidad en las respuestas generadas.
- Añadir citas: Incluir citas textuales relevantes refuerza el impacto del contenido, lo cual se traduce en un mayor “peso” en las respuestas.
- Añadir estadísticas: El uso de datos cuantitativos refuerza el carácter autoritario del contenido.
- Optimización de fluidez y claridad: Mejorar la legibilidad y la coherencia del texto resulta fundamental para que los LLMs interpreten correctamente la información.
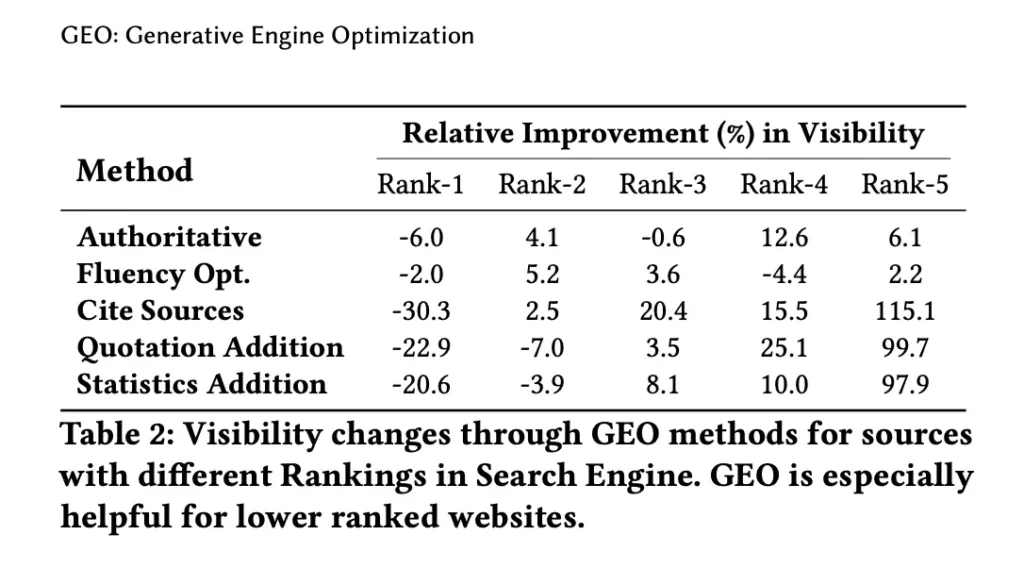
Técnicas GEO (Generative Engine Optimization)
Esto coincide bastante con lo que yo hacía para featured snippets. Lo que llevo haciendo años consiste en tratar de imitar, a muy bajo nivel, cómo funcionan los buscadores internamente:
- Fase de selección de candidatos (ranking inicial): Uso similitud de coseno, BM25, TF-IDF o Token Set Ratio de top performing query con la meta title y h1 para detectar qué landings tienen más potencial de mejora y optimizo las metas para que obtener un mejor score.
- Fase rerank: Creo varias versiones del texto hasta dar con la que mejor score de relevancia devuelve para N queries de esa landing con una versión destilada de Bert entrenada para Q&A. En estas versiones aprovecho las técnicas que en paper anterior se mencionan, que ya eran conocidas por su influencia en direct answers.
Básicamente, si ya optimizas un texto para que Google lo muestre en destacados, estás muy cerca de lo que se hace para SGE / AIO. Durante años, la primera página de resultados de búsqueda ya ha estado siendo ordenada por algoritmos de machine learning (en qué es un buscador híbrido te explico la razón), y algunos parece que no se han dado cuenta de esto todavía.
«Si estás optimizando para búsqueda, entonces en cierto modo también estás optimizando para las AIO y el AI mode», en referencia al grounding – John Mueller, Google (2025).
