Tráfico agéntico: así navegan los agentes de IA y qué tienes que saber tú
Durante décadas, las webs han estado (o deberían estar) centradas en los humanos: cómo buscan, cómo hacen clic, cómo se mueven por una página. Todo medido desde una unidad simple, la URL. Pero este modelo está empezando a cambiar. ¿Por qué? Porque hoy, parte del tráfico web ya no proviene de personas, sino de agentes: sistemas de IA que actúan en nombre de los usuarios y que acceden al contenido, lo interpretan y lo reutilizan sin verlo como una web, sino como un grafo de datos. Bienvenidos al tráfico agéntico.
Y tenemos los números que lo demuestran:
Según datos de Tollbit en Q2-2025, las visitas humanas a webs de publishers cayeron un 9,4% versus el trimestre anterior, mientras que las peticiones de bots de IA se dispararon y ya representan 1 de cada 50 visitas, frente a 1 de cada 200 a inicios de año.
El crecimiento es exponencial.Según datos de Adobe, el tráfico a sitios de retail en USA desde navegadores GenAI y servicios de chat aumentó un 4.700% interanual en julio de 2025. Y estos usuarios que llegan son más valiosos. Pasan un 32% más de tiempo en el sitio, navegan un 10% más de páginas y tienen una tasa de rebote un 27% menor que los visitantes tradicionales.
Las cifras de volumen son aún más impactantes. Según el análisis de Scot Wingo (fundador de ChannelAdvisor), ChatGPT procesa 2.500 millones de prompts diarios, de los cuales el 2,1% están relacionados con "productos comprables", lo que equivale a 53 millones de consultas de compra al día. Aplicando una conversión del 5-20% y ticket medio de 80$, esto se traduce en un potencial de entre 73.000 y 292.000 millones de dólares anuales en GMV. El punto medio, 182.000 millones de dólares, ya rivalizaría con las ventas online anuales de los mayores retailers de Estados Unidos. Si plataformas como ChatGPT capturaran una comisión del 8%, esto representaría 15.000 millones de dólares anuales solo en comercio agéntico.
Índice de contenidos:
1. ¿Qué es el tráfico agéntico?
El tráfico agéntico son visitas, rastreos o llamadas a tu contenido realizadas por agentes de IA, no por humanos ni por crawlers clásicos.
A diferencia de un bot tradicional, que recorre páginas en masa sin contexto, un agente actúa por delegación (de un usuario o de una aplicación), se mueve por la web para completar tareas concretas y lo hace de forma contextual, puntual y orientada al resultado. El intercambio de valor es directo y medible: leer, comparar, escribir, comprar o verificar algo por encargo de alguien.
Nota: el tráfico agéntico no se limita a los agentes conversacionales. Incluye también las llamadas y automatizaciones intermedias dentro de workflows de IA (RPA+IA, orquestaciones, pipelines) que ejecutan pasos en nombre del usuario o del sistema principal.
1.1 Agentes con control total de UI / Navegador (Computer Use)
Son los más sofisticados. Operan sobre navegadores reales (a menudo en modo headless), renderizan las páginas, leen el DOM y pueden interactuar con la interfaz como lo haría un humano: hacer clic, rellenar formularios, navegar por menús desplegables, hacer scroll.
En los logs aparecen como un navegador real (cabeceras completas, descarga de recursos), con una navegación precisa y sesiones breves-medias (normalmente de segundos a pocos minutos <= 5).
Estos agentes se guían visualmente: analizan el layout mediante visión por computadora y razonamiento espacial para decidir qué elemento manipular o cómo avanzar una tarea.
1.1.1 Navegadores IA de consumo directo
Son los que el usuario final instala o usa para navegar, pero con un agente dentro del propio navegador. Ejemplos:
ChatGPT Operator: el agente puede abrir páginas, hacer clic o completar acciones dentro del chat.
Atlas (OpenAI), Comet (Perplexity) o Dia (The Browser Company), que integran directamente un agente de IA en la experiencia de navegación.
Claude for Chrome (Anthropic, preview), que permite al modelo leer y actuar sobre la pestaña activa.
Más allá del modelo, la carrera de los navegadores IA va de capturar datos de uso reales (historial, contexto, patrones de tarea) que alimentarán los siguientes ciclos de entrenamiento.
1.1.2 Modelos y APIs de Computer Use (para desarrolladores)
Aquí entran Gemini 2.5 Computer Use (Google), Claude Computer Use (Anthropic) y OpenAI Computer Use, que son modelos especializados en controlar interfaces gráficas mediante un bucle iterativo (agent loop) que observa el entorno (screenshot + URL + historial de acciones), decide una acción (clic, scroll, escribir) y la ejecuta hasta completar la tarea.
Su acceso "vía API" no significa que descarguen HTML directamente, sino que controlan un navegador real a través de una API de acciones. En este nivel también operan entornos de ejecución como Browserbase, Playwright o Puppeteer, que no son modelos en sí, sino capas de navegador headless sobre las que los agentes se pueden desplegar.
1.2 Agentes sin control de UI
Estos agentes no controlan visualmente la interfaz de forma autónoma, aunque pueden ejecutar interacciones programadas (clics, scrolls, inputs) dentro de un navegador headless como parte de un script o flujo predefinido. No “deciden” qué elemento pulsar, sino que siguen instrucciones determinísticas o selectores establecidos por el workflow.
Aun así, a menudo forman parte de workflows agénticos o automatizaciones con IA donde el agente principal delega pasos de lectura, extracción o validación a estos servicios de ejecución.
Si la tarea requiere razonamiento visual o decisiones dinámicas sobre la UI, entonces sí se escala a un modo de Computer Use, donde el modelo actúa sobre un navegador real en bucle de observación y acción.
1.2.1 Con renderizado de JavaScript
Estos agentes usan un navegador headless real (Chromium, Playwright, Puppeteer) y ejecutan JavaScript para obtener el DOM completo, replicando lo que vería un usuario tras la carga completa de la página. A diferencia de los agentes con Computer Use, no toman decisiones visuales: su propósito es renderizar y leer, no interactuar.
