Foursquare anunció su asociación con OpenAI en febrero de 2025 para alimentar las búsquedas locales en ChatGPT a través de su Places API. Desde entonces, su base de datos, que incluye más de 100 millones de puntos de interés en más de 200 países, se ha convertido en una de las principales fuentes utilizadas por el modelo para responder consultas del tipo local. A raíz de este anuncio, quise comprobar en qué medida influye esta integración en los resultados de búsqueda de negocios para poder aprovecharlo en SEO local.
Así que, el objetivo de este análisis es medir cuánto y cómo influye Foursquare en las respuestas locales de ChatGPT, inspeccionando los JSON internos que genera el modelo cuando decide “salir a buscar” respuestas y no depender de la memoria.
Metodología
Para ello, he analizado las respuestas JSON de 50 prompts para restaurantes, cerrajeros y floristerías en Málaga, Barcelona, Valencia, Teruel y Mérida.
He escogido diferentes localidades porque la cobertura de Foursquare depende de la densidad urbana, lo cual es obvio. En un estudio se cruzaron recuentos de venues Foursquare con censos de población y se encontró una correlación casi lineal entre densidad de población y densidad de POI. A más habitantes/km², más lugares registrados en la API. Es decir, aunque Foursquare presume de 100 M de puntos de interés globales, la distribución no es homogénea. Por ejemplo, megaciudades de USA o EU concentran miles de fichas, mientras que en municipios pequeños abundan los “huecos” (venues inexistentes o con datos incompletos).
TLDR
Si no quieres leer el post entero, quédate con esto: entre el 60 % y el 70 % de los negocios que ChatGPT muestra en primer lugar provienen de Foursquare… y también suelen ser la mayoría en el bloque de resultados. O lo que es lo mismo: estar en Foursquare es prioritario si quieres hacer SEO local en ChatGPT, especialmente en localidades pequeñas o para negocios nicho. Y sí, hablo de SEO, porque esto no es GEO, ni LLMO, ni GAIO, ni LSO, ni LEO. Es, simple y llanamente, mejorar tu visibilidad allá donde están tus usuarios.
Como curiosidad, Yago Vázquez también ha estado analizando esta información y os dejo aquí a su post para completar con este.
1. Flujo de orquestación y triger de la búsqueda
| Qué ocurre |
Detalle técnico |
| 1. Prompt del usuario |
Llega como un nodo role:“user” en el árbol mapping. |
| 2. SONIC puntúa la query |
El orquestador ejecuta SONIC sobre el texto. Si search_prob ≥ 0.54 se marca la solicitud como que “requiere búsqueda”. |
| 3. Llamada a web.search |
GPT‑4o genera un mensaje role:“assistant” → recipient: “web” cuyo único contenido es search(“query original”).
La query se “normaliza” antes de la llamada, pero no la hace el LLM, la limpieza (lowercase, acentos...) la hace el servicio web.search internamente. |
| 4. Respuesta de web.search |
Llega otro nodo oculto (role:“tool”) con un JSON único que incluye varias secciones: businesses_map + business_fallbacks, image_results, search_result_groups / grouped_webpages, safe_urls, blocked_urls, moderation_results... |
| 5. Redacción final visible |
GPT‑4o toma el JSON y construye el mensaje dirigido al usuario. Inserta los bloques estructurados anteriores.
Todos los bloques citan la misma búsqueda con IDs tipo turn0search0, turn0search1… de modo que es trazable a la SERP original.
