Este artículo es un resumen que hemos hecho Christian Oliveira y yo de la charla que dimos en el Congreso Web (consigue aquí las diapositivas), donde pretendemos explicar esta tecnología (PWA) y cómo tenemos que lidiar con ella SEOs y desarrolladores para hacerla accesible a los buscadores. Nos basamos en la experiencia con clientes que usan frameworks y librerías JavaScript como Angular o React, en sitios JS de conocidos que se han cedido a que analicemos sus casos y en experimentos que hemos hecho para ver cómo los tratan los buscadores.
A día de hoy existen diversas soluciones para resolver las necesidades de los usuarios en móviles. Por ejemplo, en elmundo.es, si quieren ofrecer una experiencia satisfactoria a todos los usuarios que consumen sus noticias, tienen que asegurarse de poder servir cada página correctamente en diferentes ecosistemas: versión mobile y desktop (con Dynamic Serving), APP (para navegación offline, notificaciones push y navegaciones más fluidas), AMP (por el requisito de aparecer el carrusel) y Facebook Instant Articles (el AMP de Facebook).
Como veis, son muchos ecosistemas que se han de mantener a parte de la web y esto es costoso y poco escalable para todos los negocios. Si hablamos de las APP nativas, éstas son las que más dolores de cabeza ocasionan en todos los aspectos:
Los desarrolladores de APPs son escasos y se “roban” entre startups ofreciéndoles sueldos muy suculentos. Aquí en Barcelona, si quieres fichar a un desarrollador de APP, lo más seguro es que esté también en el proceso de selección de Wallapop, Glovo o CornerJob, y quizás no puedas competir contra eso (true story).
Otro tipo de solución que existe a día de hoy para resolver las necesidades complejas y con una carga de interacción más fuerte en móvil, son las Web APP Mobile (en un m. por ejemplo). Estas tienen una serie de inconvenientes:
No permiten navegación offline.
No son indexables en las APP stores.
Es difícil hacer Responsive Web Design (RWD).
Es otra tecnología que tienes que desarrollar y mantener para diferentes versiones de navegadores y sistemas operativos.
Por suerte, a día de hoy existe una nueva solución de desarrollo propuesta por Google, que tiene lo mejor de todos los mundos, las Progressive Web APPs (PWA).
Qué es una Progressive Web APP
Una PWA es una página web que funciona para todos los usuarios y todos los dispositivos, pero manteniendo la experiencia fluida de una APP. Esto es una gran ventaja en webs con interacciones complejas. Por ejemplo, Twitter e Instagram, si entráis desde el móvil, en realidad estáis entrando en una PWA y no en su web. Ya no tiene sentido tener instalada estas aplicaciones consumiéndote recursos y datos en segundo plano, puedes añadirte la página al escritorio de tu móvil y tendrás Twitter o Instagram totalmente funcional. Además, parece que Twitter está pensando en abandonar el desarrollo de su APP, así como Starbucks. Entiendo que esperarán a que más gente se la añada al escritorio y que los números le sigan yendo tan bien.
Entre las ventajas de las Progressive Web APPs a destacar se encuentran:
Son APPs indexables en buscadores (adiós APP indexing).
Las Progressive Web Apps están hechas con Frameworks y librerías JavaScript que se están estandarizando porque facilitan la tarea de creación de entornos web. Este enfoque de desarrollo tiene las siguientes ventajas:
Facilitan el trabajo a los desarrolladores porque conceden una mejor integración con otros lenguajes. Son modulares, limpios y facilitan la reutilización de código. Así mismo, cuentan con una comunidad enorme muy activa y colaborativa.
Mejor rendimiento y velocidad (para el servidor sobre todo en Client Side Rendering como veremos). Para el backend son mejores en este punto que PHP, Java, ASP…
Al ser open source son más económicos y puedes encontrar a más desarrolladores. Y no paran de salir nuevos Frameworks que mejoran a sus predecesores (Vue JS por ejemplo es mucho más fácil que aprender que React JS, una de las razones por las que lo está desbancando).
Son tecnologías más seguras gracias a la gran comunidad y a los big players que tienen detrás (por el lado de Angular está Google y de React JS está Facebook).
Como consecuencia de sus ventajas, este nuevo paradigma ha llegado para quedarse, así que a los SEOs y a los buscadores nos toca amoldarnos a él, porque el crecimiento es imparable.
Según la encuesta anual de Stack Overflow que hicieron a 64.000 desarrolladores, JavaScript es el principal lenguajes de programación y Node JS, Angular y React JS se encuentran entre las cinco tecnologías de desarrollo más usadas a día de hoy.
Cómo funciona una Progressive Web APP
Una PWA es una SPA (Single Page Aplication o Multiple Page Aplication) a la cual se le hacen dos añadidos que son los que les brindan todas sus virtudes, el service worker y el manifest.
El service worker es la magia de las PWA. Es el que permite la sincronización en segundo plano, la conectividad offline y las notificaciones push.
Funciona a nivel de controlador y se sitúa entre el cliente y navegador. Se encarga de decirle a la caché del navegador que guarde archivos a los que se ha accedido para que, luego, la caché los mande al cliente sin necesidad de pasar de nuevo esa petición por el servidor (por eso son offline).
El manifest es un fichero pequeñito en formato JSON que se declara en el head del documento HTML. Entre otras cosas, la funcionalidad principal de este fichero es la de permitir que la PWA se pueda instalar en el escritorio para que parezca una APP.
A día de hoy todos los navegadores soportan PWA, pero no todos los navegadores soportan todas las funcionalidades de las PWA. Por suerte, esto está cambiando rápidamente como podréis ir consultando en Can I use.
SEO y JS: Cómo tratan JavaScript los buscadores actuales
A día de hoy sólo Google y ASK renderizan JS en cualquier Framework de forma decente. Baidu ha anunciado que también lo hace, pero según las pruebas que hemos hecho, parece que tiene bastante menos éxito de momento. Con lo cual, si vuestro negocio está en EEUU, Rusia o China, no podemos depender de que Bing, Yahoo, Yandex o Baidu rendericen el JS y tendremos que, sí o sí, entregarles el contenido pre-renderizado y que ningún texto y/o link interno dependa de JS para ser visualizado.