Esperan a que finalicen las promesas asíncronas y eventos típicos de frameworks como React, Vue o Next.js (incluido contenido lazy-loaded o montado vía XHR) antes de capturar el HTML resultante.
Casos notables incluyen Firecrawl (basado en Playwright) y Jina AI Reader (Puppeteer + Readability + Turndown), así como scrapers modernos con Puppeteer/Selenium que siguen esta misma lógica cuando el contenido depende del cliente.
Aquí también entran los "search agents" Gemini, incluso el web fetch de Gemini via API, que utiliza Chromium (Googlebot/WRS) para renderizar JavaScript , para cuando el modelo necesita grounding o acceso a contenido actualizado. Eso sí, AI Mode no hace fetch, consulta el índice de Google directamente.
En logs: descargas completas de recursos (JS, CSS, imágenes), user-agent tipo Chrome o Googlebot, latencias de 1-5 segundos, sin eventos de interacción reales aunque pueden existir scrolls sintéticos o disparos de eventos controlados por script para forzar el render.
1.2.2 Sin renderizado (HTTP simple)
Los más básicos, rápidos y baratos. Acceden mediante peticiones HTTP directas, sin ejecutar JavaScript, y procesan el HTML inicial como texto o DOM plano, a menudo convertido a Markdown para ser consumido en el flujo agéntico. ¿Qué implica? Que si la página depende del JS del cliente, no verán el contenido renderizado.
Aquí entran asistentes de IA como ChatGPT o Claude cuando hacen web_fetch en segundo plano para responder a una pregunta del usuario, herramientas de automatización como n8n HTTP Request, o scrapers básicos en un workflow de IA con requests (Python), curl o axios que no ejecutan JS.
En logs: 1-2 peticiones por URL, tiempos de permanencia muy bajos, sin descarga de subrecursos ni eventos del lado cliente.
Estos accesos son comunes dentro de workflows agénticos o pipelines de automatización, donde el agente principal delega pasos de lectura o validación a servicios de fetch ligeros.
1.3 Nivel pre-agéntico o de entrenamiento
Finalmente, hay rastreadores de IA que no ejecutan tareas delegadas, sino que alimentan datasets o índices que luego servirán de base a los agentes. Por ejemplo GPTBot, ClaudeBot, CCBot (Common Crawl), Meta-ExternalAgent (Meta), Google-Extended, etc.
No generan tráfico agéntico en sentido estricto, son HITS que hacen las IAs que anticipan exposición futura. Podríamos decir que son el “nivel cero” del tráfico IA, donde los modelos aprenden qué existe en la web antes de actuar sobre ello.
2. ¿Qué sabemos del rendimiento de estos agentes?
Aunque la promesa es enorme, la ejecución sigue estando muy verde. Donde mejor encajan hoy los agentes es en herramientas de código pero en tareas web "complicadas", la fiabilidad aún cojea. Llevo meses trabajando con ellos y, en general, resultan bastante decepcionantes. El benchmark de TheAgentCompany dice que incluso el mejor agente probado (Gemini 2.5 Pro) falló el 70% de las veces al ejecutar tareas reales. Y eso contando también las tareas parcialmente completadas.
Las principales causas de fallo son:
Mala navegación por interfaces web.
Incapacidad para manejar datos privados o incompletos.
Alta vulnerabilidad a errores acumulativos y alucinaciones.
Tests prácticos con Atlas Agent Mode de OpenAImuestran resultados similares. En seis tareas web variadas (crear playlists de Spotify, escanear emails, construir una fansite, seleccionar planes eléctricos, descargar juegos de Steam), el agente obtuvo una puntuación media de6,83/10. Funciona relativamente bien en tareas simples y estructuradas, por ejemplo creó una playlist de radio a Spotify (9/10), escaneó 164 emails para extraer contactos de PR a una hoja de cálculo (8/10), o seleccionó un plan eléctrico competitivo en Texas (9/10). Pero se queda atascado en bucles infinitos cuando las interfaces son menos claras: intentando descargar demos de juegos en Steam, el agente pasó diez minutos buscando filtros que no existían y nunca llegó a hacer ni una sola descarga (1/10).
El mayor limitante es que las "restricciones técnicas en la duración de sesión" cortan la mayoría de tareas a los pocos minutos, justo cuando empezaban a ser útiles. Esto hace que el agente no pueda completar tareas repetitivas que requieren tiempo, que son precisamente las que querríamos automatizar.
Otros experimentos que se están haciendo hoy en comercio electrónico también muestran problemas. Perplexity, por ejemplo, todavía tiene varios problemas con sus funciones de compra. Solo se pueden adquirir productos de uno en uno (no hay carrito) y muchos vendedores ni siquiera tienen forma de actualizar directamente la información de sus artículos, así que los datos suelen quedar desfasados porque se obtienen por scraping. Estas limitaciones tan básicas muestran que todavía falta bastante para que los agentes puedan manejar transacciones complejas de manera realmente fiable.
Esto repercute directamente para cualquier negocio que dependa de tareas online estructuradas, como compras, formularios, CRM, consultas médicas... Si el contenido no está bien estructurado o si requiere demasiada interacción no estandarizada, es probable que el agente no lo entienda, o lo haga mal. Tal y como veremos a continuación.
3. ¿Qué cambia para el SEO y para los responsables de sitios web?
Ya no importa tanto que una URL posicione para "precio lavadora X", sino que la máquina pueda entrar, entender cómo navegar por la web, recuperar y validar que "la lavadora X cuesta 399€".
Los agentes priorizan precio, valoraciones, velocidad de entrega e inventario en tiempo real sobre la familiaridad de marca o la lealtad, lo que podría remodelar completamente cómo compiten los retailers y cómo se toman las decisiones de compra. Es decir, el crecimiento del "zero-click search" y las interacciones impulsadas por agentes está erosionando el tráfico directo a las webs, junto con la capacidad del retailer para observar, influenciar y comprender el comportamiento del consumidor a escala.
Es importante entender también que estamos ante un cambio fundamental en el modelo de búsqueda. Google podría perder el 95% de su volumen de búsqueda y aún así crecer en ingresos, siempre que mantenga las consultas valiosas para ellos (principalmente las comerciales). La IA se está comiendo primero las consultas informacionales de bajo valor monetario (tipo "¿cuántos protones tiene el cesio?"), mientras que las búsquedas con intención de compra ("mejor raqueta de pádel"), donde se genera el dinero real, están seguras de momento.
