Qué es y cómo resolver la canibalización en SEO (con ejemplos)
En este artículo presento un framework para resolver la canibalización de palabras clave en SEO. Veremos cómo prevenir y solucionar cuando varias URLs compiten por la misma consulta, reduciendo la visibilidad de todas ellas. Todo ello explicado con ejemplos reales. Al final, comparto un vídeo y un script para que podáis monitorizar estos problemas de una forma sencilla.
Qué es la canibalización
La canibalización ocurre cuando 2 o más URLs compiten para una misma keyword.
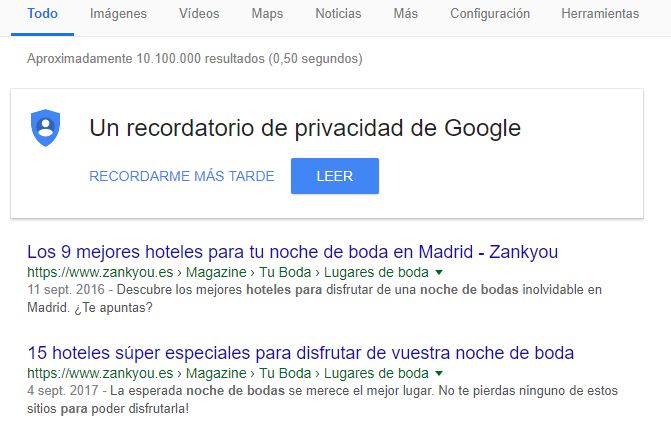
Tener canibalización no siempre es perjudicial si las URLs están en el top 10 (cuanto más arriba mejor). Por ejemplo, si buscamos desde Madrid “hoteles para noche de bodas”, en zankyou tenemos rankeando 2 resultados de zankyou en 1ª y 2ª posición:
Gracias a esto, ocupamos más espacio en la SERP de Google, aumentado las probabilidades de que se clique nuestro resultado:
En cambio, la canibalización es negativa cuando estamos en 2ª página. Es una señal de que las URLs canibalizadas no son relevantes y Google tiene dificultades para posicionar una u otra, robándose así los rankings entre ellas.
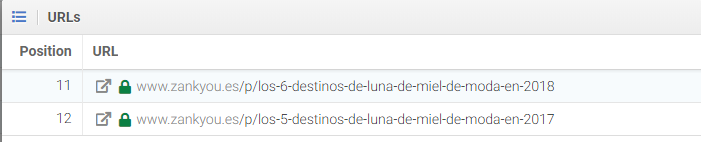
Si buscamos “destinos luna de miel” tenemos 2 artículos que están rankeando 11 y 12:
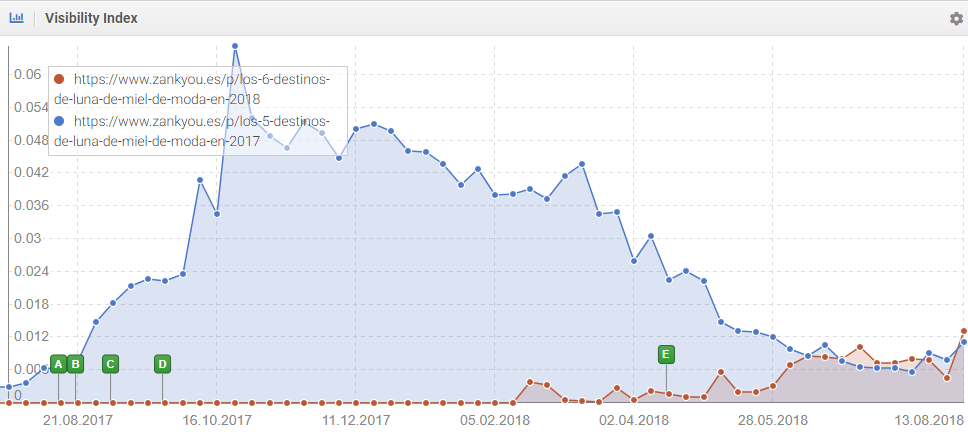
Si analizamos la viabilidad, vemos como el día que se escribe el segundo artículo, éste empieza a robarle importancia al primero. Se observa además cómo incluso en 2018, el artículo de 2017 llega a tener más visibilidad en dos ocasiones que el de 2018, lo cual no tiene sentido:
En SEO la suma de visibilidades no es igual a doble de visibilidad (1 + 1 ≠ 2)