Crawlear =! Renderizar =! Indexar =! Rankear
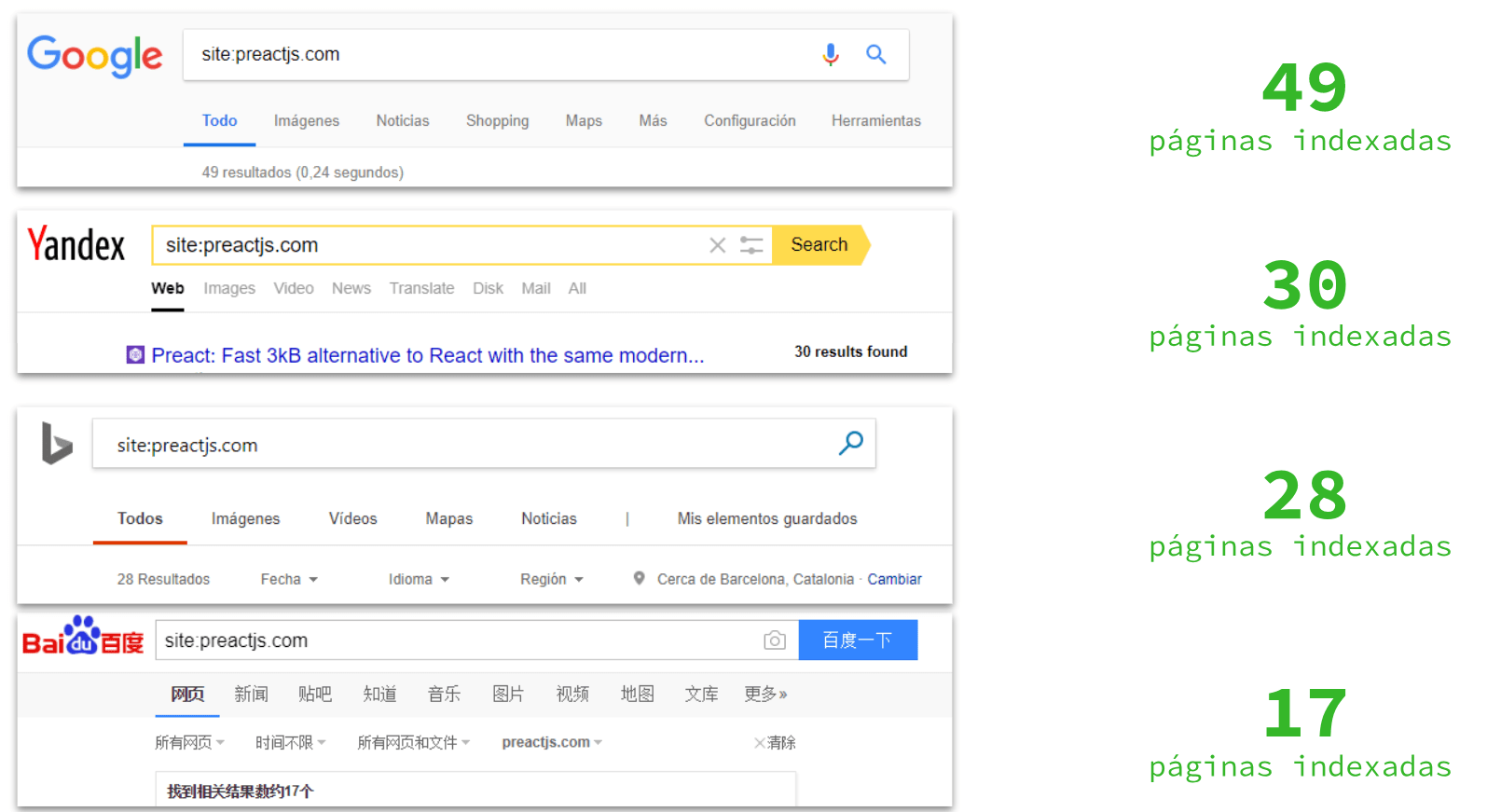
Cuando hablamos de las habilidades de un buscador para renderizar JS, se suelen hacer este tipo de pruebas erróneas que veis en la imagen siguiente. Como veis, el número de páginas indexadas varía en cada uno de estos buscadores. Esto se hace con un «site:» sobre un sitio que depende de JS para poder ser visualizado y rastreado:
Que el buscador tenga un número X de URLs indexadas no demuestra que las haya descubierto al renderizarlas, ni que sea capaz de ver 100% el contenido que hay en ellas.
Si por ejemplo probáis a buscar algunas cadenas de texto de preactjs.com en los diferentes buscadores, veréis que en algunos casos sólo Google y ASK han sido capaz de verlo.
Renderizar un sitio en JS cuesta mucho
Entonces, si las PWA se están poniendo tan de moda y cada vez más sites utilizan JS, ¿por qué no todos los buscadores renderizan JS? Muy sencillo; porque es muy costoso (y por lo tanto, caro).
Aquí es importante entender que por ejemplo 170 KB de JS no son lo mismo que 170 KB de una imagen; aunque el navegador tarde más o menos lo mismo en descargar ambos ficheros, la imagen se visualiza de forma súper rápida (en cuestión de milisegundos), mientras que el JS además de descargarse tiene que ser parseado, compilado y ejecutado por el navegador, consumiendo recursos y tardando más tiempo.
Para que os hagáis una idea del coste que puede tener para un crawler, aquí tenéis unos datos que ahrefs ha compartido. Cada 24 horas:
Crawlean 6 billones de páginas
Renderizan 30 millones de páginas.
Para ello utilizan 400 servidores
Si echáis cálculos por cada página que renderizan, crawlean unas 200. Según ellos mismos, si decidiesen crawlear y renderizar todas las URLs que tienen en su base de datos a este ritmo, estiman que necesitarían entre 10000 y 15000 servidores más (entre 20 y 30 veces más), así que imaginaos el gasto que puede suponer a nivel de empresa en máquinas, electricidad, mantenimiento…
Google no espera indefinidamente a renderizar
Debido a ese alto coste que existe en renderizar JS, aquí entra otro factor: Google no puede esperar indefinidamente hasta que una página termine de renderizar.
Esto lo descubrí porque tenía que ocultar un popup y un modal selector de idioma para que Google no los considerara intrusivos. Lo que hice fue cargarlos después del document ready para que no aparecieran en el DOM y les iba aplicando segundos de delay. Al final observé que con 5 segundos dejaron de aparecer en el render y en la caché de Google. Pero si te quieres asegurar, mejor que carguen tras una interacción del usuario, así te aseguras que no lo ejecute Google.
¡Ojo! Esto es un número orientativo, que puede variar por website y/o a lo largo del tiempo (Lino ha comprobado que puede ser más). Si queréis tener la certeza de que Google está siendo capaz de renderizar y ver todo vuestro contenido, además de comprobarlo a nivel de indexación, lo mejor es ver si es así en la Mobile-Friendly Test Tool, e intentar que la web renderice lo más rápido posible.
Si sois frikis como nosotros del IR y la IE, os resultará curioso saber que antes de Percolator (del que ya os hablé aquí), Google hacía uso de MapReduce y Google File System (gracias a los cuales nació Hadoop). Simplificando mucho, antes de esta nueva arquitectura, Google funcionaba en batch y ahora lo hace al vuelo. Esto hace que las páginas crawleadas se indexen prácticamente de inmediato.