Y las plataformas de IA lo saben. Según eMarketer, el gasto en anuncios de búsqueda con IA en USA alcanzará los 26.000 millones de dólares en 2029, aproximadamente el 14% del gasto total en anuncios de búsqueda. Formatos como preguntas patrocinadas de Perplexity (con problemas de nuevo), AI Max de Google o publicidad in-chat de Grok representan un nuevo modelo de paid media conversacional que competirá directamente con los Google Ads tradicionales.
En cualquier caso, para que todo esto funcione, el contenido tiene que ser legible para humanos, pero también accesible y procesable por máquinas.
3.1 El nacimiento de la AX (Agent Experience)
Agent Experience es User Experience para agentes. Si los agentes no pueden completar sus objetivos, los usuarios tampoco. Una mala AX se traduce en mala UX = usuarios insatisfechos o perdidos. Creo que esto da pie a abrir un nuevo debate como el del SEO vs GEO.
En mis pruebas con browser agents, he visto cómo el agente abandonaba la web de un cliente DTC y se iba a un marketplace, simplemente porque allí sí podían completar la tarea que le había pedido.
AX no significa delegación total
Pero hay un matiz importante: AX no es solo optimizar para que el agente complete todo de forma autónoma. También significa reconocer cuándo el usuario quiere retomar el control.
Según análisis de Forrester sobre comercio conversacional, las experiencias automatizadas actuales están "más en fase asistiva que agéntica" y tienen un problema recurrente: asumen que los compradores no quieren realmente explorar. Para productos de baja consideración (pilas, detergente), delegar funciona. Pero para productos de alta consideración como ropa, electrónica o artículos especializados, la navegación sigue siendo preferida, divertida o necesaria.
Esto tiene implicaciones directas para AX:
Tu web debe permitir que el agente extraiga información rápidamente (precios, disponibilidad, specs) para ayudar al usuario a comparar.
Pero también debe estar preparada para recibir al usuario cuando quiera ver más, comparar visualmente o explorar el catálogo por su cuenta.
Los mejores flujos no son "agente completa todo" ni "usuario hace todo". Son híbridos: el agente descubre, filtra y compara, pero el usuario decide cuándo tomar el control.
Por eso una buena AX no es hacer que tu web sea "navegable solo por agentes". Es hacerla navegable tanto por agentes como por los humanos que llegan después de interactuar con esos agentes. No es agente O humano, es agente Y humano colaborando. O lo que es lo mismo, guided selling aumentado con IA generativa.
Os lanzo un reto. Pedidle al agente de ChatGPT, Operator, que complete una tarea en vuestra web, cualquiera que sea razonable para lo que ofrecéis. Veréis la cantidad de errores que se va a encontrar. ¿Qué problemas me he encontrado yo?
Bloqueos por firewalls.
Tareas que no se completan por timeouts.
Problemas de interacción por una maquetación deficiente a nivel de accesibilidad.
Errores al distinguir el producto principal de los recomendados, por una mala jerarquía del HTML.
Y mi favorita: equivocaciones derivadas de problemas de usabilidad. El agente se comporta como un usuario nuevo (ojo: entrando en un desktop con una resolución y viewport pequeño, con todo lo que esto significa) y sin la "maldición del conocimiento". Esto es brutal e ideal para test de "usuarios".
Y no hablo de webs pequeñas. He visto todos estos problemas en webs de clientes que están entre los principales ecommerce del país.
De hecho, un análisis reciente que evaluó más de 100 tareas con ChatGPT Agent mode confirma la magnitud del problema que hablo. El 63% de las primeras visitas terminaron en rebote inmediato por errores 4XX/5XX, redirecciones inesperadas, páginas lentas o bloqueos por CAPTCHAs. Y de las visitas que superaron esa barrera inicial, solo el 17% lograron completar la conversión. Las principales causas de abandono identificadas incluyen formularios mal diseñados, requisitos de registro prematuros o poco claros, y pop-ups que cubren los botones de conversión. Además, el estudio reveló que el 46% de las visitas de agentes ocurren en modo lectura (solo texto/HTML, sin CSS ni JavaScript), lo que subraya aún más la importancia del HTML semántico y la accesibilidad que mencionábamos.
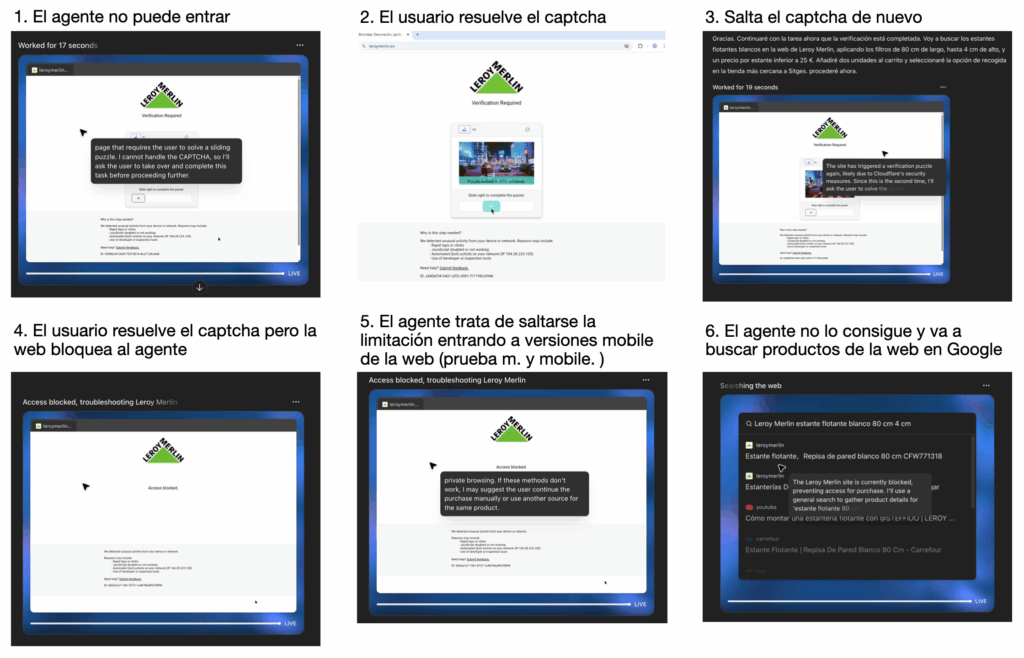
Aquí podemos ver un ejemplo en Leroy Merlin (no es cliente, pero ya están avisados):
Más allá del SEO técnico, creo firmemente que el HTML semántico ya no es solo un tema de accesibilidad. Es el punto de anclaje para agentes, navegadores inteligentes, scraping ético y modelos de lenguaje. Cuanto más claro y coherente sea tu marcado, menos errores le causarás a este nuevo tipo de tráfico. No es opinión, me baso en evidencia y en un buen puñado de papers que demuestran cómo los sitios que siguen estándares de accesibilidad y usan HTML semántico ayudan a los agentes en grounding y en tareas de navegación agéntica.