Además, puede verse claramente como cuando se escribe el 2º artículo (el 07/02/18), empezamos a bajar para esa keyword hasta desaparecer de la primera página de Google:
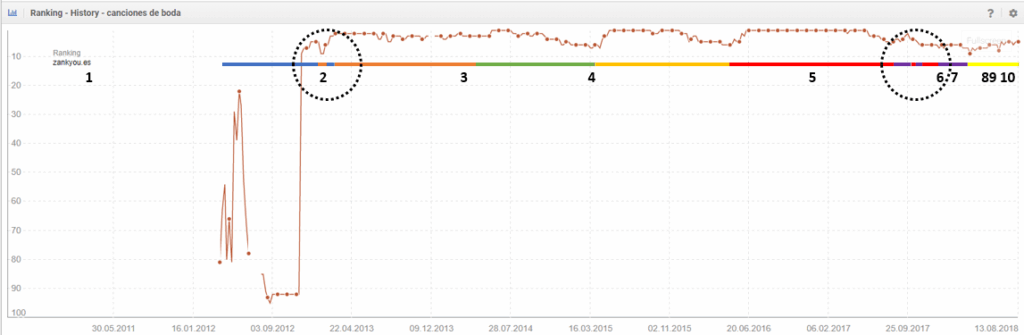
Con la keyword “canciones de boda” ocurre lo mismo, tenemos diversos artículos luchando por la misma query:
En el tiempo se puede ver cómo en ocasiones se han ido quitando continuamente los rankings y en concreto la canibalización se producía en los 2 puntos que vemos en la imagen siguiente:
Hasta en 3 ocasiones hemos estado primeros en el ranking (con los post 3, 4 y 5) y con con cada nuevo post se han perdido las posiciones ganadas hasta pasado un tiempo. Además, cuantas más actualizaciones se han hecho de los post (al la derecha del todo) todavía más ha repercutido en los rankings y en la canibalización. Así como que los artículos 6, 9 y 10, no han llegado a rankear en Google.
Si cogemos los 4 artículos que están teniendo tráfico a día de hoy, vemos como estos se están quitando la visibilidad entre ellos, cuando aparece uno se hunde el otro (la visibilidad tiene en cuenta en todas las keywords por las que rankea un artículo, no sólo una):
Además, también se canibalizan con otras keywords de intención similares.
“A” es el número de urls rankeando para esa query
La razón por la que esto ocurre es porque los artículos nuevos se enlazan desde lugares superiores en la arquitectura y los viejos se pierden en la paginación. Es por ello que los articulos importantes siempre tienen que estar enlazados desde lugares estratégicos y por lo cual es importante tener un repositorio de artículos para no pisarte a la hora de escribir uno nuevo.
Como vemos, la canibalización es algo que hay que vigilar y que a largo plazo puede hacer mucho daño como está ocurriendo, por lo que a partir de ahora vamos a prevenir para que esto no suceda.
