En este artículo te voy a dar una serie de recursos imprescindibles de SEO semántico muy necesarios si te dedicas al SEO y quieres evolucionar a la vez que lo hacen los buscadores hacia la web semántica. Espero que os resulten útiles y que por lo menos quede claro que el seo semántico es mucho más que estructurar los datos o usar HTML5…
Muchos de los recursos que voy a compartir tienen una complejidad muy superior a la media, pero es que para nuestro trabajo necesitamos saber qué algoritmos usan los buscadores en cada fase o por lo menos una aproximación de los mismos. Peléate con ellos y te prometo que les sacarás mucho partido.
No eres SEO si no sabes cómo funciona un buscador
En el anterior post de entidades ya dije que, según mi opinión, no puedes ser un profesional SEO si no sabes cómo funciona un buscador. Y no hablo del simple hecho de conocer la fases en plan «primero un buscador hace el crawling, luego la indexación y luego rankea en el momento de la query, se lo he visto decir a Matt Cutts en un vídeo»:
Porque saber eso es de primero de SEO (y en este PDF Matt Cutts explica lo mismo para los de primero y medio de SEO). En cada fase los buscadores usan, combinan y mejoran centenares de algoritmos para ser capaces de responder nuestras preguntas. ¿Y te cuento un secreto? los componentes semánticos ya están integrados en todas las fases.
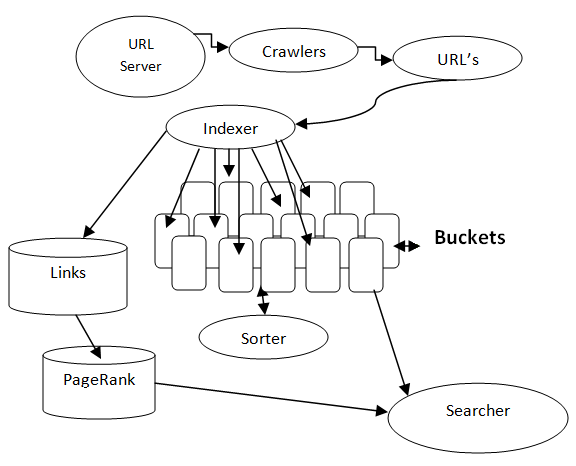
Diagrama básico de un buscador
Al entender cómo los motores de búsqueda usan estos componentes semánticos para extraer, clasificar y recuperar la información consigues una visión distinta y una aproximación más real al verdadero trabajo del SEO a día de hoy.
Este trabajo es cada vez más difícil de parametrizar porque se alinea directamente con las necesidades de información de las personas y de cómo la aplicación de la Inteligencia Artificial en la lingüística es capaz de resolverlas (búsqueda personalizada, predictiva, conversacional y semántica). Lo mismo ocurre a la hora de hacer CRO, donde no existe un checklist al ser cada proyecto diferente.
El SEO ya no es un checklist
Y te lo digo desde la experiencia porque cuando aprendo más sobre los buscadores mejores resultados obtengo y menos voy a ciegas. Por otro lado también te diré que cuanto más estudio, y pongo en práctica lo aprendido, más me doy cuenta que menos sé.

En el pasado he hecho optimizaciones que más adelante me he dado cuenta que en realidad eran sobreoptimizaciones innecesarias y en algunos casos hasta contraproducentes (he pecado padre). También he implementado y quitado cosas simplemente porque aparecen en una lista de factores obtenida por ingeniería inversa, pero que exista correlación no implica causalidad. Y algunos de estos factores son simplemente rumorología que se extiende porque a 1 gurú se le han encendido los chacras.
En España conozco apenas SEOs interesados en la recuperación y extracción de la información (IR y el IE), las verdaderas bases del SEO. Por eso no me había animado a escribir sobre ello hasta ahora, pero viendo la aceptación del post sobre entidades y el SEO creo que hay más interés del que me pensaba.
De las páginas enlazadas a las entidades conectadas
Especialmente la parte de la extracción de la información es cada vez más importante desde la llegada de Hummingbird y coge más fuerza desde la oficialización de Google de su nuevo grafo del conocimiento, el Google Knowledge Vault.
Creo que este anuncio es muy interesante porque es algo de lo que se lleva hablando mucho tiempo, la transformación de Google de un motor de búsqueda a un motor de respuestas. Es un cambio de paradigma en la forma de entender el SEO donde van a tener menos peso los algoritmos centrados en las páginas y sus relaciones que son fácilmente manipulables (PR, HITS, TrustRank, Okapi 25, Tf-idf…).
A medida que vayan evolucionando los métodos de extracción de la información cada vez serán menos necesarias las keywords, los anchors y los links. Luego el marco de trabajo que ha existido cambia por completo.