Pero el HTML semántico es solo el principio. Los agentes también necesitan que el contenido esté optimizado para ser entendido, citado y utilizado. Y aquí viene la buena noticia, si ya hacías un buen SEO, ya estás preparado.
Como explico en detalle en mi análisis sobre SEO para IA, optimizar para que ChatGPT, Perplexity o Gemini te citen en sus respuestas no requiere nuevas siglas (GEO, AEO, LLMO...). Es simplemente la evolución lógica del SEO semántico que deberíamos haber estado haciendo desde 2013.
Por qué la estructura importa: evidencia desde el entrenamiento de agentes
Un paper reciente de Google (SAGE) aporta evidencia directa de por qué esto importa. El estudio analiza cómo entrenar agentes para "deep search", tareas que requieren múltiples pasos de búsqueda y razonamiento (entre 2 y 10 hops de media, frente a los 1-2 de los benchmarks tradicionales).
Lo interesante son los "atajos" que identificaron, es decir, los patrones que reducen la complejidad de búsqueda para el agente:
Information Co-Location (35% de los casos): cuando dos o más piezas de información necesarias para responder están en el mismo documento, el agente resuelve en un solo hop lo que deberían ser múltiples búsquedas.
Multi-query Collapse (21%): cuando una sola query bien formulada recupera suficiente información de distintos documentos para resolver varios pasos a la vez.
La implicación para AX es que si estructuras contenido semánticamente relacionado en la misma página (o en páginas bien enlazadas), reduces los hops que necesita el agente y aumentas la probabilidad de que te use como fuente. No estoy especulando, es cómo Google está entrenando a sus agentes para navegar la web.
APIs y feeds: alternativas al scraping
Ya estamos viendo asociaciones entre agentes y empresas para acceder a sus datos via API y mejorar así la fiabilidad y velocidad de las respuestas. Ahí están los acuerdos de OpenAI y Perplexity con Tripadvisor, Booking o Uber. Justo como ya comenté hace meses, que se pondría de moda ofrecer alternativas al scraping de estos bichos ya sea mediante APIs, feeds o datos estructurados (JSON, XML).
En este punto entra en juego la especificación OpenAPI, que sirve para describir y validar cómo se usan las APIs: qué endpoints hay, qué parámetros admiten, qué devuelven y qué errores pueden dar. Para los agentes, tener un contrato OpenAPI bien publicado significa poder ejecutar acciones de forma fiable y segura, más allá de simplemente leer el contenido de la página.
De hecho, OpenAPI ya lo usan en producción empresas como ChatGPT (en sus plugins y GPTs personalizados), Google (Gemini + APIs de Workspace) o Anthropic (Claude con Tools). Y en paralelo, compañías como Stripe, Twilio, Shopify, Slack, Booking o Uber publican sus APIs en OpenAPI para que sean consumidas de forma segura, documentada y predecible.
De hecho, el estándar llms.txt ya se está usando con esta misma lógica. Google publica llms.txt y llms-full.txt en la documentación de su Agent Development Kit (ADK) para que herramientas como Gemini CLI, Claude Code o Cursor consuman la documentación directamente vía servidores MCP, sin necesidad de scrapear
Los estándares para compras agénticas: ACP y UCP
En el ámbito específico del comercio electrónico han surgido dos protocolos competidores que buscan convertirse en el estándar para las transacciones realizadas por agentes de IA.
OpenAI y Stripe lanzaron en septiembre de 2025 el Agentic Commerce Protocol (ACP), el estándar abierto que alimenta la funcionalidad Instant Checkout en ChatGPT. Este protocolo resuelve precisamente los problemas que veíamos con Perplexity: define cómo los agentes deben gestionar carritos multiproducto, procesar pagos mediante tokens seguros (como el Shared Payment Token de Stripe), manejar inventarios en tiempo real y completar transacciones complejas sin depender de scraping o simulación de clics. ACP establece un contrato estandarizado que incluye descubrimiento de productos, gestión de sesiones de compra, autorización de pagos y confirmación de pedidos. Actualmente ya está en producción en ChatGPT con merchants de Etsy, Walmart y más de un millón de comercios de Shopify (Glossier, SKIMS, Spanx, Vuori...). PayPal también se ha unido, anunciando su integración con ChatGPT para dar soporte a Instant Checkout junto a Stripe.
Google respondió en enero de 2026 con el Universal Commerce Protocol (UCP), presentado por Sundar Pichai en la feria NRF 2026. A diferencia de ACP, que se centra en el checkout, UCP cubre todo el ciclo de compra: descubrimiento, transacción, postventa, devoluciones y programas de fidelización. Ha sido co-desarrollado con Shopify, Walmart, Target, Etsy y Wayfair, y cuenta con el respaldo de Visa, Mastercard, Stripe, American Express, PayPal y otros 20+ partners.
Las diferencias clave entre ambos protocolos son:
Alcance: ACP se limita al checkout; UCP cubre el ciclo completo incluyendo postventa y loyalty.
Arquitectura: ACP es centralizado (los merchants deben aplicar a OpenAI para aparecer en ChatGPT); UCP permite que las tiendas publiquen sus capacidades en /.well-known/ucp de su propio dominio, sin depender de un gatekeeper.