Cómo prevenir la canibalización antes de que suceda
Antes de escribir un artículo sobre un tema, tenemos que buscar si existen artículos similares. Una de las formas más sencillas de hacerlo es buscar en Google artículos existentes de nuestro dominio de la siguiente forma:
site:<dominio> intitle:<keyword>
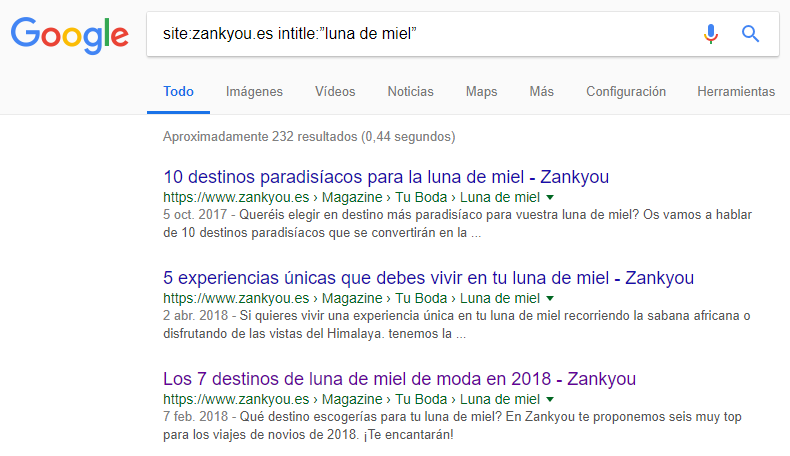
232 resultados para site:zankyou.es intitle:”luna de miel”
La instrucción “intitle:” busca esa cadena de texto en el título de la página y “site:” acota la búsqueda a un dominio específico. También podemos acotar a un path, para buscar dentro de un directorio como “/p/” (para filtrar sólo artículos y que no aparezcan proveedores “/f/”):
site:<dominio>/<path> intitle:<keyword>
208 resultados para site:zankyou.es/p/ intitle:"luna de miel"
También podremos añadir otros “intitle:” para hacer búsquedas más específicas:
265 resultados para site:zankyou.es/p/ intitle:"luna de miel" -intitle:"destinos"
Si al hacer estas búsquedas, aparecen resultados para esa intención, entonces no deberemos hacer un artículo nuevo. Al hacer la búsqueda del ejemplo, nos sale que tenemos ya 31 artículos en zankyou.es:
Así que trataremos de mejorar los que ya tenemos y buscaremos si podemos escribir nuevos artículos u orientar los existentes para otras intenciones.
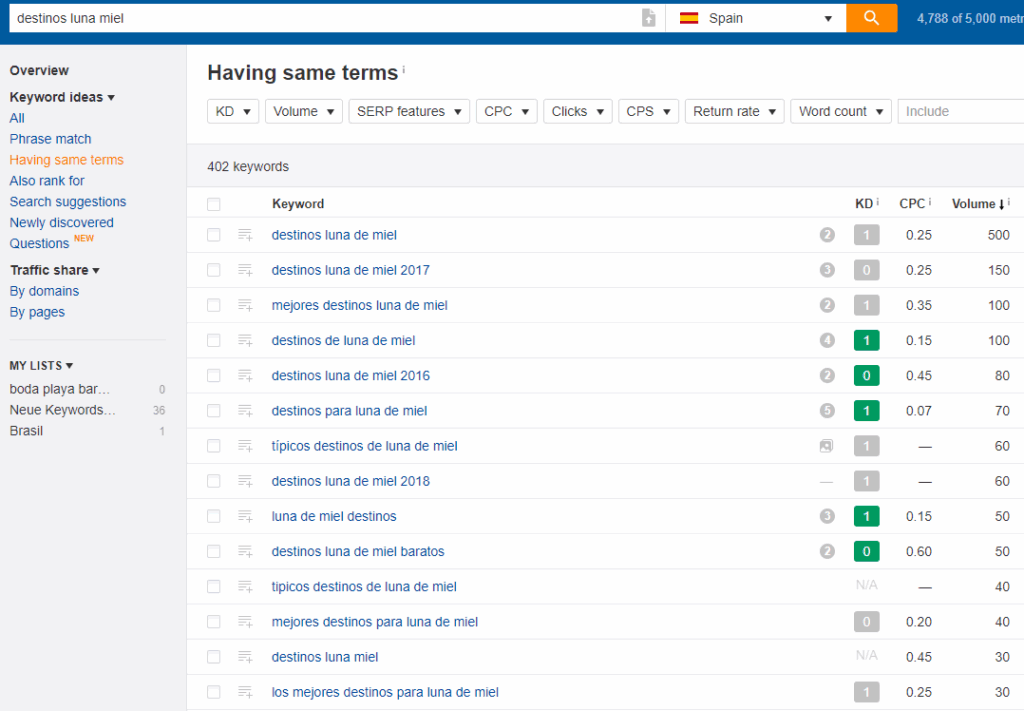
Para descubrir las intenciones de búsqueda haremos uso de ahrefs, sistrix o semrush. Con estas herramienta vemos que para “destinos luna miel” se busca:
Con fecha (contenido cíclico): 2017, 2018...