El texto libre se añade antes/después de esos bloques. |
| 6. Modelo bloqueado para otros slugs |
Como la conversación ya usa la herramienta, el JSON incluye model_switcher_deny para impedir que futuros “regenerate” cambien a modelos que no soportan herramientas (o1, o1‑mini...). |
Observaciones
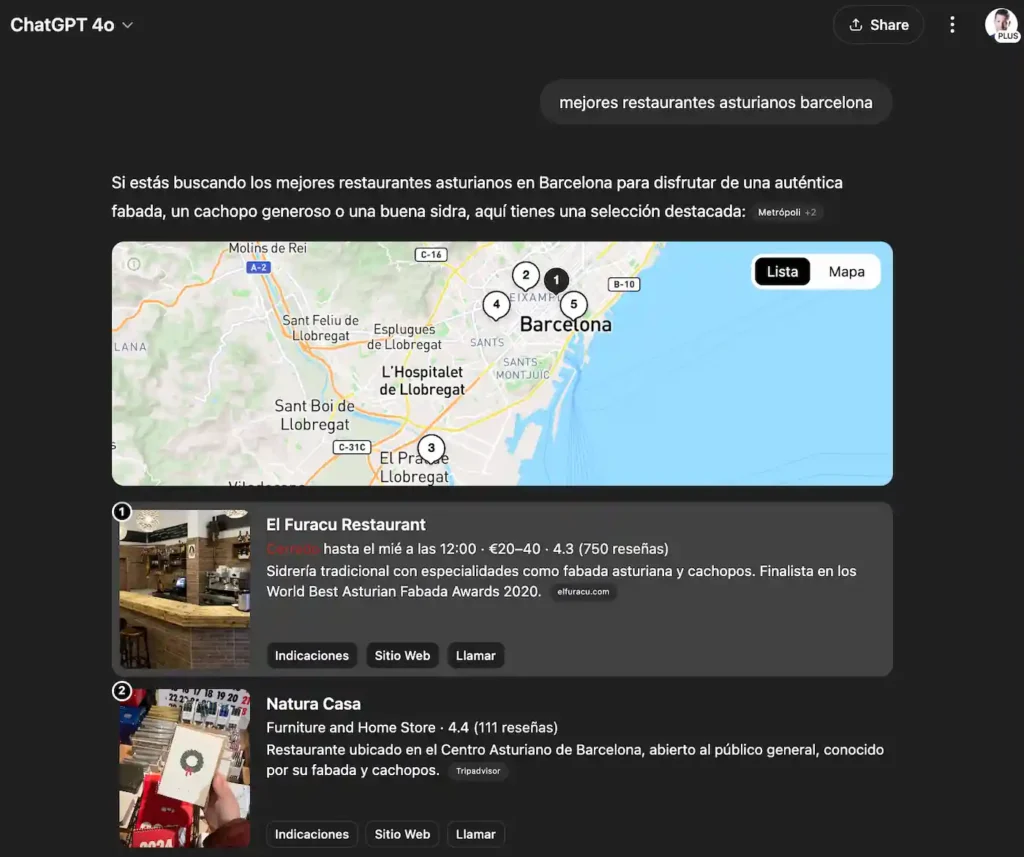
Aquí tenéis un ejemplo de su clasificador de queries, llamado "SONIC" que usa para llamar a la herramienta search. En este caso, para la consulta "mejores restaurantes asturianos barcelona" ha estado a punto de tirar de la memoria y no de la herramienta de búsqueda porque probabilidad era de 0,58, ligeramente superior al límite establecido de 0,54.
"status": "finished_successfully",
"end_turn": null,
"weight": 1.0,
"metadata": {
"sonic_classification_result": {
"latency_ms": 0.021952670067548752,
"search_prob": 0.5875909485626426,
"force_search_threshold": 0.54,
"classifier_config_name": "sonic_force_pg_switcher_renderer_config"
}
}
La orquestación obliga a que las llamadas con herramientas se ejecuten con GPT‑4o. Todos los mensajes ligados a web.search llevan model_slug = gpt‑4o y el JSON incluye un model_switcher_deny que bloquea o1, o1‑mini y otros slugs para búsquedas.
"model_switcher_deny": [
{
"slug": "o1",
"context": "regenerate",
"reason": "unsupported_tool_search",
"is_available": true,
"description": "This model doesn't support search."
},
{
"slug": "o1",
"context": "conversation",
"reason": "unsupported_tool_search",
"is_available": true,
"description": "This model doesn't support search."
}
]
2. Fuentes y proveedores detectados
- En businesses_map
- foursquare (fichas locales con ID hash): mayoría de entradas y casi siempre de las primeras en mostrarse.
- serp (scraping directo de la SERP): para negocios sin ficha Foursquare.
- En image_results: Hay consultas que activan imágenes con URL original, thumbnail y dominio de atribución. Normalmente de la CDN de Foursquare (fastly.4sqi.net) y Bing thumbnails.
- En grouped_webpages / search_result_group: Listas de snippets agrupados por dominio. Son snippets orgánicos (TheFork, Yelp, TripAdvisor, Bodas.net...). Cada URL que se mostrará al usuario pasa primero por la lista blanca safe_urls.
- En business_fallbacks: se generan al vuelo con los mismos resultados que devolvió la búsqueda y con links a Google Maps.
