Por qué trocear tu contenido es malo para tu SEO y para la IA
Hay una corriente de GEO Bros que ha descubierto dos palabras (chunks y embeddings) y ha decidido que el futuro del SEO es atomizar el contenido de tu web.
Su lógica es que "como los LLMs funcionan por fragmentos y vectores, vamos a crear URLs ultra específicas para cada posible pregunta para que la IA lo chunkee mejor"
El problema es que esa recomendación asume que Google funciona como una base de datos vectorial sencilla tipo ChromaDB o Pinecone... y no es así.
Hoy vamos a desmontar esta falacia y a explicar por qué el contenido consolidado en una URL sigue funcionando mejor (a menos que la SERP te pida especificidad como veremos al final).
Mito 1: "antes era ranking, ahora es generación"
Uno de los argumentos que más veo últimamente, y promovido en última ocasión por Joshua Budman, es que los buscadores han dejado de hacer ranking para pasar a hacer generación. Lo cual es falso.
El pipeline de un sistema RAG (AI Overviews, ChatGPT...) tiene tres fases. Primero, el buscador recupera documentos candidatos (Recuperación). Luego filtra los mejores según señales de autoridad y relevancia (Selección). Finalmente, el LLM usa esos documentos para construir la respuesta (Generación).
Si tu contenido queda fuera del conjunto de candidatos por falta de señales de ranking clásicas, el LLM nunca lo verá. Da igual lo bonito que sea tu chunk.
Es decir, el pipeline sigue siendo: Recuperación (Ranking/Retrieval) → Selección (Re-ranking/Filtering) → Generación. Si no pasas el filtro de ranking, no existes para la generación y si troceas mal, te llevas de regalo canibalización, duplicidad y señales diluidas.
Además, Budman, en su análisis, elimina las variables de ranking de la ecuación. Curiosamente, el paper original de RAG que él mismo enlaza sí las incluye. Y más curioso es que su propio ejemplo de Zapier (el único que ha usado para demostrar su argumento) muestra la pillar page en posición #1 orgánico, contradiciendo su tesis. Por lo menos él mismo admite que "el SEO clásico sigue ganando por ahora"... ¿entonces por qué hacer tanto ruido?
Mito 2: "penalización por longitud"
También se está argumentando que las páginas largas pierden relevancia matemática frente a las cortas. Vamos a ver qué hay de cierto.
Se está diciendo que BM25 penaliza los documentos largos. En realidad, BM25 (evolución de TF-IDF) introduce un término de normalización por longitud (1 − b + b · |D|/avgdl) cuyo objetivo es ajustar la frecuencia del término en función de la densidad del documento, no castigar documentos largos de forma arbitraria.
Además, Google lleva usando Passage Ranking desde 2020. Esto significa que evalúa y recupera pasajes individuales dentro de una página. No necesitas una página corta para ser recuperable porque el sistema ya extrae los fragmentos relevantes por ti.
Mito 3: "la mezcla semántica ensucia el embedding"
Otra simplificación típica que no para de aparecer es que "si mezclas subtemas en una página, el vector se vuelve impuro y el coseno de similitud (o producto escalar) baja".
Mito 4: "tienes que chunkear tu contenido para la IA"
Y aquí viene la ironía porque los GEO Bros te dicen que trocees tu contenido para que encaje mejor en los chunks que hacen los LLMs. Pero no sabemos cómo lo hacen. ¿Cortes de 500 tokens? ¿1000? ¿Overlap del 20%? ¿Heurísticas semánticas o por estructura DOM? Nadie lo sabe. Estás optimizando para un algoritmo que desconoces.
🔄 Update (9 enero 2026): Danny Sullivan en Search Off the Record ha dicho exactamente esto: no trocees tu contenido en "bite-sized chunks" pensando que así le gusta a los LLMs. Y añade: aunque hoy te funcione, "tomorrow the systems may change". Estás invirtiendo esfuerzo en optimizar para un algoritmo que desconoces y que además va a evolucionar.
La realidad creo que es mucho más simple: si un humano puede entender un párrafo sin contexto adicional, cualquier sistema de chunking funcionará bien con él. Escribe claro y directo porque el mejor chunking es el que no tienes que pensar.