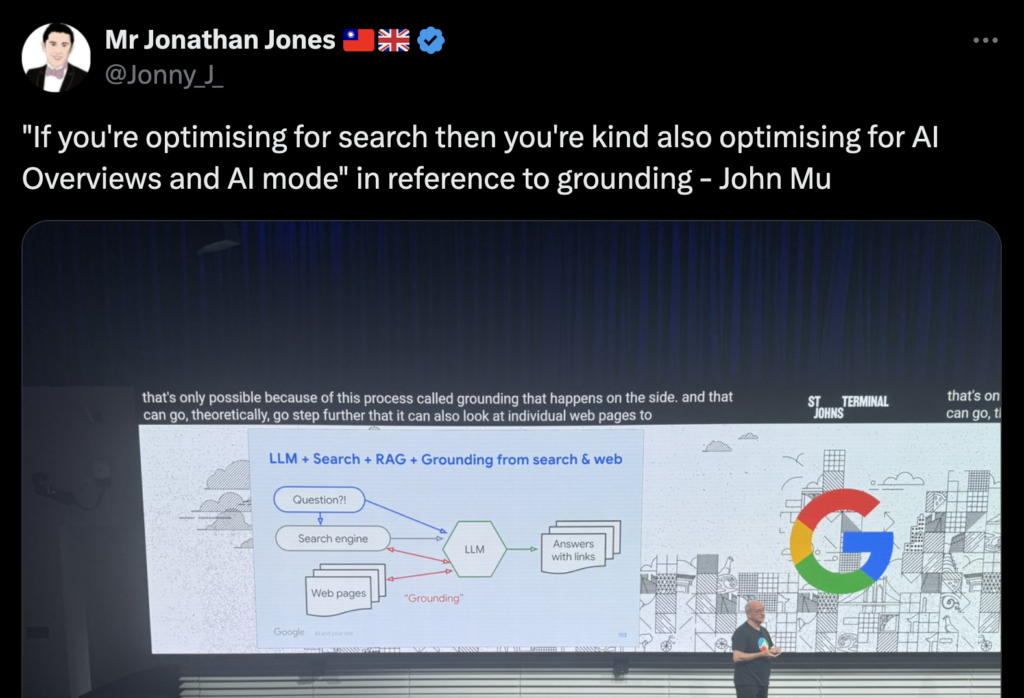
La diferencia es que un LLM en fase de inferencia no sólo extrae un fragmento, sino que “fusiona” y “reordena” la información de varias fuentes para dar la mejor respuesta. Recordemos que los modelos de IA no funcionan como Google Search. No rastrean la web en tiempo real, sino que se entrenan con corpus previos y luego, durante la inferencia, pueden usar RAG (Retrieval-Augmented Generation) para complementar con datos actualizados.
2.3 Factores clave para la visibilidad en LLM en fase de inferencia
Para reforzar la idea de que “no es nada nuevo, es sólo SEO”, te interesará ver lo que hace la gente de Jina AI con su DeepSearch.

Snippet selection and url ranking in deepsearch deepresearch
Han compartido cómo seleccionan snippets y priorizan URLs para mostrar en su buscador. Aunque se perciba como algo avanzado o distinto, en realidad los factores y técnicas que usan Jina, ChatGPT, AI Mode, Perplexy, Claude... no difieren mucho de un buscador tradicional como vamos a ver a continuación.
2.3.1 SEO para la IA
- Freshness: fecha de última actualización (via headers HTTP, fechas visibles o Schema.org). En este caso, Jina AI usa Schema.org únicamente para consultar la fecha. Aunque sabemos que los los datos estructurados como Schema.org, no afectan al entrenamiento de un LLM (los LLM se entrenan con texto plano), sí podrían ayudar en “grounding” o la integración con RAG como en este ejemplo (siempre y cuando no sean removidos como ocurre con el resto de IAs ). Vamos, cuanto más clara tu estructura de datos, mejor para que la IA entienda y cite de forma confiable. Además, creo que en futuro de tráfico agéntico, esto tendrá más sentido así como el contenido estructurado vía feeds. Otra cosa que podemos hacer en este punto es asegurarnos que los contenidos sean actualizados al momento cuando cambien (sitemaps.xml, index now...) y los que necesiten de "frescura" preocuparnos de tenernos al día como veníamos haciendo. Eso sí, la frescura del contenido juega un papel indispensable, pero de forma diferente según el modelo. Investigaciones recientes muestran que ChatGPT y Claude prefieren citar páginas con 3 a 10 meses de antigüedad, mientras que Perplexity y Gemini son mucho más sensibles a actualizaciones recientes, favoreciendo fuentes de los últimos 30-45 días. quí viene lo interesante: estos modelos no "comprenden" realmente la temporalidad. En pruebas controladas donde se manipularon las fechas visibles en artículos antiguos (cambiando textos como "Updated: October 2025"), ChatGPT y Claude aceptaron las fechas falsas en el 70-80% de los casos, Perplexity en ~55%, y solo Gemini mostró más resistencia (~35%). Los modelos leen las fechas como texto, no como hechos verificables.