Observaciones:
ChatGPT no hace re‑ranking (ni por rating, alfabeto, horario de apertura…). El array businesses_map suele comenzar con entradas cuyo provider es foursquare y la complementa con las de tipo serp (scraping directo). La hipótesis creo que es por latencia porque la búsqueda general de la SERP requiere de más milisegundos. Cuando ambas corrientes de datos llegan, se concatenan en el orden de recepción, sin re‑ordenar ni fusionar. Es cierto que el array llega “tal cual”. Pero en algunos tests (~10 %) veo que Foursquare entrega >20 venues y el modelo recorta a los 10 primeros antes de pintarlos. Es, técnicamente, un “hard cut” más que un re‑ordenado.
De ahí que los elementos Foursquare aparezcan casi siempre primeros en la lista. Porque su fuente devuelve antes los documentos y “gana” esa carrera de latencias. No implica un score de relevancia superior, sino la prioridad temporal con la que el pipeline agrega los resultados. Además, no hay deduplicación, un mismo negocio puede repetirse varias veces en el mismo array si proviene de fuentes distintas con NAP inconsistentes. Lo cual puede ser bueno para hacer SPAM.
Por ejemplo, para "floristerías para bodas en Teruel", el venue_id de Foursquare aparece dos veces con descripciones distintas (GPT rellenó 2 textos usando fuentes diferentes):
{
"id": "9b66c20692eb9d5e6394fa75",
"name": "Floristería",
"description": "Con una calificación de 5.0, esta floristería se especializa…"
},
{
"id": "9b66c20692eb9d5e6394fa75",
"name": "Floristería",
"description": "Fundada en 2001, cuenta con una valoración de 5.0 y ofrece…"
}
Y luego en el fallback, una ficha Foursquare dentro de businesses_map y, unos milisegundos después, el fallback generado a partir del resultado orgánico de Bodas.net.
/* businesses_map (provider = foursquare) */
{
"id": "9b66c20692eb9d5e6394fa75",
"provider": "foursquare",
"name": "Floristería", // nombre genérico
"address": "Avenida de Aragón, 12, 44002 Teruel Aragón",
"latitude": 40.3330899,
"longitude": -1.1038829
...
}
/* business_fallbacks (plan B) */
{
"name": "Floristería Ideas", // mismo local → naming distinto
"location": "Teruel",
"url": "https://www.google.com/maps/search/Florister%C3%ADa+Ideas%2C+Teruel",
"cite": "turn0search0"
}
Sobre business_fallbacks veo que son el plan B. Cada entrada lleva un campo cite ( ej. cite:turn0search9 ) que apunta a uno de los IDs internos que el tool asigna a los resultados de la SERP. En el mismo objeto vemos cómo ese ID se resuelve en cite_map con el título y la URL originales del resultado orgánico. A partir de ese título el asistente construye un enlace de tipo “búsqueda en Google Maps”: https://www.google.com/maps/search/<nombre_del_negocio>,<ciudad>,<país> (ejemplo: “Cerrajero Málaga ‑ Profesionales Málaga” → link a Google Maps). Es decir, es un search URL, no una ficha con Place ID.
La propiedad render_fallbacks, decide si el front‑end los muestra. En la mayoría de prompts viene false:
"business_fallbacks": [
{
"name": "Cerrajeros Málaga",
"location": "Málaga, España",
"description": "Ofrecen servicios de cerrajería 24 horas con precios desde 39€. Realizan aperturas de puertas, cambios de cerraduras y más.",
"cite": "turn0search0",
"url": "https://www.google.com/maps/search/Cerrajeros+M%C3%A1laga%2C+M%C3%A1laga%2C+Espa%C3%B1a"
},
{
"name": "Cerrajeros Málaga 24h",
"location": "Málaga, España",
"description": "Servicio urgente con desplazamiento gratuito en un máximo de 25 minutos. Precios desde 39€ y más de 15 años de experiencia.",
"cite": "turn0search1",
"url": "https://www.google.com/maps/search/Cerrajeros+M%C3%A1laga+24h%2C+M%C3%A1laga%2C+Espa%C3%B1a"
},
{
"name": "Cerrajeros Málaga Baratos",
"location": "Málaga, España",
"description": "Empresa con más de 30 años de experiencia. Ofrecen servicios de cerrajería económica, incluyendo aperturas y cambios de cerraduras.",
"cite": "turn0search4",
"url": "https://www.google.com/maps/search/Cerrajeros+M%C3%A1laga+Baratos%2C+M%C3%A1laga%2C+Espa%C3%B1a"
},
{
"name": "Soluciones González",
"location": "Málaga, España",
"description": "Cerrajeros disponibles 24 horas todos los días del año. Llegan en 20 minutos y ofrecen precios competitivos.",