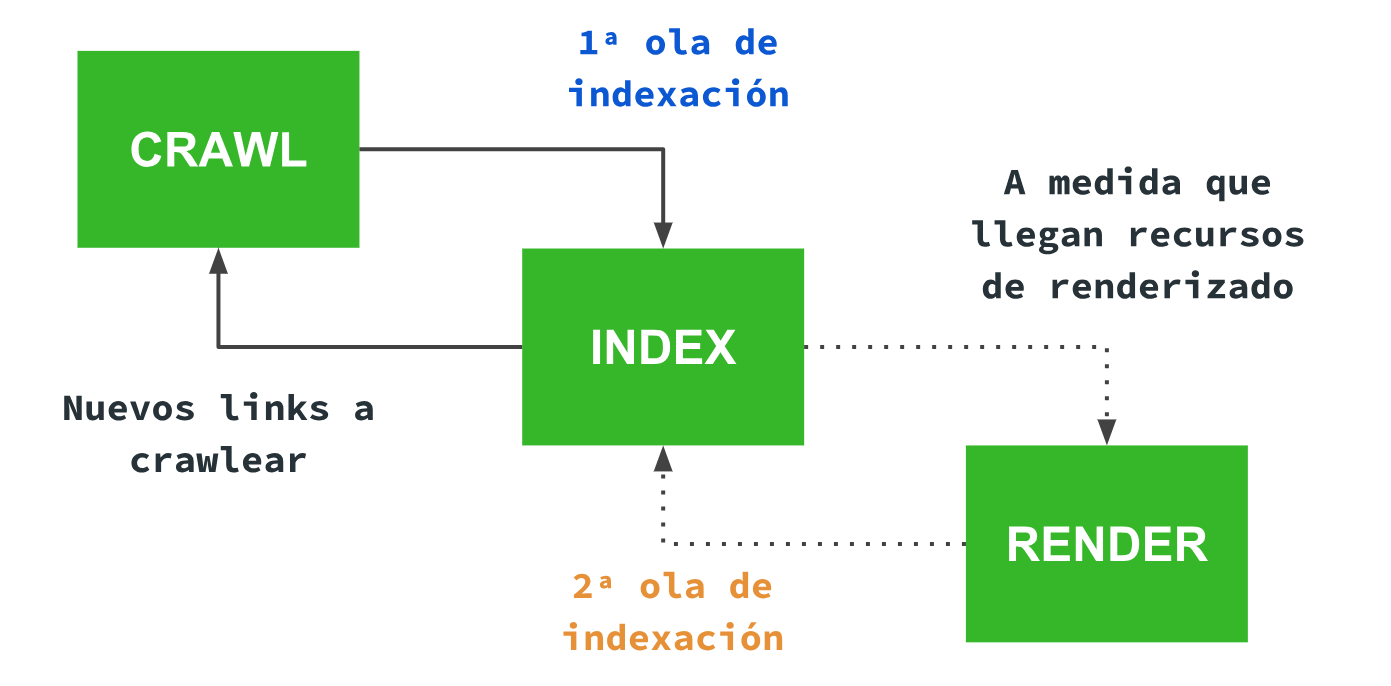
El problema viene con los sitios JS, porque tiene que renderizarlos para poder ver qué contenido y links existen para asignar queries a urls, si no, Google se estaría perdiendo una gran parte de la web. Como hemos visto antes, esto es costoso y no puede hacerlo al instante porque eso le haría consumir hasta 200 veces más de recursos tranquilamente. Por ello tiene que indexar los sitios JS en dos fases.
Una de las cosas en las que nos afecta y que tenemos que conocer es que las etiquetas canonical, rel=amphtml y el status HTTP, en el fetch inicial y no les da una 2ª oportunidad en el render. Lo del rel=amphtml no tenía ni idea hasta que lo dijo John Mueller.
Las veces que lo he probado no me ha salido, y es que realizar experimentos con canonical es harto difícil por varias razones:
Es una sugerencia, no una directiva.
El enlazado interno y externo de una url influye en el canonical.
La similitud de las páginas influye en el canonical. He hecho varias pruebas y he visto que a partir del 70-75% de similitud entre el MC de las páginas, empieza a funcionar mejor. Y tengo la sensación que no mira otros elementos importantes como el title para estos casos, y meditándolo bien, no tendría sentido que usara el title. La razón es porque podría liarla mucho teniendo en cuenta es común tener contenidos distintos en URLs con titles iguales por temas del CMS. Pero no puedo dar nada por concluyente.
Hay que tener paciencia, Eoghan ha esperado mucho tiempo para ver el efecto.
Y si llegase a funcionar en algunos casos, esto no quiere decir que esta meta no deba de estar sí o sí en el raw HTML, porque, es la única forma de asegurarnos que lo verá sin problemas (otra cosa es que quiera hacerle caso).
Por otro lado, si el Noindex, Hreflang y rel=next/prev no están en el raw HTML, Google los leerá en la versión renderizada (les da una segunda oportunidad). Lo del noindex y el hreflang lo pude comprobar hace tiempo, pero no se me ocurrió mirar las metas rel=next/prev hasta que lo mencionó Robin Rozhon en su Twitter. Además lo del noindex, lo acaba de confirmar recientemente Google.
Aquí lo mismo de antes, nos tiene que ser indiferente que les dé una segunda oportunidad, porque el delay que existe entre renderizar e indexar puede llegar a ser muy largo, y durante un tiempo tendremos un montón de documentos que quizás no querríamos tener en el índice, lo que puede afectarnos de forma negativa temporalmente. Así que como buena práctica, a Google y otros bots siempre hay que darle las metas en el raw HTML.
Otro de los puntos en los que nos afecta que Google use Chrome 41, es que tiene dificultades para renderizar webs con funciones más avanzadas a las de esta versión de Chrome. En el caso de querer usar funciones modernas, debemos traducir esas funciones a otras soportadas por Chrome 41.
*Que no sea rastreado no quiere decir que si alguien enlaza su urls se nos indexe. La mayoría de errores de indexado de filtros viene por problemas de este tipo.
Creo que fue hace 7 años, cuando en el Search Console de un cliente se dispararon los 404 coincidiendo con una implementación de páginas virtuales de Google Analytics. Desde entonces, todo lo que tenga forma de URL en el DOM lo meto en el robots.txt, pero mejor es que se modifique el link en el código para que no tenga barra.
Existen otros tipos de eventos que son los onscroll y los onmouseover. Los eventos onscroll los sigue a veces y onmouseover no los sigue.
Si tienes una paginación con onscroll puede llegar a indexarse (sólo las primeras páginas). Otra de las cosas que descubres por casualidad y se agradece que Google lo confirme.
Soluciones de renderizado para sitios JavaScript
Para comprender las opciones existentes de renderizado, lo más fácil es entender que las PWA son el IKEA de internet.
Tradicionalmente, cuando nosotros (clientes) queremos comprar un mueble, vamos a una tienda especializada (empresa), elegimos el mueble y nos lo entregan listo para utilizar.
Más tarde surgió IKEA, donde el cliente elige el mueble, pero en vez de recibir el producto final, lo que recibe es una serie de partes y unas instrucciones de montaje, y es él el que tiene que realizar la tarea física de montar el mueble para tener el producto final que ha comprado. Además, a veces para poder montar el producto tenemos que comprar más cosas (ya sean tornillos especiales, herramientas especiales, etc.). Todo viene explicado en las instrucciones.