- Frecuencia y autoridad del dominio: Si múltiples fuentes referencian ese contenido y esos dominios son relevantes. Cuando hacemos link building, ¿no tratamos de conseguir enlaces de los sitios que ya rankean para búsquedas determinadas? Para la IA, lo que hacemos es tratar de aparecer en referencias citadas por los LLMs. Si no podemos ser la fuente primaria, al menos debemos estar en los sitios que estas IA consultan, que suelen ser los que están arriba en los índices de buscadores. Además, hay un nuevo factor que podría influir directamente en la visibilidad dentro de los modelos de lenguaje: los acuerdos con proveedores de contenido. OpenAI ha firmado partnerships con medios como Financial Times, Le Monde, The Atlantic, Axel Springer (dueño de Politico, Business Insider...), The Guardian, PRISA Media (dueño de El País, AS, Cinco Días...), News Corporation (The Wall Street Journal, The Times...), entre otros. Esto significa que los contenidos de estos medios tienen mayor probabilidad de aparecer en respuestas de ChatGPT, ya sea a través de citas directas, resúmenes o enlaces. ¡Digital PR! Además, un análisis reciente de más de 1.000 consultas confirma que los modelos de IA tienen una clara preferencia por fuentes "earned" (reseñas, artículos de prensa, comparadores) frente a contenido de marca o redes sociales. Lo interesante es que cada IA muestra sesgos de citación diferentes: Claude tiende a reutilizar los mismos dominios independientemente del idioma, mientras que GPT-4o varía significativamente sus fuentes según la lengua o el país de consulta. Esto refuerza la importancia de una estrategia de Digital PR diversificada y adaptada a diferentes mercados.
- Estructura del path: URLs organizadas de forma semántica.
- Relevancia semántica: Usan embeddings y modelos de reranking para determinar la relevancia. ¿No es similar al proceso que acabo de explicar arriba? Aquí yo incluiría:
- Lenguaje claro, directo y sin ambigüedades: Facilitad que la IA entienda exactamente lo que quieren comunicar. Evitad la jerga excesiva si no es necesaria para la audiencia. Y algo que siempre ha funcionado muy bien es el responder directamente a la pregunta al inicio de una sección, no en medio ni al final. Ejemplo: ¿Qué es una DANA? Una DANA (Depresión Aislada en Niveles Altos) es un fenómeno meteorológico que ocurre cuando una masa de aire frío se separa de la circulación general, provocando lluvias intensas y tormentas, especialmente en el Mediterráneo español. [Explicación detallada a continuación...]. Este tipo de formato, que funciona muy bien para featured snippets, ha demostrado ser útil también en RAG. No es ningún truco, son matemáticas.
- Riqueza de entidades: Es muy común que los LLMs usen Knowledge Graph en sus pipelines de RAG (GraphRAG), por lo que el uso de entidades relacionadas ayuda a la IA a conectar su contenido con su base de conocimiento (Knowledge Graph). También pueden ser especialmente útiles para el proceso que se explica en el siguiente punto.
- Listas, viñetas y tablas: Son formatos semánticos fácilmente digeribles por la IA y pueden ser utilizados directamente en resúmenes o respuestas.
- Información factual y verificable: Usad datos cuantitativos, estadísticas y afirmaciones claras. Los buscadores en general tienden a preferir las afirmaciones siempre que formen parte del consenso.
- Anchoring relevante: En al documentación de Jina vemos que podrían estar usando el anchor text de los links internos.
- Late Chunking: Jina usa una técnica de RAG con la que seleccionan fragmentos relevantes en docs largos sin perder contexto. Si eres SEO seguro que te suena el Phrase-based indexing de Google. No quiero decir que sean iguales, sólo es un paralelismo conceptual con el SEO de siempre, porque ambos tratan de mejorar la relevancia del contenido recuperado. Phrase-based indexing lo hace con frases que ayudan al ranking de documentos y RAG lo hace buscando chunks relevantes para que el LLM los use como contexto. Mis consejos en este punto son:
- Estructurar nuestros contenidos en párrafos autocontenidos, que puedan ser entendidos sin contexto adicional. Es decir, hacer una cobertura exhaustiva (en fragmentos bien definidos) ayuda a estos sistemas. Por ejemplo, abordando preguntas relacionadas y subtemas dentro de los artículos. Esto es especialmente relevante para cubrir el "Query Fan-Out". Ejemplo: Un artículo sobre "Agujeros Negros" podría tener secciones sobre "¿Qué son?", "¿Cómo se forman?", "Tipos", "Imágenes", "Cómo se detectan", etc.