"cite": "turn0search5",
"url": "https://www.google.com/maps/search/Soluciones+Gonz%C3%A1lez%2C+M%C3%A1laga%2C+Espa%C3%B1a"
},
{
"name": "Cerrajeros Málaga AC",
"location": "Málaga, España",
"description": "Brindan servicios de cerrajería las 24 horas, incluyendo apertura de puertas, cambio de cerraduras y más.",
"cite": "turn0search10",
"url": "https://www.google.com/maps/search/Cerrajeros+M%C3%A1laga+AC%2C+M%C3%A1laga%2C+Espa%C3%B1a"
},
{
"name": "Cerrajeros Málaga",
"location": "Málaga, España",
"description": "Realizan aperturas de puertas desde 30€ y ofrecen instalación de cerraduras de seguridad.",
"cite": "turn0search11",
"url": "https://www.google.com/maps/search/Cerrajeros+M%C3%A1laga%2C+M%C3%A1laga%2C+Espa%C3%B1a"
}
],
"render_fallbacks": false
Veo que también existe una doble capa de seguridad antes de mostrar cualquier enlace, imagen o fuente externa al usuario:
- moderation_results + blocked_urls: Esta primera capa actúa como un filtro de exclusión. Evalúa todo el contenido devuelto por la herramienta web.search antes de que llegue al modelo.
- moderation_results identificaría riesgos de Trust & Safety (como violencia, contenido sexual...).
- blocked_urls es una lista negra dinámica que elimina dominios considerados peligrosos o no permitidos (por ejemplo, por infracciones de copyright, malware , spam...).
- safe_urls: La segunda capa funciona como una lista blanca. Solo se renderizan en la interfaz final (con miniaturas o enlaces clicables) las URLs explícitamente incluidas en este listado aprobado. Si una URL no está en safe_urls, el contenido puede mostrarse como texto plano, pero sin imagen ni enriquecimiento visual.
3. Recomendaciones de SEO local para ChatGPT
Después de haber analizado el flujo de orquestación, las fuentes involucradas y cómo se presentan los resultados en su interfaz, veamos qué consejos prácticos se pueden extraer para optimizar la visibilidad local de un negocio dentro de ChatGPT.
- Tener ficha en Foursquare es la prioridad número 1 para SEO local en ChatGPT. La mayoría de negocios mostrados provienen de Foursquare y tienden a ser los primeros que salen. Es recomendable mantener la ficha completa (rating, hours, fotos) incrementa la riqueza del bloque businesses_map y la probabilidad de aparecer arriba.
- Datos estructurados completos: Campos vacíos quedan en blanco en la UI de chatGPT. Rellena horario, rango de precios y categorías para destacar frente a los competidores. El flag is_open permite que la UI muestre si el negocio está abierto “ahora”. Mantener horas correctas puede influir en la decisión del usuario.
- Coherencia de NAP y IDs: GPT no deduplica. Si usas variantes de nombre/URL corres "riesgo de canibalizar" tu propio negocio, lo cual puede ser bueno si lo que quieres es hacer el mal.
- Optimiza para la lista blanca: Asegúrate de que tu dominio figure en los resultados orgánicos en (safe_urls). Sitios fuera de esa whitelist no se mostrarán. Haz PR en esos sitio y date de alta en esos directorios.
- Añade imágenes optimizadas: GPT sirve miniaturas directamente de la SERP en 4:3. Por lo que tener en ese ratio aspecto o casi cuadradas minimizaría la porción que se recorta. Estaría bien dejar aire alrededor del motivo principal ya que el recorte es siempre centrado y así se evitaría el corte en textos o logos.
- Crea un clasificador con la probabilidad de SONIC para mejores análisis de keywords: Como con search_prob > 0.54 el sistema va a la web, puedes entrenar tu propio clasificador (simple modelo de regresión o árbol) usando prompts etiquetados con su search_prob para predecir si una query activará búsqueda. Así detectarás de antemano consultas “local‑dependientes” donde interesa posicionarte. O, simplemente, búsquedas que no tiran de la memoria del LLM.
- Auditoría masiva de blocked_urls: exporta esos arrays a lo largo de múltiples prompts para descubrir dominios comúnmente vetados y evitar aparecer con tu negocio en ellos.
Relacionado:
No es GEO ni AEO es sólo SEO: cómo hacer SEO para la IA
Lo que los leaks de ChatGPT nos enseñan sobre SEO para la IA