Tipo: Mejores, paradisíacos/exóticos, con niños/bebé, embarazada...
De aquí podrían salir los siguientes artículos para cubrir diferentes intenciones:
Mejores destinos paradisíacos y exóticos para luna de miel
Mejores destinos de Luna de Miel 2018
Destinos económicos para tu luna de miel ¡Viaja barato!
Luna de miel en México. Descubre sus mejores playas
Destinos para ir con niños en tu luna de miel
¿Luna de miel embarazada? Destinos cómodos de visitar
Destinos para ir en primavera de luna de miel
…
Como vemos, en la lista de los 31 artículos tenemos varios que ya intentan satisfacer la misma intención. En ese caso nos tendremos que quedar con uno, el que mejor rankee para esa intención y/o más tráfico tenga. Si estamos ocupando primera página no haría falta unificarlos, pero si no estamos arriba de todo, quizás deberíamos actualizarlos (con republicación) y mejorarlos.
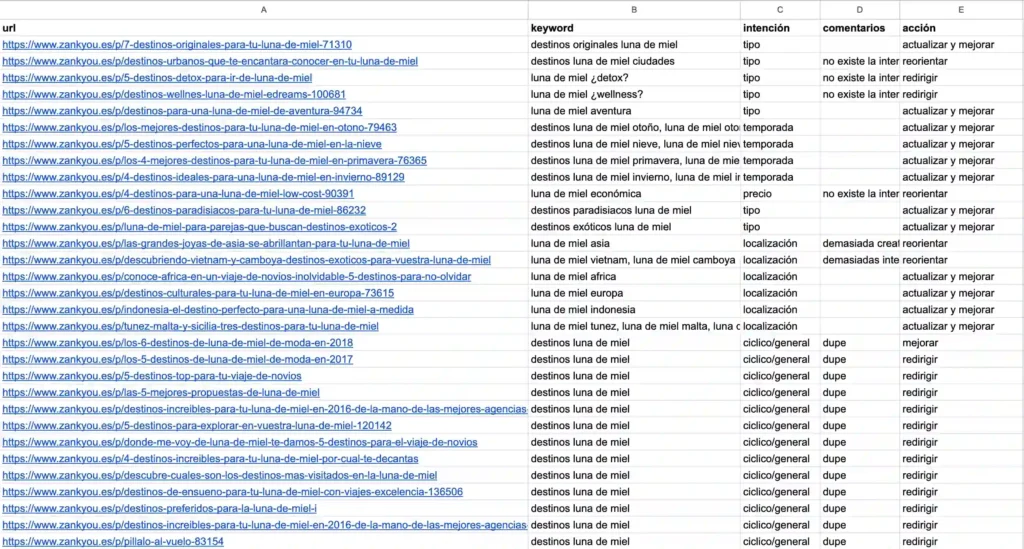
Comparto un posible cuadro de trabajo para los 31 artículos anteriores:
Para evitar los duplicados (en los que además existía canibalización como vimos anteriormente), basta con no escribir cada año un artículo nuevo, mantenemos la url, lo actualizamos y mejoramos si hace falta, republicamos y le cambiamos únicamente el title con la fecha.