- Los encabezados claros y jerárquicos (H1, H2, H3) ayudarían a la IA a entender la estructura y la importancia relativa de cada sección. Las encabezados Hx no son sólo importantes para SEO, el html semántico y la accesibilidad también son importantes para los agentes y asistentes web.
- Cada IA usa chunks de tamaños y con overlaps diferentes de los cuales no conocemos su tamaño, así que no no te obsesiones con esto, no vas a sacar nada en claro y puede hacerte más daño que bien.
- Accesibilidad del contenido: Si tu contenido está detrás de paywalls, mala suerte: la IA no podrá acceder a él (o violaría los ToS). Otra vez más, nada nuevo porque los bots no indexan lo que no está accesible. También hay que tener en cuenta que muchos ChatBots no renderizan JS todavía.
Todo esto sigue siendo SEO (te reto a que me digas algo que sea nuevo) y las acciones de SEO semántico se deberían haber estado haciendo desde 2013. Algunos llevamos desde esa época gritándolas a los cuatro vientos, pero pocos nos han escuchado. Hummingbird (2013), enlaces implícitos y citaciones de marca (2014, patente relacionada con Panda), Rankbrain (2015), Phrase-based indexing (patente del 2009, pero actualizada en 2018), Information Gain (2018), Bert (2018), MUM (2021), HCU (2022)... Insisto, el proceso que he explicado antes que ya funcionaba para featured snippets (2014) sigue funcionando para las AI Overviews. Ahora son muchos los que se suman al carro, pero estoy viendo que se está haciendo de forma bastante mediocre y malentendiendo los fundamentos. Lo que está claro es que el retorno de estas acciones ha sido cada vez mayor, y la nueva realidad de la IA generativa no ha hecho más que consolidarlas por que vamos a ver a continuación.
2.3.2 Cómo “entiende” un LLM: Monosemanticidad y desambiguación
Los modelos de IA trabajan en lo que llaman monosemanticidad. Hay “neuronas” que se activan cuando el modelo detecta un concepto muy concreto, por ejemplo, “dirección de correo electrónico” o “nombres de ciudades.” La idea la explica un estudio reciente de Anthropic y se asemeja de nuevo al viejo concepto SEO semántico de “entidades” y “desambiguación”.

Monosemanticidad
A su vez, los modelos almacenan “hechos” en sus capas internas. Típico ejemplo: Michael Jordan → Basketball. Esa asociación se graba en la red, específicamente en los multi-layer perceptrons (MLPs).
Aunque haya neuronas específicas, no es tan sencillo: a veces se mezclan varios conceptos en “superposición”. Por eso interpretar un LLM es complejo, pero nos da una pista de cómo optimizar: haz tu contenido lo más “inequívoco” posible para el modelo.
En definitiva, si queremos que los LLM nos tengan en cuenta en su corpus, es decir, que comprendan quiénes somos y qué hacemos, lo que debemos hacer es explicar mejor el contenido, sin ambigüedades. De la misma forma que hacemos para cualquier otro buscador trabajando la semántica.
2.4 Los buscadores con IA tienen un problema con las citas y por qué debería importarte como SEO
Como sabemos, los modelos generativos de IA, incluyendo el nuevo GPT-4.5 de OpenAI, a menudo sufren del conocido fenómeno de las "alucinaciones", generando respuestas que, aunque pueden parecer muy convincentes, son incorrectas o completamente inventadas. Por ejemplo, este último, sigue alucinando en más de 1 de cada 3 preguntas. Eso sí, es un gran avance respecto a versiones anteriores. Para ponerlo en contexto frente a GPT-4o:
- Alucina menos: GPT-4.5 solo "se inventa" respuestas en el 37.1% de los casos en SimpleQA, frente al 59.8% de GPT-4o.
- Sabe más: GPT-4.5 acierta el 62.5% de las preguntas en SimpleQA, un salto enorme desde el 38.6% de GPT-4o.
Pero, cuando hablamos de citas, la cosa es mucho más preocupante.