Llegado un momento, IKEA detectó que algunos clientes querían sus productos, pero no querían realizar la actividad física de montar el mueble, así que lanzaron un nuevo servicio: puedes comprar el mueble y que alguien de IKEA te lo monte y lo entregue montado
Con este analogía, el cliente sería nuestro navegador web, e IKEA sería el servidor, y en base a esto tenemos 4 posibles escenarios a la hora elegir el sistema de renderizado:
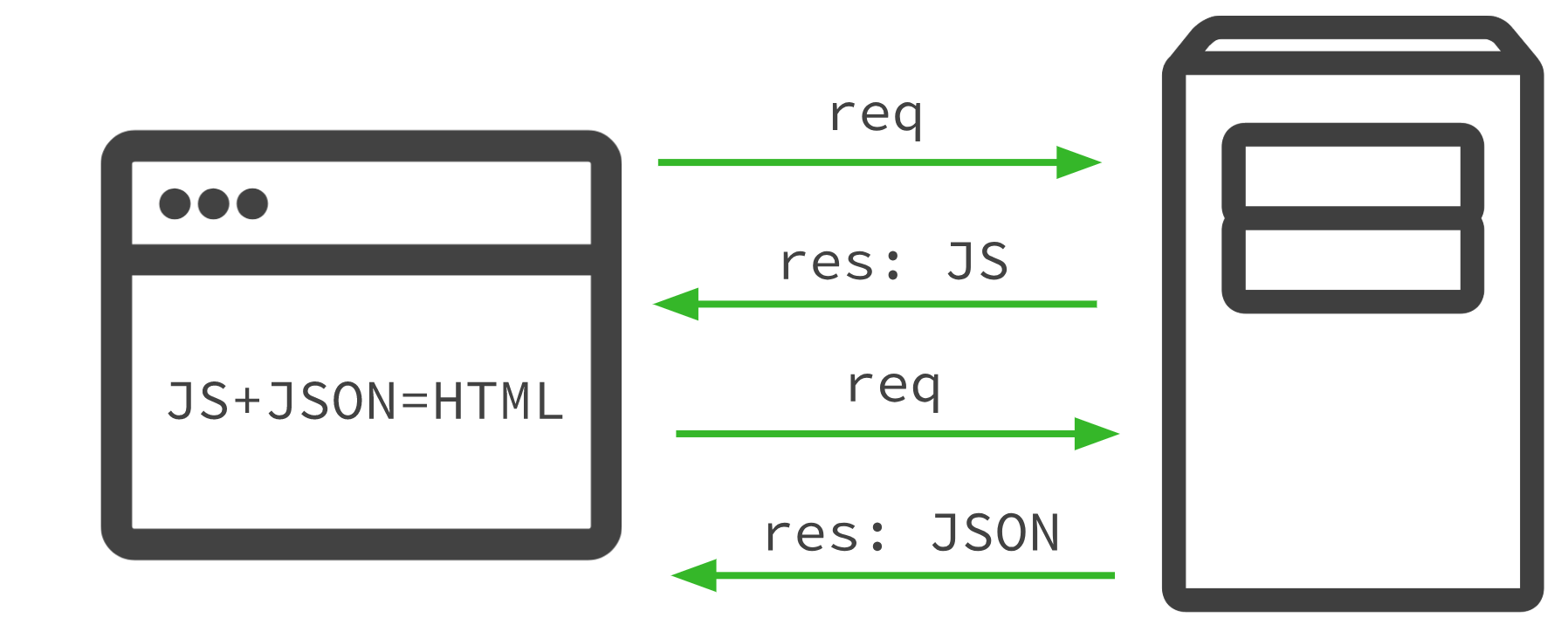
Client Side Rendering (CSR)
Cuando hablamos de Client Side Rendering puro, el cliente (navegador web) recibe un HTML inicial en blanco, y es el navegador el que tiene que “crear” el HTML final en base a los recursos y el JS que recibe del servidor:
Esta opción es la que inicialmente utilizaban (y en muchos casos utilizan) los desarrolladores de PWA, y es la que más problemas genera para SEO ya que sin ejecutar el JS y renderizar la página, no hay nada (ni contenido, ni enlaces).
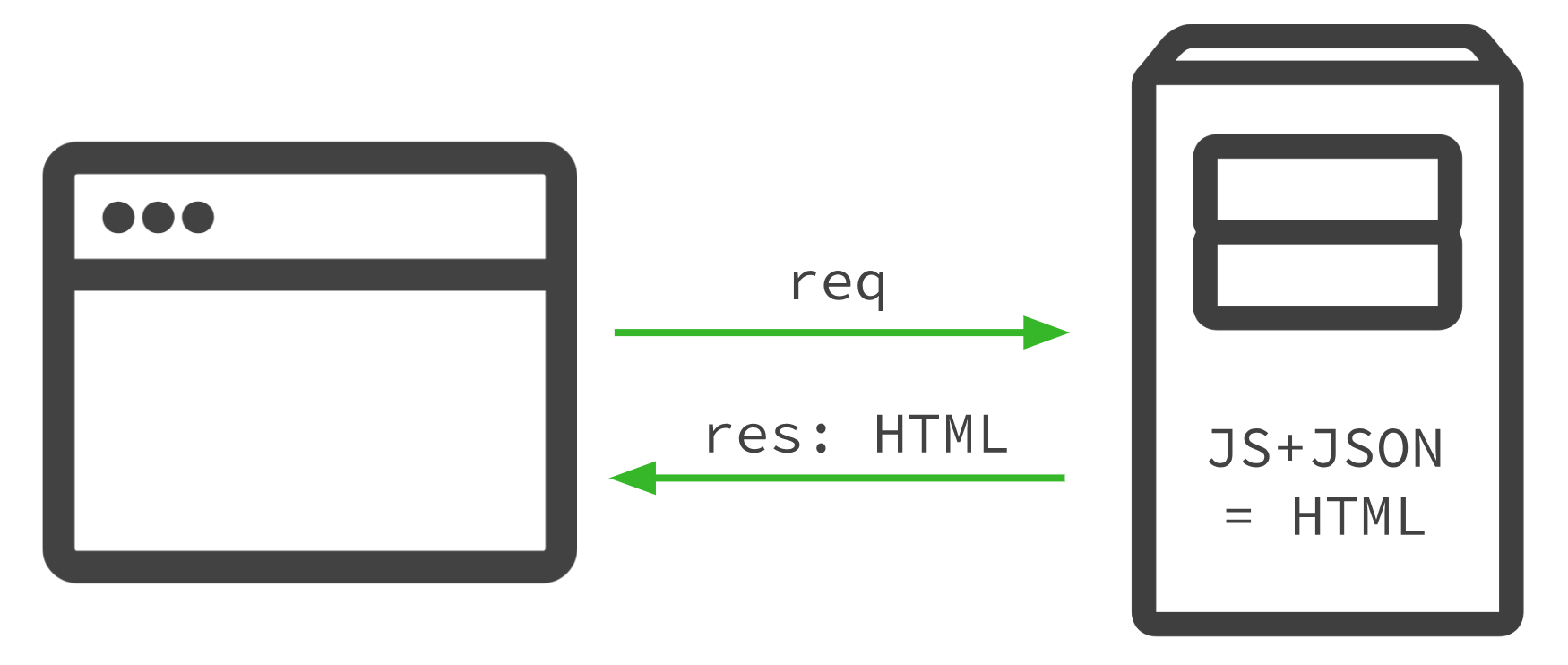
Server Side Rendering (SSR)
Debido a los problemas de SEO del CSR, y al igual que IKEA, los frameworks de PWA empezaron a desarrollar una nueva funcionalidad, para que sin dejar de tener todas esas funcionalidades de PWA, antes de enviar la información al cliente (navegador) el servidor ejecutase y renderizase el JavaScript desde su lado y se lo enviase al cliente.