Pagos: ACP está muy acoplado a Stripe; UCP es agnóstico al procesador (Google Pay, PayPal, cualquier red).
Superficie: ACP opera en ChatGPT; UCP en Google Search AI Mode, Gemini y Google Shopping.
Interoperabilidad: UCP se declara compatible con MCP, A2A y AP2; ACP es un ecosistema más cerrado.
Ambos protocolos son de código abierto bajo licencia Apache 2.0. La realidad es que no es VHS vs Betamax: los merchants que quieran maximizar su alcance tendrán que soportar ambos, igual que hoy se desarrolla para iOS y Android. Google tiene la ventaja de su Shopping Graph (50.000 millones de listings que se refrescan 2.000 millones de veces cada hora) y la base instalada de Merchant Center. OpenAI tiene 700 millones de usuarios semanales en ChatGPT que ya están preguntando qué comprar. La batalla acaba de empezar.
NLWeb: endpoints conversacionales para tu sitio
Mientras esperamos que maduren los protocolos mencionados, ya existe NLWeb, un protocolo abierto impulsado por Microsoft que define dos endpoints estándar para que tanto personas como agentes consulten tu sitio en lenguaje natural:
/ask: endpoint conversacional para preguntas/respuestas.
/mcp: endpoint MCP (Model Context Protocol) para agentes de confianza y herramientas.
La ventaja es que dejas de depender del scraping frágil para exponer respuestas estructuradas y acciones a los agentes, sin obligarles a emular un humano navegando por el UI. Cloudflare lo implementa con AutoRAG + NLWeb Worker: crawlea tu sitio renderizado, indexa y despliega automáticamente esos endpoints en tu dominio (ej. ask.tudominio.com/ask). Incluso incluye un snippet embebible para añadir búsqueda conversacional en tu web.
WebMCP: tu frontend como servidor MCP
NLWeb resuelve el acceso conversacional desde el backend. Pero ¿qué pasa cuando el agente ya está en tu página y necesita interactuar con ella? Aquí entra WebMCP, una propuesta de estándar web que Google y Microsoft están incubando conjuntamente dentro del W3C Web Machine Learning Community Group.
La idea es que e vez de que un agente tenga que hacer screen-scraping, interpretar el DOM o simular clics para completar una tarea, tu web le dice explícitamente qué puede hacer, cómo llamar a cada acción y qué parámetros necesita. Tu frontend se convierte, literalmente, en un servidor MCP.
No necesitas montar un servidor MCP en Python o Node.js aparte. Reutilizas la lógica que ya tienes en tu frontend. Y según los benchmarks iniciales del proyecto, las llamadas estructuradas vía WebMCP consumen un 89% menos de tokens que los workflows basados en screenshots, porque el agente recibe JSON en vez de tener que procesar imágenes de la pantalla.
El panorama completo
Con esto, AX deja de ser solo "hacer legible el DOM" y pasa a ser ofrecer un contrato explícito para consultas y acciones. Los agentes necesitan mucho más que HTML bien estructurado, sobre todo para funciones comerciales: necesitan APIs unificadas para moverse entre plataformas, capacidad de memoria para recordar preferencias y umbrales de precio, y acceso a datos fiables y actualizados.
Sin estos elementos, los LLMs seguirán siendo meros "resumidores inteligentes" en lugar de agentes comerciales. Tal y como hemos visto con los problemas de Perplexity en comercio electrónico, incluso funciones básicas como un carrito de compras múltiple requieren una infraestructura que aún no existe o que está empezando a madurar con protocolos como los mencionados.
3.3 AX también implica seguridad y privacidad
Pero hay otra dimensión, porque AX también implica seguridad y privacidad. No sirve de nada que un agente complete bien una tarea si al mismo tiempo abre la puerta a un ataque mediante prompt injection.
El problema de fondo es que estos agentes no distinguen entre instrucciones legítimas del usuario e instrucciones maliciosas inyectadas desde contenido web. Cuando un agente lee una página, un email o un evento de calendario, procesa todo el texto como potencialmente ejecutable.
Brave lo ha demostrado con Comet (Perplexity): con un simple post en Reddit han podido engañar al agente para robar mails, OTPs y datos privados. Y funciona incluso con texto prácticamente invisible (azul claro sobre amarillo) embebido en imágenes. Fellou Browsertiene el mismo problema: simplemente pedirle que navegue a un sitio hace que envíe automáticamente el contenido de esa página al LLM, permitiendo que instrucciones maliciosas modifiquen lo que el agente ejecuta.
OpenAI Atlas también es vulnerable. Y no solo por prompt injection, el navegador construye un "trove de memorias" sobre todo lo que haces online que persisten en sus servidores durante 30 días. Una investigadora de la Electronic Frontier Foundation encontró que Atlas guardó memorias sobre registrarse en servicios de salud sexual y reproductiva e incluso nombres de médicos reales. Los controles de privacidad son confusos (tienes memorias de Atlas separadas de las de ChatGPT), el modo incógnito no te oculta de ChatGPT, y aunque puedes borrarlas, requiere esfuerzo activo constante.
El riesgo se multiplica cuando conectas herramientas (MCP) a estos agentes. Estamos viendo ataques en producción ahora mismo:
ShadowLeak: alguien te manda un email con comandos ocultos en el HTML (texto minúsculo o blanco sobre blanco). Cuando le pides al agente "resuma mis correos", lee la trampa, extrae información personal de otros emails y se la envía al atacante. Todo pasa en los servidores de OpenAI, sin que veas nada.
Calendar poisoning: te llega una invitación de calendario con un prompt malicioso en la descripción. Ni siquiera necesitas aceptarla. Basta con decirle al agente "prepárame el día de mañana" para que lea tu agenda, procese el jailbreak y filtre tus datos.
Es decir, cualquier persona que pueda escribir un texto que tu agente lea, puede controlar lo que ese agente haga después. Los agentes no tienen "sentido común", solo obedecen lo que leen. Por eso los MCP son peligrosos: juntan la tríada letal de datos privados + contenido no confiable + capacidad de comunicarse fuera.