Un estudio reciente del Tow Center for Digital Journalism confirmó que este no es un problema exclusivo de OpenAI, sino generalizado entre los motores de búsqueda generativos. Tras evaluar 8 buscadores de IA (incluyendo ChatGPT, Gemini, Perplexity, Grok y Copilot), concluyeron que todos tenían serias dificultades para citar correctamente las fuentes, con tasas muy preocupantes de respuestas incorrectas o enlaces inventados. Algunos datos:
- Más del 60% de las respuestas fueron incorrectas.
- Las versiones premium fallan con más frecuencia y con más confianza que las gratuitas.
- Chatbots como Gemini y Grok 3 se inventan las URLs, lo que no permite verificar las fuentes. Gemini, sí, el que ahora usan también para el AI Mode…
- Muchos de ellos ignoran el robots.txt y acceden a contenido bloqueado por medios.
Otra cosa curiosa, los acuerdos de licencia con medios tampoco garantizan precisión en las citas ni respeto total a las restricciones de rastreo.
Esto no acaba aquí. Otro estudio independiente de la BBC casa con lo que acabamos de mostrar. Más del 50% de las respuestas de asistentes como Gemini, Perplexity, ChatGPT o Copilot contenían errores significativos, incluyendo distorsiones de citas, datos erróneos y enlaces rotos. Lo más alarmante es que cuando mencionan marcas confiables como la BBC, el usuario tiende a confiar más en la respuesta, aunque sea falsa. Otro motivo más para tomarse muy en serio este problema.
Seguramente habréis visto en vuestras analíticas que mucho del tráfico que traen estos bots aterrizan en una página 404, si no os animo a comprobarlo. ¿Qué hacer en estos casos?
Google ya está avisando que este fenómeno podría aumentar en los próximos meses. ¿Qué hacer entonces con esos enlaces alucinados que generan errores 404? Mueller recomienda tener una buena página de error personalizada que explique qué ha pasado. Incluso propone usar esa URL como una búsqueda interna para intentar reconducir al usuario a lo que estaba buscando.
Pero también se están proponiendo soluciones más creativas, como por ejemplo, añadir un mensaje en la propia 404 dirigido explícitamente a quienes llegan desde un enlace generado por IA, explicando que es una alucinación y que el sitio ha sido actualizado para advertir de ello.
¿Redireccionar estos enlaces? No es mala opción. Si son muchos, puede no compensar, aunque se me ocurren formas de hacerlo de forma auto por similitud semántica. Pero si eres una marca pequeña, cada clic cuenta.
Aun así, esto va a dar guerra, así que mejor empezar a monitorizar bien esas URLs fantasma, su impacto y cómo corregirlo. Igualmente, nada nuevo si eres SEO 🙂
3. Resumiendo: El SEO para IA sigue siendo SEO tradicional
La evidencia técnica muestra una superposición masiva en las fases de rastreo, indexación y servicio tanto en Search, como en AI Mode / AI Overview, como en Gemini. Es decir, las funcionalidades de Google con IA utilizan los mismos crawlers y se benefician de las mismas tecnologías de indexación que ya analizan el contenido, como BERT. Y, el momento de servir los resultados, estas nuevas características se construyen sobre la misma base de cientos de señales, añadiendo capas adicionales que se apoyan y fundamentan en el índice de búsqueda existente.

Lo único que cambia en AI Mode / AI Overview y el grounding sobre el search index (donde funciona la misma optimización que para los featured snippets) y el query fan-out (una la evolución del query augmentation que es a su vez una evolución del query expansion). No hubo que cambiarle el nombre al SEO cuando el MFI, ni para los featured snippets, ni para los datos estructurados, ni para redes sociales, etc.

Al final, resulta que estamos haciendo SEO para la IA y no lo sabíamos. Cuando aparecen términos como AEO, LLMO, GEO, GAIO, LSO o LEO, puede parecer que todo ha cambiado. Pero lo esencial se mantiene: sigue siendo un juego de relevancia, autoridad y accesibilidad. La diferencia es cómo el modelo consume e interpreta esa información para devolverla en formato de respuesta y, para nosotros, no cambia la forma de trabajar.
Relacionado:
Por qué trocear tu contenido es malo para tu SEO y para la IA
SEO Local para ChatGPT
Lo que los leaks de ChatGPT nos enseñan sobre SEO para la IA