Para entender por qué el contenido consolidado funciona, debemos de mirar lo que creemos que sabemos de la arquitectura de Google:
Navboost "penaliza" tus micro-páginas: Gracias a las filtraciones del juicio antimonopolio sabemos que Navboost es una señal basada en el comportamiento del usuario que se alimenta de clics satisfactorios y largos (long clicks). Si atomizas tu contenido, obligas al usuario a hacer pogo-sticking: entra, no encuentra la info completa, sale, busca otro resultado. Tu métrica de satisfacción se desploma y Navboost hunde tu ranking. El contenido consolidado retiene al usuario y acumula señales positivas.
RankBrain agrupa intenciones: RankBrain ayuda a Google a entender que distintas queries tienen la misma intención subyacente. Cuando creas páginas separadas para variaciones semánticas mínimas, estás luchando contra el agrupamiento de intención que hace RankBrain. Google preferirá una URL que satisfaga el centro de gravedad de esa intención agrupada. Yo deduzco además que QBST y Term Weighting son componentes de RankBrain.
Query Augmentation y el "Fan-Out": Un reciente estudio de Surfer SEO ha descubierto una correlación del +161% entre ser citado en AI Overviews y rankear para la main query más sus fan-out queries (sub-preguntas). La lectura que tenemos que hacer es que esto valida los Topic Clusters de toda la vida... Google usa Query Augmentation (expansión de consulta), por lo que si tienes una Pillar Page robusta, cubres léxica y semánticamente tanto la query original como sus expansiones. Al consolidar, maximizas tu puntuación en sistemas como RRF (Reciprocal Rank Fusion), que premia a los documentos fuertes tanto en vocabulario como en cobertura temática. Y oye, en ChatGPT y otras IAs que hacen fan-out esto también es así como explico aquí. Y otro dato del estudio es que el 54% de las citas visibles en AI Overviews (posiciones 1-3) rankean orgánicamente. Si quieres estar en las citas que importan, primero tienes que rankear.
Information Co-Location en agentes de deep search: El paper SAGE de Google (enero 2026) analiza cómo entrenan a sus agentes para tareas de búsqueda compleja. Identifican que en el 35% de los casos, cuando la información necesaria está co-localizada en el mismo documento, el agente resuelve en un solo hop lo que deberían ser múltiples búsquedas. Otro 21% de las veces, una query bien formulada colapsa varios pasos porque el documento cubre el tema de forma completa. Consolidar contenido semánticamente relacionado reduce la complejidad de búsqueda para los agentes y aumenta la probabilidad de que te usen como fuente.
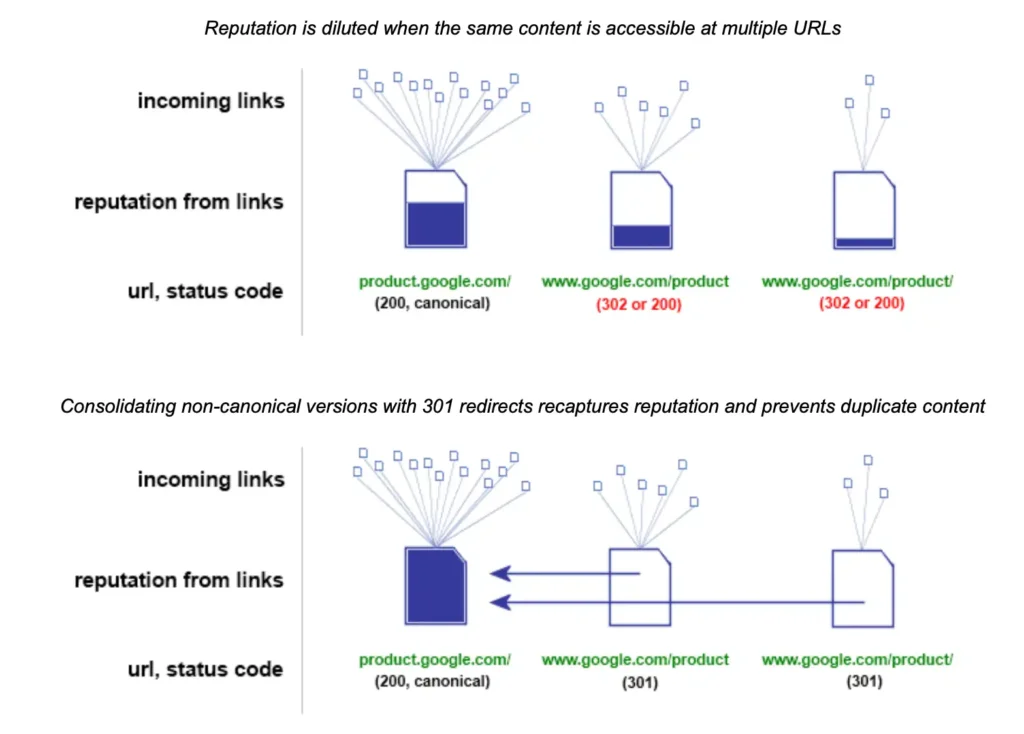
Si mi análisis no te convence, escucha a lo que acaba de decir Microsoft. El equipo de Bing publicó recientemente un aviso sobre el contenido duplicado o "near-duplicate" en la era de la IA. Dicen que cuando existen varias versiones de la misma página, las señales se vuelven confusas/difusas. ¿Lo podríamos llamar Intent Signal Blurring (difuminado de señales de intención)? Es más fancy que dilución de señales 😀
Cuando troceas un tema en cinco páginas con contenido solapado ("Qué es X", "Ventajas de X", "Cómo usar X"), los LLM tienden a agrupar URLs similares y elegir solo una para representarlas. A menudo eligen la equivocada. Mientras tanto, tus enlaces, clics y autoridad se dividen entre cinco URLs débiles en lugar de concentrarse en una fuerte.