Semántica en los 3 pilares del SEO
Veamos ahora algunos ejemplos de cómo la semántica está presente en los tres pilares fundamentales del SEO: Autoridad, Contenido y Arquitectura.
Autoridad
Para hacer link builing tienes que saber cómo los buscadores interpretan el linking y anchoring en sus algoritmos, esto va mucho más allá de hacer un simple tiered linkbuilding que ahora se ha puesto de moda (cuando esto se lleva haciendo años) y tirar X porcentaje de variaciones de anchors. Sólo conozco a un bróker de links que tiene en cuenta los conceptos semánticos que usan los buscadores para rankear (y por eso es al único que contrato). ¿Haces link building y nunca te has preocupado por ello? ¿conoces la co-ocurrencia? La relevancia a día de hoy tiene más peso que la autoridad. Te ahorrarías mucho trabajo y disminuirías al máximo las probabilidades de ser penalizado.
Contenido
Para escribir un contenido optimizado no sirve con poner la keyword en los más que conocidos lugares y repetirla porque a día de hoy eso ya no funciona tan bien (y cada vez lo hará menos). Los buscadores se están centrando en las entidades y sus relaciones más que en la propia keyword. Con esto quiero decir que puedes hacer un artículo mucho más relevante para el buscador hacia un topic sin necesidad de repetir la misma palabra, incluso sin que ésta aparezca en los lugares clave y te diré más, no hace falta ni que la palabra por la que te quieres posicionar aparezca.
En muchas ocasiones no sería necesario incluir más contenido para ser más relevante, puedes hacerlo creando más relaciones que ayuden a desambiguar la entidad, «connecting the dots» 😉
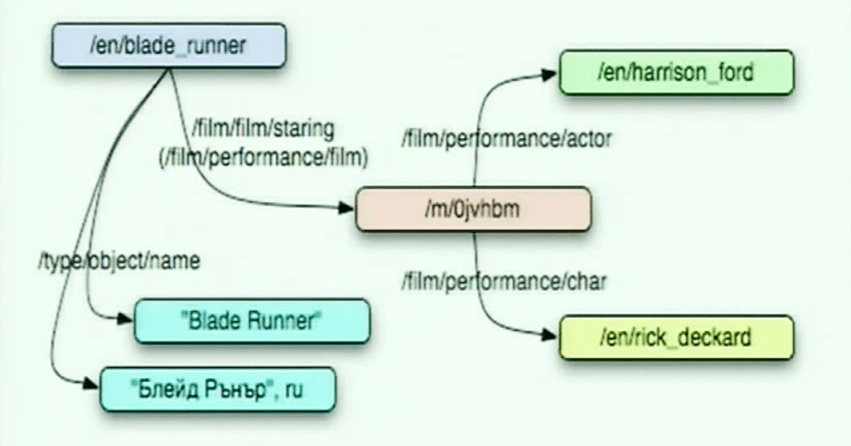 Entidades relacionadas en Freebase
Entidades relacionadas en Freebase
¿Conoces cómo hacen los buscadores las relaciones semánticas? ¿sabes qué es la desambiguación lingüística? o ¿cómo parsea Google los elementos HTML para extraer significado? Conseguirías un texto orientado 100% a las personas y 100% entendible por los buscadores. Puedes hacer las páginas accesibles pero si no las haces semánticamente entendibles estás perdiendo el tiempo.
Arquitectura
A nivel técnico tienes que entender cómo los buscadores crawlean tu web para optimizar el crawl budget que tienes asignado y cómo interpreta la estructura de la misma entre muchas otras cosas. Sabes por ejemplo ¿cómo hace Google el renderizado para detectar distintas regiones de un documento? ¿cómo lo hace Bing? ¿o Yahoo? ¿o cómo extrae Google las taxonomías para entender la arquitectura? Obtendrías una estructura mucho más relevante para los buscadores y evitarías sobreoptimizaciones que pensabas que eran necesarias.
Esto son solamente unos pocos ejemplos, y créeme cuando digo que son pocos, de las cosas que te pierdes si no entiendes cómo los buscadores hacen la recuperación y extracción de la información (IR – IE). Cuando estudias estos campos te das cuenta de que podemos hacer que los buscadores aprendan más rápido y te entiendan mucho mejor ahorrándoles trabajo, que al fin y al cabo, esa es nuestra tarea como SEOs. ¿Cuántas de estas cosas aparecen en el famoso checklist de más de 200 factores? Ninguno de ellos habla de cómo aplicar el lenguaje natural en nuestro proyectos, esto va mucho más allá de la keyword.