De hecho, un estudio reciente de seguridad sobre MCP ha demostrado la gravedad del problema. Investigadores de Leidos probaron servidores MCP estándar (filesystem, Slack, Chroma) con Claude 3.7 y Llama-3.3-70B y lograron ejecutar tres tipos de ataques:
Ejecución de código malicioso (MCE): Insertar comandos en archivos como .bashrc que se ejecutan cada vez que abres una terminal
Control de acceso remoto (RAC): Añadir claves SSH al sistema para acceso permanente
Robo de credenciales (CT): Extraer API keys de variables de entorno y enviarlas por Slack
Lo más preocupante es que los guardrails de los LLMs no son confiables. Claude a veces detectaba los intentos maliciosos pero podía ser convencido con cambios mínimos en el prompt. Llama solo rechazaba peticiones con palabras explícitamente maliciosas como "hack" o "steal".
Peor aún, introdujeron los ataques RADE (Retrieval-Agent Deception), que consiste en un atacante corrompiendo archivos públicos con comandos maliciosos centrados en un tema específico (por ejemplo, "MCP"). Cuando el usuario le pide al agente "busca información sobre MCP en mis archivos", el agente recupera y ejecuta automáticamente los comandos maliciosos. El atacante ni siquiera necesita acceso directo al sistema.
Esto es exactamente el mismo patrón que ShadowLeak y calendar poisoning: contenido malicioso + agente que no distingue instrucciones + herramientas con acceso privilegiado = desastre garantizado.
Qué hacer mientras tanto
Hasta que no haya mejoras categóricas de seguridad, los navegadores agénticos están muy verdes todavía. Algunas recomendaciones:
Evita conectar herramientas críticas (email, calendario, Drive) como superusuario permanente. Los agentes deberían heredar permisos según el origen del contenido, no tener acceso total por defecto.
Aísla la navegación agéntica de tu navegación regular. No uses el mismo perfil para tareas automatizadas y para navegar con tus credenciales.
Si experimentas con MCP, hazlo en local sin conexión a internet.
Para los responsables de sitios web, esto significa que AX debe incluir protecciones contra prompt injection desde el diseño (como curiosidad, el otro día descubrí que ChatGPT podría estar empezando a protegerse de ello). No basta con hacer tu sitio navegable por agentes, también tienes que asegurar que el contenido generado por usuarios no pueda inyectar comandos maliciosos.
4. El problema de la medición y los bloqueos
Detectar el tráfico agéntico hoy es un reto técnico bastante serio. Los métodos clásicos (user-agent, IP, ASN) no son fiables, porque muchos agentes:
Usan ASNs de terceros, como BrowserBase.
Cambian de IP constantemente o rotan encabezados.
Se hacen pasar por navegadores reales (por ejemplo, impersonando Chrome).
Este descontrol ya está generando conflictos, como el reciente caso Cloudflare vs Perplexity. Cloudflare los acusó de evadir robots.txt y simular ser tráfico humano. Perplexity respondió que esas llamadas eran realizadas por usuarios reales a través de servicios en la nube. ¿Quién tiene razón? Técnicamente, los dos. Y eso deja al descubierto el verdadero problema, que es que no existe un estándar fiable para autenticar bots y agentes.
Y el problema no acaba ahí. Reddit acaba de demandar a Perplexity por una estrategia aún más sofisticada de evasión. Reddit tiene acuerdos de licencia con Google y OpenAI, pero no con Perplexity. Tras enviarles un cease & desist, las menciones a contenido de Reddit en las respuestas del modelo aumentaron x40.
Entonces Reddit colocó un post trampa visible solo para Googlebot y, a las pocas horas, ese mismo contenido apareció en las respuestas de Perplexity. Ya tenían la prueba de que Perplexity (o sus proveedores como Oxylabs, AWMProxy y SerpApi) estaban usando resultados indexados por Google para rascar contenido de Reddit. Scraping indirecto de libro.
Reddit ahora los ha demandado, acusándolos de construir un negocio de $20B sobre "contenido robado". Pero lo importante para nosotros es que los rastreadores de IA no siempre acceden de forma directa. Pueden usar el índice de Google como proxy para esquivar bloqueos. Si quieres proteger tu contenido, bloquear al bot no es suficiente, hay que monitorizar derivadas y entender que el problema es sistémico. Por lo que llega el crawl governance, o lo que es lo mismo, ahora toca gestionar quién te scrapea, desde dónde y para qué. Para ello, existen una serie de nuevos protocolos que veremos más adelante en la sección 5.
El problema de fondo es que muchos de estos agentes se camuflan como tráfico humano. Los datos de Tollbit muestran que el crecimiento de bots que ignoran robots.txt aumentó más del 40% en el último trimestre, y muchos se presentan con user-agents de Chrome, cargan anuncios e incluso resuelven CAPTCHAs. Por eso los logs tradicionales ya no sirven para distinguirlos.
Para ilustrarlo, os dejo un extracto de un log que deja un navegador de IA (Operator) en la web de un cliente, es un usuario normal:
2025-08-19T11:06:15.005Z
client_ip=2001:db8:85a3::8a2e:370:7334
geo_country=spain
geo_city=barcelona // Se conecta desde un lugar cercano a mi ubicación
domain=<borrado>
conn_speed=broadband
conn_type=wired
fastly_server=cache-ams21037-AMS
file_type=HTML-Page
bot_type=Not-Botmobile=0 // Desktop
request_method=GET
request_protocol=HTTP/1.1
request_user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
response_body_size=39455
response_reason=OK
response_state=MISS
response_status=200
status_category=2xx-Success
time_elapsed=1435
url="/en/<borrado>/?id=test_chatgpt_operator"
5. ¿Y ahora qué? Hacia una Agent-Oriented Web
Además de optimizar webs individuales (AX), la web en su conjunto va evolucionando hacia una Agent-Oriented Web, por lo que hace falta un marco de nuevos estándares para que los agentes operen de forma nativa, segura y predecible.
El debate técnico y ético que ha empezado:
¿Deben los agentes respetar robots.txt si actúan en nombre de un humano?
¿Estamos ante rastreo, scraping o asistencia?
¿Quién tiene derecho a acceder, procesar y monetizar el contenido?