En el caso de los vestidos de novia y de las colecciones es otro tema, porque hay gente que busca colecciones anteriores. Con lo cual en ese caso sí que interesaría mantener los antiguos y así nos llevaríamos el tráfico que no se pueden llevar las marcas. Lo único que tendremos que hacer es el poder facilitar que un usuario pueda ver los artículos de las colecciones de otros años.
Resumiendo, podemos ver cómo de un artículo que íbamos a escribir, resulta que al final no hacía falta y teníamos más curro y más oportunidades de mejorar de las que parecía 🙂
Cómo corregir la canibalización existente
¿Qué ocurre ahora con los artículos que ya tenemos canibalizados porque se han detectado al hacer un estudio de canibalización? (al final del artículo comparto un tutorial de cómo encontrar problemas de canibalización con Python)
Si tenemos 2 artículos que reciben tráfico y uno está compitiendo para una query que no teníamos pensando, entonces lo ideal es “de-optimizar” ese artículo para esa query orientándolo más a la keyword por la cual nos interesaba rankear en un principio.
En este punto, sería interesante aprovechar para revisar el otro otro artículo, mejorándolo si cabe, para la query canibalizada.
Podemos ver como estas dos urls son las que aparecen para anillos de compromiso con zafiro, y los dos son completamente distintos. Bastaría con mejorar el title y el h1 del primero a “Anillos de compromiso con zafiro” para orientarlo mejor a esa key, actualizar el artículo si el contenido está desfasado y republicarlo. En este punto estaría bien ver si tenemos más artículos que hablen de lo mismo (utilizando el método anterior), para redirigirlos a los anteriores e intentar añadir el contenido en ellos si tiene sentido.
Otro caso distinto. Si todos los artículos en realidad están luchando para lo mismo, entonces habría que escoger al mejor (ranking/tráfico), mejoramos si hace falta y republicamos. Ej:
En este caso los dos hablan de hacer arreglos y centros de mesa, y el primero dice de hacerlo con frascos, algo que no se busca. Así que el segundo es más general, con lo cual se podría volcar el contenido del primero en el segundo para enriquecerlo como otra forma de hacer arreglos. Miraríamos de mejorar el segundo si hace falta, redirigiríamos el primero al segundo y republicamos.
En este punto estaría bien ver si tenemos más artículos que hablen de lo mismo, para redirigirlos a los anteriores e intentar añadir el contenido en ellos si no existe. Así sería una forma de mejorar el artículo con una información que ya tenemos y la redirección funcionará mucho mejor.
En general, es mejor redirigir que un noindex para salvar posibles links externos. Además, si se decide eliminar pasando a “hidden” un artículo (que añade un noindex y quita el artículo del sitemap), habría que quitar también los links internos hacia ese artículo.
Cómo encontrar problemas de canibalización con Search Console y Python
En este vídeo, me entrevista Hamlet Batista, fundador y CEO de RankSense. Hablamos sobre cómo empecé a usar Python para SEO, a pesar de que al principio no me gustaba programar. Comparto cómo me ayudó a automatizar tareas repetitivas y a resolver problemas complejos de posicionamiento. Explico paso a paso cómo detectar estos casos de canibalización con Python, extrayendo datos de Google Search Console, analizándolos, y aplicando soluciones como consolidar contenido o ajustar la arquitectura del sitio para mejorar el rendimiento SEO.
Desde ayer todos los usuarios que se identifiquen en la versión .com de Google lo harán mediante la versión de búsqueda segura del buscador (con protocolo https) o como ellos lo han llamado Google SSL Search. Dicen que es para mejorar la privacidad de los usuarios logeados, pero ni yo ni nadie se lo cree. ¿Desde cuando […]
Hace más de una década, la optimización de los encabezados tenía un impacto significativo en el ranking. Aunque su influencia ha disminuido, siguen siendo útiles para los motores de búsqueda. Además, los encabezados no solo afectan indirectamente al SEO al mejorar la comprensión del contenido y la interacción del usuario, sino que también influyen en […]