De esta forma, el cliente (navegador) recibe un HTML final y que funciona sin necesidad de ejecutar y renderizar el JavaScript. Si tiene JavaScript activado, éste toma el control y el usuario puede seguir navegando/interactuando con la PWA con todas las funcionalidades. Si no tiene JavaScript activado, también, aunque sin todas las ventajas de las PWA.
Hybrid Rendering
La tercera opción de renderizado es una combinación de las dos anteriores: parte de la página se envía pre-renderizada desde el servidor, y otra parte se renderiza en cliente.
Un caso de uso muy común del Hybrid Rendering es el de pre-renderizar aquellas partes de la página que se utilizan en toda la PWA (por ejemplo, un menú), y dejar que sea el cliente el que renderice todo aquello que cambia según la página (el contenido específico). En el siguiente ejemplo, la “App Shell” (la zona superior, con azul de fondo) se entregaría pre-renderizada en el servidor (SSR) mientras que la parte de abajo (el contenido) no aparece inicialmente y se renderiza enteramente en el cliente (CSR).
Dynamic Rendering (DR)
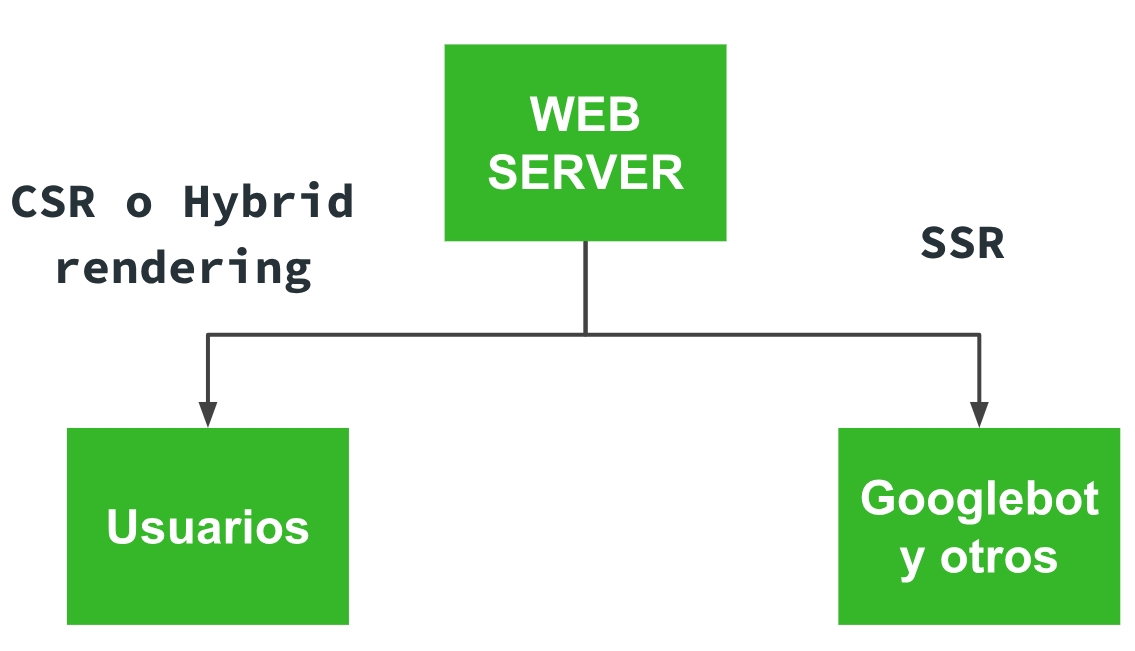
Esta es la opción que veníamos usando los SEOs y que Google acaba de recomendar de forma oficial en su charla del Google IO. Consiste básicamente en… ¡hacer cloaking!
Sí, como lo lees. Lo que han comentado es que si tenemos una PWA cuya visualización depende de la ejecución de JS y su renderizado, si queremos evitar problemas tenemos que asegurarnos de que Googlebot (y otros bots) recibe una versión SSR, y el resto de User-Agents aquella que consideremos mejor (CSR o Hybrid Rendering). De esta forma, Googlebot va a poder ver el contenido y enlaces de cada página sin necesidad de ejecutar JS y renderizar la página. En el fondo, el contenido que ve Google será el mismo que el que verán los usuarios una vez el cliente renderice la página.