Si vamos hacia motores de finalización de tareas que tratan la web como una base de datos abierta, necesitamos un stack de nuevas reglas en la web. Ese stack tiene cuatro capas básicas: señalizar qué usos del contenido están permitidos, licenciar bajo qué condiciones, autenticar a los agentes que acceden y ejecutar pagos cuando corresponda.
Veamos cómo se está empezando a construir cada una de ellas.
5.1 Señalización y preferencias: Content Signals + AI Preferences
Antes incluso de hablar de licencias y cobros, hace falta aclarar para qué puede usarse tu contenido. Aquí entran dos iniciativas distintas:
Content Signals (Cloudflare): añade un bloque en robots.txt para distinguir entre tres propósitos de uso: search, ai-input (para salir como respuesta en inferencia tipo AIO) y ai-train. No obliga a nadie, pero deja constancia pública de tu política y ayuda a que los bots que quieran cumplir sepan qué está permitido y qué no. Cloudflare ya lo incluye en su managed robots.txt.
AI Preferences (IETF): es un estándar en desarrollo que busca unificar cómo se adjuntan esas preferencias a nivel de protocolo HTTP, con opciones más granulares y verificables. La idea es que puedas declarar, por ejemplo, que tu contenido puede usarse para inferencia pero no para entrenamiento, y que esa preferencia viaje con el recurso más allá de robots.txt.
En la práctica parece que esto sería el primer paso, primero señalizas/formalizas la política (Content Signals o AI Preferences), y a partir de ahí decides si bloqueas, licencias o cobras con algo como el RSL y Pay-Per-Crawl que veremos ahora.
5.2 Estándares de monetización: RSL, Pay Per Crawl, PCM
Para abordar el problema de la monetización han surgido dos aproximaciones complementarias:
Really Simple Licensing (RSL): Está impulsado por el RSL Collective y apoyado por grandes marcas como Reddit, Yahoo y Quora. Lo que hace el RSL es ampliar el protocolo robots.txt para permitir a los editores definir términos de licencia y pago. De esta forma, una web puede especificar un coste por rastreo (pay-per-crawl) o incluso un pago cada vez que un modelo de IA utiliza su contenido para generar una respuesta (por ejemplo, ¿podría haber un pay-per-inference para salir en una AIO?). El objetivo es crear un modelo de negocio escalable que compense a los creadores por el uso de su trabajo para el entrenamiento de IA, simplificando las negociaciones que hasta ahora eran caso por caso.
Cloudflare Pay-Per-Crawl: es la primera implementación operativa de esa idea. En lugar de quedarse en la señalización, añade mecanismos de autenticación, facturación y cobro. Cuando un bot de IA que participa en el programa intenta acceder a tu contenido, Cloudflare puede responder con un HTTP 402 Payment Required si no hay acuerdo de pago, registrar los eventos de rastreo cobrados y liquidar automáticamente a los editores.
Publisher Content Marketplace (PCM): es la apuesta de Microsoft, un marketplace donde los editores licencian contenido premium directamente a sistemas de IA (empezando por Copilot) con precios basados en el valor entregado, reporting de uso y términos definidos por el publisher. Ya pilota con Associated Press, Condé Nast, Hearst, Vox Media y USA TODAY, y con Yahoo como primer partner de demanda.
Sería como si el RSL definiera el contrato, Pay-Per-Crawl lo ejecutara en la práctica y el PCM lo llevaría un paso más allá mediante un marketplace centralizado de licencias para grounding en IA.
5.3 Instrucciones embebidas: llms.txt en HTML
También han empezado a aparecer propuestas más explícitas para dar instrucciones a los agentes dentro del propio HTML. Desde Vercel, se plantea incrustar estas instrucciones mediante un bloque inline <script type="text/llms.txt"> en la respuesta HTTP (por ejemplo, en un error 401). De esta forma, los humanos no verían nada, pero los agentes sí pueden leerlo y entender cómo continuar (autenticación, acceso a un MCP...).
De hecho, Google ya usa llms.txt en la documentación de su Agent Development Kit (ADK), ofreciendo tanto un llms.txt con índice navegable como un llms-full.txt con el volcado completo del sitio, para que herramientas como Gemini CLI, Claude Code o Cursor puedan consumir la documentación directamente.
5.4 Autenticación: Web Bot Auth
El IETF está desarrollando Web Bot Auth, un estándar de autenticación criptográfica que permitiría identificar con fiabilidad qué agente está accediendo, si está autorizado y con qué propósito. Este estandar es la base tecnológica tanto del Trusted Agent Protocol de Visa como de iniciativas de Mastercard y American Express que veremos ahora.
5.5 Estándares para pagos: Agent Payments Protocol (AP2), Visa y Mastercard
Más allá de la autenticación y la monetización del contenido, el paso final y más crítico, la transacción, también requiere de un nuevo framework. Aquí es donde entran varios protocolos complementarios:
Agent Payments Protocol (AP2), un estándar abierto anunciado por Google junto a gigantes de los pagos como Mastercard, American Express y PayPal. Su objetivo es resolver los tres grandes problemas de las compras hechas por agentes: la autorización (demostrar que el usuario dio permiso), la autenticidad (asegurar que la petición del agente es legítima) y la responsabilidad (saber quién responde si algo sale mal). Para ello, utiliza "Mandatos", contratos digitales criptográficos que crean una prueba verificable de las instrucciones del usuario, estableciendo un rastro auditable y seguro desde la intención de compra hasta el pago final.
Visa Trusted Agent Protocol y Mastercard Agent Pay representan el enfoque de las redes de pago tradicionales, ambos lanzados en 2025. Utilizan tokenización para crear credenciales digitales seguras: Visa mediante su Trusted Agent Protocol con Web Bot Auth de Cloudflare (trabajando con Microsoft, Shopify, Stripe y Worldpay), mientras que Mastercard usa Agentic Tokens en un framework "no-code" que permite a los merchants participar sin grandes cambios (colaborando con Microsoft, IBM y Braintree). Un caso destacado es la integración de Perplexity con Visa, que busca resolver precisamente los problemas de carrito único y datos desfasados que mencionábamos antes. Ambos buscan resolver los mismos dilemas: ¿cómo distinguir agentes legítimos de bots maliciosos? ¿cómo verificar que el usuario autorizó la compra? ¿cómo asegurar que el agente ejecutó correctamente las instrucciones? A medida que el comercio agéntico madure, ambos frameworks permiten evolucionar hacia integraciones más profundas con protocolos como MCP, A2A y el ACP mencionado anteriormente.