Bing acaba diciendo en el artículo que "para el SEO y la IA, menos es más".
Entonces: ¿qué hacer a día de hoy?
No defiendo las Pillar Pages sin más, lo que defiendo consolidar cuando la SERP (tras ser ordenada por el usuario) lo piden.
Mi regla es analizar la SERP para la queries similares. ¿Google muestra resultados distintos que para la query general?
Si sí, crea una página específica porque la intención es distinta.
Si no, o se solapan mayoritariamente, consolida.
Ojo, porque consolidar sin UX es un suicidio. Defender el contenido consolidado no significa defender un "muro de texto" de 5.000 palabras imposible de navegar.
Si gracias a tu autoridad temática logras rankear para una query muy específica (ej: "cuál tiene mejor cámara telf X o telf Y"), pero el usuario aterriza en la cabecera de tu mega-guía y tiene que hacer scroll manual durante dos minutos para encontrar el dato, se va a ir. Y ahí Navboost te matará igual que si tuvieras una página pobre.
Para que la estrategia de consolidación venza a la especificidad de las micro-páginas, tu contenido debe tener una arquitectura de información impecable que permita la recuperación inmediata de la respuesta:
Anclas HTML y ToC: Vitales. No solo para que el usuario navegue, sino para permitir que Google entienda la estructura y ejecute el Scroll-to-text-fragment (llevando al usuario directo al párrafo resaltado).
Módulos visuales y semiótica: El usuario no lee, escanea. Si tu sección habla de "Cámaras", usa iconos de cámaras, gráficos de barras o comparativas visuales. El cerebro procesa la imagen 60.000 veces más rápido que el texto. Si el usuario ve una sección de vs., un icono de una cámara y una tabla con "Checks verdes", sabe que ahí está la conclusión sin necesidad de leer nada.
Tablas y listas > párrafos: Si estás comparando especificaciones, una tabla es infinitamente más eficiente (para el humano y para la extracción de datos del LLM) que tres párrafos de prosa.
Diseño de respuesta directa: Si una sección responde a una pregunta concreta, ve al grano. Coloca la respuesta en las primeras 2 líneas de la sección. No des rodeos.
Si haces esto bien, consigues lo mejor de los dos mundos y la resolución inmediata de intención del chunk sumará puntos a tu Pilar Page.
Así que deja de optimizar para una base de datos vectorial imaginaria y antigua. Los usuarios no quieren visitar cinco páginas para entender un concepto. Los buscadores no quieren gastar recursos rastreando duplicados. Y los sistemas RAG necesitan fuentes de autoridad que hayan pasado primero el filtro del ranking.
Optimiza para la realidad de los buscadores híbridos con señales fuertes, autoridad consolidada y satisfacción de usuario.
Cada vez que un nuevo concepto o sigla asoma en el mundo del marketing digital, GEO, AEO, LLMO, GAIO, LSO, LEO, etc. el debate gira en torno a si estamos ante una verdadera revolución o si es la misma estrategia de siempre con otro nombre. Mi experiencia es que la optimización para grandes modelos de […]
MUVERA (Multi-Vector Retrieval Algorithm) es un paper de investigación de Google publicado en arXiv el 29 de mayo de 2024. Su objetivo es mejorar la eficiencia de la recuperación semántica multivectorial (como la que usa ColBERT), transformándola en un problema de recuperación monovectorial mediante una técnica llamada Fixed Dimensional Encodings (FDEs). Es decir, se trata […]