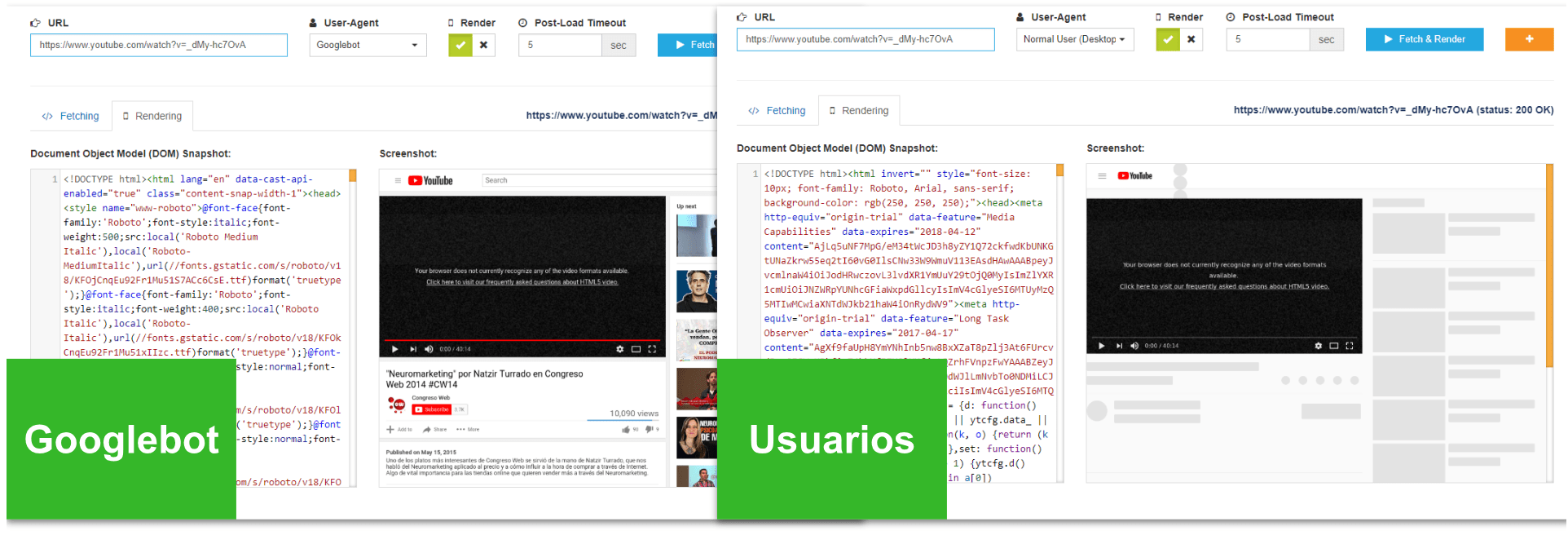
Un ejemplo de una web muy grande que está aplicando esto, y que es del propio Google, es Youtube y no le va nada mal. En las siguientes capturas (lo podéis probar directamente con esta tool) podéis ver que al acceder a la URL de un vídeo, si el que lo pide es Googlebot recibe la página con el contenido y enlaces, y si en cambio el que lo pide es un usuario normal, recibe un html incompleto, con un esqueleto pero sin ningún contenido ni enlace:
SSR preferible para usuarios, CSR preferible para sistemas
¿Qué estrategia es preferible entonces en cada caso? Para los usuarios, al menos en la primera interacción, lo mejor es el SSR:
Netflix, cuya web es una PWA construida con React y que ha apostado fuerte en este tecnología, vio un incremento del 50% en el rendimiento de sus landing pages (aquellas que utiliza para captar usuarios) al pasar de CSR a SSR.
¿Por qué? Muy sencillo. Repasamos cómo funcionan estas dos técnicas:
En SSR, el servidor envía un HTML “final”, con todo el contenido y enlazado listo sin necesidad de renderizar.
En CSR, el servidor envía un HTML vacío, que es “rellenado” luego una vez que el navegador ejecuta el JS y renderiza la página.
Esto ocasiona que:
En CSR, el servidor tarda menos en responder (y por lo tanto tendremos un mejor TTFB), mientras que en SSR el servidor tiene que utilizar más recursos para hacer el renderizado y por lo tanto tarda más.
En SSR, el navegador recibe un HTML “final”, que el navegador es capaz de pintar rápidamente y el usuario empieza a ver el contenido más rápido. El CSR, por el contrario depende de la potencia del dispositivo del cliente, y tarda más (mucho más en el caso de dispositivos lentos) en llegar a renderizar y visualizar la página.
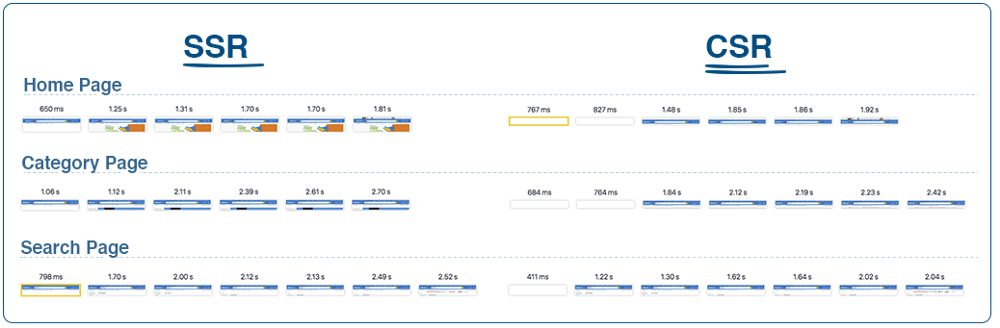
Como podéis ver en esta imagen de las pruebas realizadas por Walmart, en SSR el cliente empieza a ver el contenido mucho antes, a pesar de que el servidor tarde algunos ms más en responder:
Entonces, si a los SEOs nos complica la vida el CSR (ya que dependemos de la capacidad del buscador a la hora de ejecutar JS y renderiza) y para los usuarios es más rápido SSR, ¿por qué se utiliza CSR? Pues por el mismo motivo por el que IKEA vende los muebles sin montar: por costes.
El mayor beneficiado de utilizar CSR es el departamento de sistemas: al delegar la “construcción” de las páginas en los clientes (navegadores), los servidores necesitan utilizar mucha menos potencia. Si hacemos SSR, vamos a tener que hacer todo ese trabajo de pre-renderizado en el servidor, el cual puede ser muy costoso como ya hemos visto.
Comentábamos antes que la solución que Google ha propuesto si no queremos tener problemas, es utilizar Dynamic Rendering (es decir, SSR al menos para Googlebot), pero también ha especificado que en algunos casos ya siente capaz de rastrear e indexar webs creadas con CSR puro.
Específicamente, ha hablado de tres factores:
El tamaño de la web (en número de URLs)
La dinamización de la web (si publico mucho o poco, y si sus URLs cambian o son estáticas)
La compatibilidad con Chrome 41 Chrome 74
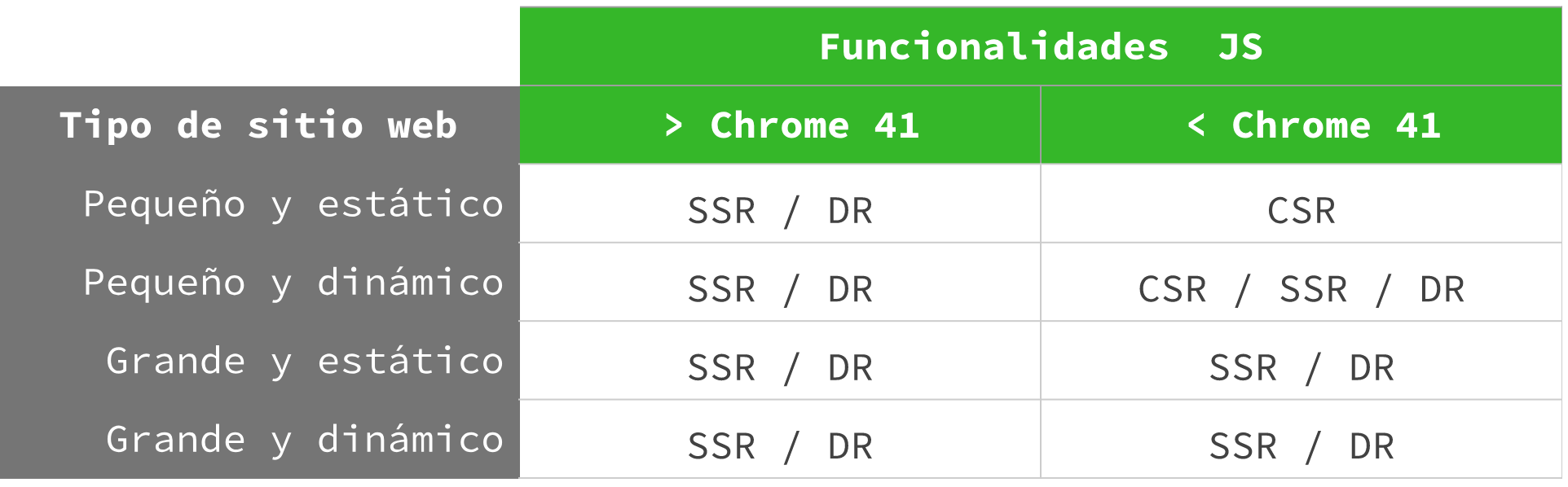
En función de eso, hemos montado esta tabla de lo que serían las recomendaciones de Google:
Cómo podéis ver, lo recomendado es utilizar siempre SSR (o Dynamic Rendering), excepto en sites pequeños y estáticos. Aún así, existe cierto riesgo incluso para este tipo de sites, así que lo ideal si vuestro proyecto depende del tráfico SEO es no jugársela y hacer un SSR / DR desde el principio.