El SEO semántico para la web estructurada ha llegado para quedarse
A parte de los links que he dejado durante el post te voy a recomendar algunos recursos más que recomendables si te dedicas al SEO y, sobre todo, si te quieres seguir dedicando el día de mañana porque a medida que evoluciona la web, también tiene que evolucionar el SEO:
 Web actual vs Web semántica
Web actual vs Web semántica
Libro: Modern Information Retrieval de Ricardo Baeza
Este libro lo adquirí después de ver en directo a Ricardo Baeza (VP Yahoo Labs) en el Search Congress de Barcelona hace unos años. Es un libro muy denso pero muy revelador y un must si te dedicas al SEO. En el libro a parte de conocer los verdaderos fundamentos del SEO, hay capítulos dedicados a la extracción de información. Aquí te dejo los slides que usan para formación basados en este libro:
- Introduction (34 slides)
- User Interfaces for Search (87 slides)
- Modeling (263 slides)
- Retrieval Evaluation (144 slides)
- Relevance Feedback and Query Expansion (104 slides)
- Documents: Languages & Properties (147 slides)
- Queries: Languages & Properties (67 slides)
- Text Classification (157 slides)
- Indexing and Searching (153 slides)
- Parallel and Distributed IR (138 slides)
- Web Retrieval (163 slides)
- Web Crawling (91 slides)
- Structured Text Retrieval (135 slides)
- Multimedia Information Retrieval (164 slides)
- Enterprise Search (128 slides)
- Library Systems (35 slides)
- Digital Libraries (58 slides)
- Open Source Search Engines (25 slides)
Libro: Feature-driven question answering with natural language alignment de Xuchen Yao
Este libro es una reciente tesis de doctorado de Xuchen Yao (PDF de 332 páginas), un reciente fichaje de Google que ha entrado a formar parte del equipo de investigación de Búsqueda de Respuestas (Q&A). Esta tesis son 50 años de la historia de Q&A. También se explica cómo se hace Q&A con datos estructurados de consultas no escritas en lenguaje natural (básicamente cómo buscamos en Google).
Presentación: Llevando la estructura al texto: Extracción de frases, entidades, temáticas y jerarquías
Esta presentación del KDD 2014 habla de las diferentes técnicas que se usan para extraer y relacionar la información y que son usadas actualmente por los buscadores. Hay slides que valen oro 🙂
Presentación: Web Semántica y Schema.org
Presentación usada en el SemTech 2014 por el ingeniero de Google Ramanathan V. Guha. En ella se cuenta la necesidad de la creación de Schema y sus usos. En este artículo te comparto además cosas que hasta hacen poco no se podían hacer estructurando datos con Schema.
Presentación: SEO y Web Semántica de Lakil Essady
Presentación que mi socio y amigo Lakil Essady dio en el Congreso Web. Es del 2011 pero es igualmente válida a día de hoy y de lo poco que encontrarás en español sobre la implicación del SEO en la Web Semántica.
Vídeo: Introducción al NLP (procesamiento de lenguajes naturales)
El vídeo es una introducción al NLP (forma parte de IE) donde nos cuentan el estado del arte de este campo de la inteligencia artificial y la lingüística.
Vídeo: El motor de búsqueda estructurado
Este vídeo de 2011 pertenece a una Google Tech Talk donde Andrew Hogue, uno de los inventores de los Data Janitors, nos explica las dificultades de los buscadores a la hora de extraer partes e información dentro de un documento y hasta qué punto llegan a solucionarlo.
En el vídeo se comentan además las sinergias que hay entre Freebase y Google meses después de la compra. Estamos hablando de un vídeo de un año antes al Knowledge Graph y ahora ya vivimos en la era del Kwowldge Vault. Pero eso no quita que sea una buena introducción al análisis de sentimiento, parseado de consultas y búsqueda de respuestas en interfaces de búsqueda.
De este vídeo me quedo con una frase «20 million entities is cool. You know whats really cool? a billion entities». Y ya lo dejó caer de nuevo en el Strata de New York, donde dijo que una de las soluciones que hay para conocer la respuesta a todo es tener una base de datos más grande o montar sistemas híbridos (el KV que ahora conocemos).
Conclusiones
Al principio he dicho que no eres SEO si no sabes cómo funciona un buscador. En realidad nadie sabe cómo funcionan los buscadores, porque estamos hablando de la resolución de un problema mediante modelos probabilistas, ¡programación no lineal! Así que ni los propios ingenieros de Google saben realmente lo que hace todo el algoritmo y el peso que le da cada parte porque eso es imposible.
Lo único que sabemos son de la existencia de pequeños algoritmos que se usan en ciertas partes de toda la lógica. Conocerlos te dará una aproximación de su funcionamiento, que es mucho más que no saber nada, y dejarás de hacer cosas simplemente porque otros también lo hacen.