Iniciativas como esta buscan soluciones técnicas que permitan identificar a los agentes de forma segura, sin comprometer la privacidad del usuario y sin bloquear el acceso legítimo a la información. El equilibrio es delicado, como veremos en el siguiente punto, porque si lo cierras todo, pierdes visibilidad y si lo abres sin control, pierdes negocio.
5.6 Buenas prácticas para crawlers: el estándar CBCP del IETF
Mientras se desarrollan los protocolos de monetización y autenticación, el IETF está trabajando en el draft-illyes-aipref-cbcp (Crawler Best Practices), que establece las obligaciones mínimas que deberían cumplir todos los crawlers y agentes bien comportados. Este borrador complementa iniciativas como RSL o Web Bot Auth, definiendo lo que se espera que hagan los operadores de crawlers, no solo lo que los sitios web pueden señalizar. Ha sido redactada por Gary Illyes (Google, aunque sale como independiente), Mirja Kühlewind (Ericsson) y AJ Kohn (Blind Five Year Old).
Las prácticas clave incluyen:
Respetar el Robots Exclusion Protocol (robots.txt) y las cabeceras X-robots-tag.
Identificarse claramente mediante user-agent con URL de documentación.
No interferir con la operación normal del sitio (límites de velocidad, timeouts, horarios de menor tráfico).
Soportar directivas de caché HTTP.
Publicar los rangos de IP utilizados en formato JAFAR.
Documentar el uso de los datos y cómo bloquear el crawler.
Este estándar es importante porque establece un contrato bidireccional: los sitios señalizan sus preferencias (Content Signals, AI Preferences) y los crawlers se comprometen a comportarse de forma predecible y respetuosa.
6. Bloquear a la IA puede salirte caro
Desde Google reconocen que bloquear el acceso a la IA sin entender cómo funciona el ecosistema puede salir caro.
Gary Illyes ha señalado que muchos editores están optando por bloquear Google Extended, pero que eso no afecta a AI Overviews ni a AI Mode, porque estos se alimentan del índice de Google Search y no hacen fetch en vivo (comprobado), al menos por ahora. Es decir, aunque cierres el grifo a Google Extended, sigues siendo "visible" si tu contenido ya está indexado.
Gary también participa en el grupo de trabajo del IETF que está desarrollando AI Preferences antes mencionado arriba. Dice que la propuesta tiene impulso, pero que aún está por ver si llegará a implementarse. Y avisa que hay demasiados conceptos erróneos sobre cómo funciona la IA, incluso entre perfiles técnicos. Bloquear sin entender puede no solo dañar tu visibilidad, sino frenar la innovación. Y aclara que esto no es una “cosa de Google”, sino un problema más amplio del ecosistema web.
Pero el matiz importante es otro: al bloquear crawlers de IA, también puedes estar bloqueando agentes, ya que muchos agentes operan a través de servicios intermedios que acaban cayendo en listas de bloqueo. Y, como decíamos, no hay una forma estándar de diferenciarlos.
Por eso desde Google piden prudencia. La IA podría ser una fuente de visibilidad y de ingresos si se gestiona bien. Pero si cierras el acceso a ciegas, podrías estar cerrando la puerta al tráfico agéntico que viene delegado por usuarios reales. Y la Gen Z adora estas nuevas interfaces, ya está usando este tipo de herramientas para navegar, buscar o comprar y el caso de uso principal de ChatGPT es el de buscador, ¿vas a quedarte fuera por miedo?
El futuro: comercio agente-a-agente (A2A)
No nos olvidemos de la próxima frontera del comercio agéntico es el comercio agente-a-agente (A2A). En este escenario, los agentes de terceros compran en nombre de los consumidores trabajando directamente con los brand agents de los retailers para finalizar las compras. El proceso se optimiza continuamente según las preferencias del usuario, con poca o ninguna intervención humana.
Para los retailers, esto significa reorientar sus plataformas para ser descubribles por agentes externos, lanzar sus propios brand agents que preserven el valor de marca en estas interacciones automatizadas, y asegurar que puedan conectar y operar sin fricciones en el ecosistema más amplio.
Según BCG, casi todos los retailers globales (96%) están explorando o implementando algún tipo de estrategia de agentes de IA. Pero dos tercios creen que las empresas que no adopten agentes en los próximos dos años se quedarán atrás. La ventana para prepararse está cerrándose
Conclusión
Como hemos visto, el reto de todo esto es controlar, identificar qué entra, quién lo envía y con qué propósito. Y para ello, iniciativas como RSL, Content Signals, Web Bot Auth y las propuestas AI Preferences podrían marcar el camino. Mientras tanto, lo que está claro es que el tráfico agéntico no lo vas a frenar con un robots.txt.
El tráfico agéntico no sólo cambia interfaz, también cambia la métrica de éxito. En lugar de optimizar por clics en una URL, debemos empezar a optimizar por utilidad total, es decir, el balance entre coste cognitivo, coste de interacción y tiempo hasta completar la tarea. Los agentes y los resúmenes generativos existen precisamente para reducir esos costes (délficos según Google) y acercar cada visita (humana o agéntica) a la finalización de la tarea.
MUVERA (Multi-Vector Retrieval Algorithm) es un paper de investigación de Google publicado en arXiv el 29 de mayo de 2024. Su objetivo es mejorar la eficiencia de la recuperación semántica multivectorial (como la que usa ColBERT), transformándola en un problema de recuperación monovectorial mediante una técnica llamada Fixed Dimensional Encodings (FDEs). Es decir, se trata […]
Las herramientas para medir visibilidad en la IA (prompt trackers) prometen medir algo que es imposible medir con precisión. Este informe técnico examina por qué medir la visibilidad en IA es técnicamente problemático, qué dice la evidencia disponible y cómo evaluar las herramientas del mercado. Mi objetivo es tratar reducir la asimetría de información, es […]