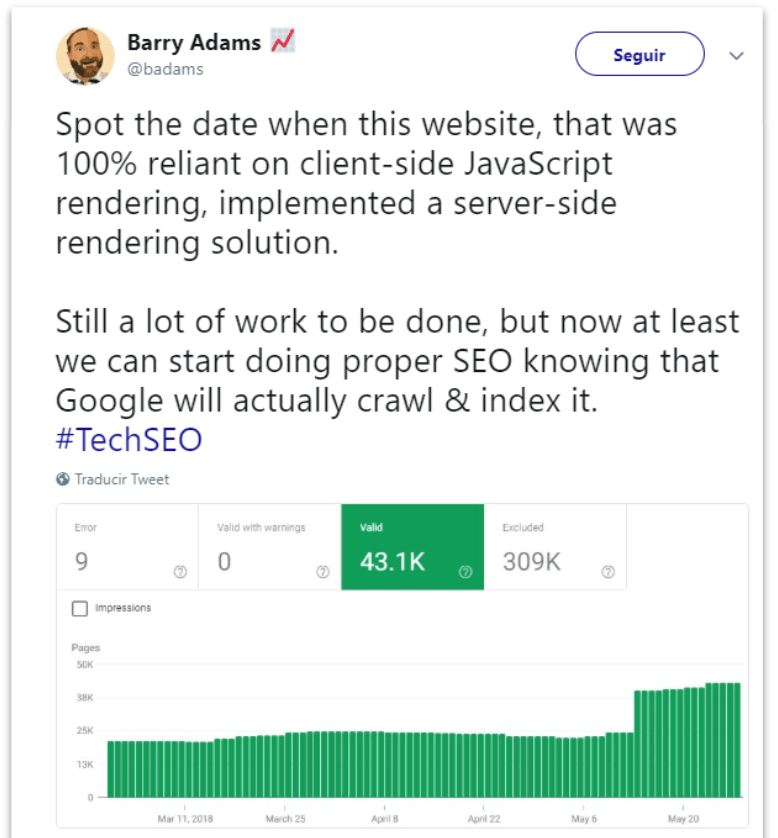
En él, muestra la gráfica de evolución de URLs indexadas de un site que estaba hecho en CSR puro y que eventualmente cambió a SSR. Al hacerlo, el número de páginas indexadas aumentó sustancialmente (casi al doble), reflejando el cuello de botella que supone JS para Google y el motivo por el cual no lo recomienda para sites grandes.
Buenas prácticas SEO para PWA y JavaScript
A continuación, vamos a mostrar herramientas para comprobar que Google no tienen problemas con nuestro sitio.
Auditoría de PWA y Performance
La podéis hacer combinando el plugin Lighthouse de Chrome (ya era hora que hicieran el plugin, porque hasta entonces era nativo en Chrome Canary) y Sonar Whal.
Con el plugin de Chrome Service Worker Detector, podéis revisar rápidamente el service worker y el manifest de una PWA.
Mobile-Friendly Test
A día de hoy, el Mobile-Friendly Test de Google es la mejor manera de ver la página renderizada, ya que es más tolerante que el Fetch & Render de Search Console. En SC suelen aparecer muchos timeouts y no es un representativo de la realidad al 100%. El Mobile Friendly Test tampoco lo es, pero es una idea más aproximada, el problema de ésta es que no podemos hacer scroll.
También podemos usar esta tool para ver el HTML después de renderizar y ver si existen diferencias en ambos HTML con Diff Checker. Otra de las cosas que podemos analizar son los errores JavaScript y los assets bloqueados.
Fetch and Render
No por ello menos útil, la herramienta de Google nos permite comparar qué vería un buscador y un usuario de una vez, lo cual es muy cómodo.
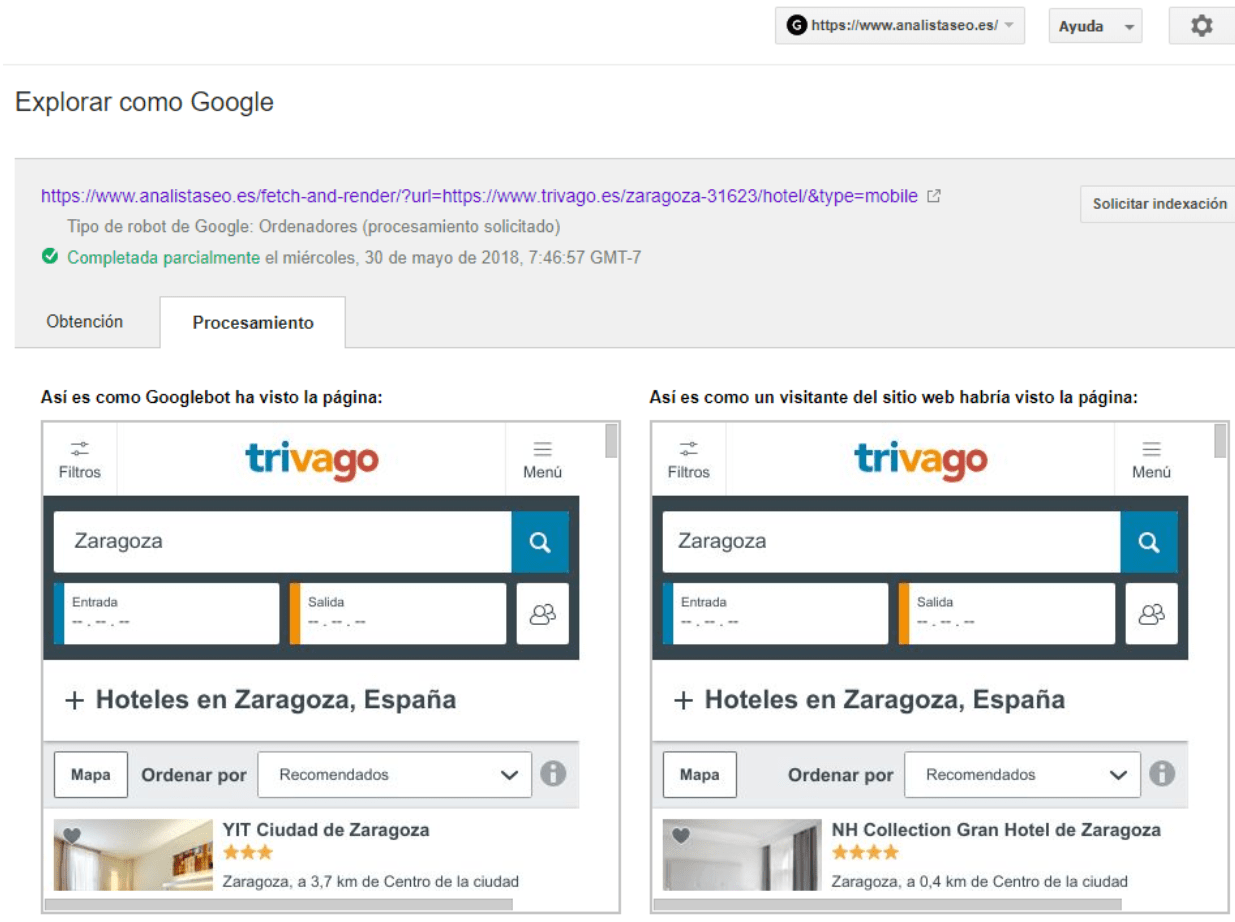
También podemos hacer Fetch and Render de cualquier dominio para ver cómo lo hace la competencia, aunque no lo tengamos en nuestro SC. Por ejemplo, podéis ver cómo desde mi propio SC estoy renderizando Trivago gracias al código que ha compartido la gente de ScreamingFrog (acordaros de modificarlo como compartí en las diapos o la podréis liar):
Lo que hace este código es añadir la url que quieras en un iframe de una página de tu dominio.
Existen otras herramientas como ScreamingFrog SEO Spider o esta herramienta online de Merkle SEO. Gracias a estas tools podéis modificar el tiempo de espera y los user agents. Lo que tenéis que intentar es que todo renderice por debajo de 5 segundos (ni mucho menos es un número de referencia, pero cuanto más rápido mejor).
Crawlea y compara staging con producción
Si estáis cambiando vuestra web a algún Framework JS como por ejemplo Angular, React, Polymer, Vue… con crawlers como FandangoSEO podéis crawlear vuestro sitio en staging y también en producción. La mayoría de problemas SEO en migraciones a Frameworks que hemos visto son porque se ha cambiado el layout y no porque se esté usando JavaScript.
Como en cualquier migración, hay que revisar que todas las URLs enlacen de la misma forma en pre y en pro, manteniendo los mismos niveles de profundidad. Así como que se mantenga el mismo contenido en ambas versiones. Esto es prioritario en cualquier migración, más aún que preocuparse porque las redirecciones sean dobles o simples. También es un error migrar plantilla, CMS y URLs a la vez, por mucho que mantengamos links y las redirecciones sean perfectas, son muchos cambios a procesar por Google y puede tardar en recuperarse tranquilamente de 6 a 12 meses como ha confirmado en más de una ocasión.
De ahí la necesidad de hacer cuantos menos cambios a la vez mejor y revisarlo todo concienzudamente en staging.
Crawlea simulando mobile y con render JS
Ahora, con la llegada de mobile first indexing, tenemos que comprobar cómo ve Google nuestra web en mobile y revisar los puntos arriba mencionados. Con FandangoSEO también podemos comparar crawls y ver si mobile vs desktop es lo más parecido posible.
Comprueba las metas con otros user-agent
Aunque esto se puede comprobar también con crawlers, para hacer una comprobación a mano de las páginas principales uso los plugins meta seo inspector combinado con user-agent switcher. A este último le añado los user agent de Googlebot, Googlebot Mobile y los de Facebook y Twitter (para ver las opengraph y twitter cards):
Esto se hace combinando de nuevo user-agent switcher, pero con el plugin Web Developer, donde se desactiva el JS para navegar.
Comprueba los errores de consola y los links en Chrome 41 74
Es imprescindible usar Chrome 41 74 para ver los errores de Javascript, de API o de CSS que da la consola del navegador. Veréis que hay errores que en el Chrome actual no aparecen, con lo cual, si están en la versión 41 74 son errores que Google podría tener para renderizar.
Otro elemento que tenemos que atender es si los links y menús son accesibles para Chrome 41 74, hay funciones modernas que tienen estos Frameworks que no permiten que lo sean. Aquí podéis ver qué funciones podéis usar y cuáles no.
Para acabar con las buenas prácticas, os compartimos una serie de checklist para tener en cuenta a revisar tanto si hacéis CSR, como Dynamic Rendering o con SSR o Hybrid Rendering.
PWA Checklist SEO para CSR
Canonicals + metadatos no dependen de CSR
La página renderiza en menos de 5 seg
La página carga y es funcional en Chrome 41
Los enlaces al renderizar aparecen como elementos
El HTML + visual es el esperado en Mobile Friendly Test
El HTML + visual es el esperado al “Obtener y procesar” en Search Console
Las páginas aparecen al buscar cadenas específicas de texto
El contenido no se replica en diferentes páginas
No se usa !# (sí el History API) y cada página con su url
PWA Checklist SEO para Dynamic Rendering (SSR)
Servimos SSR a Googlebot + bots específicos (FB, TW…)
El contenido que recibe Googlebot es el mismo que el de un navegador normal
Los códigos de respuesta son los mismos en ambos casos
El meta etiquetado es el mismo en ambos casos
El servidor es capaz de manejar el renderizado bajo alta carga
La versión SSR incluye todo el contenido y enlaces de forma correcta
Todas las páginas tienen el comportamiento esperado en ambos casos
No se usa !# (sí el History API) y cada página con su url
Además os compartimos este checklist sacado de la página de Google, de cosas a revisar para PWA a nivel de experiencia de usuario y WPO.
PWA Checklist UX & WPO
El sitio está en HTTPS
Las páginas son mobile friendly y funcionan en diversos navegadores
Las urls cargan de forma offline
Metadata para añadir a la pantalla de inicio
TTI <10s en 3G
Las transiciones son inmediatas
Verificar que se hace uso de cache-first
Informar cuando se hace uso de la versión offline
Comprobar que el contenido no «salta» al cargar (usa un skeleton)
Devolver al usuario a donde estaba al pulsar atrás
Que los inputs no se tapen cuando se despliega el teclado
El contenido es fácilmente compartible (Web Share API)
No ser intrusivo con el añadir a pantalla de inicio
Experimento PWA sin prerender a Google (CSR)
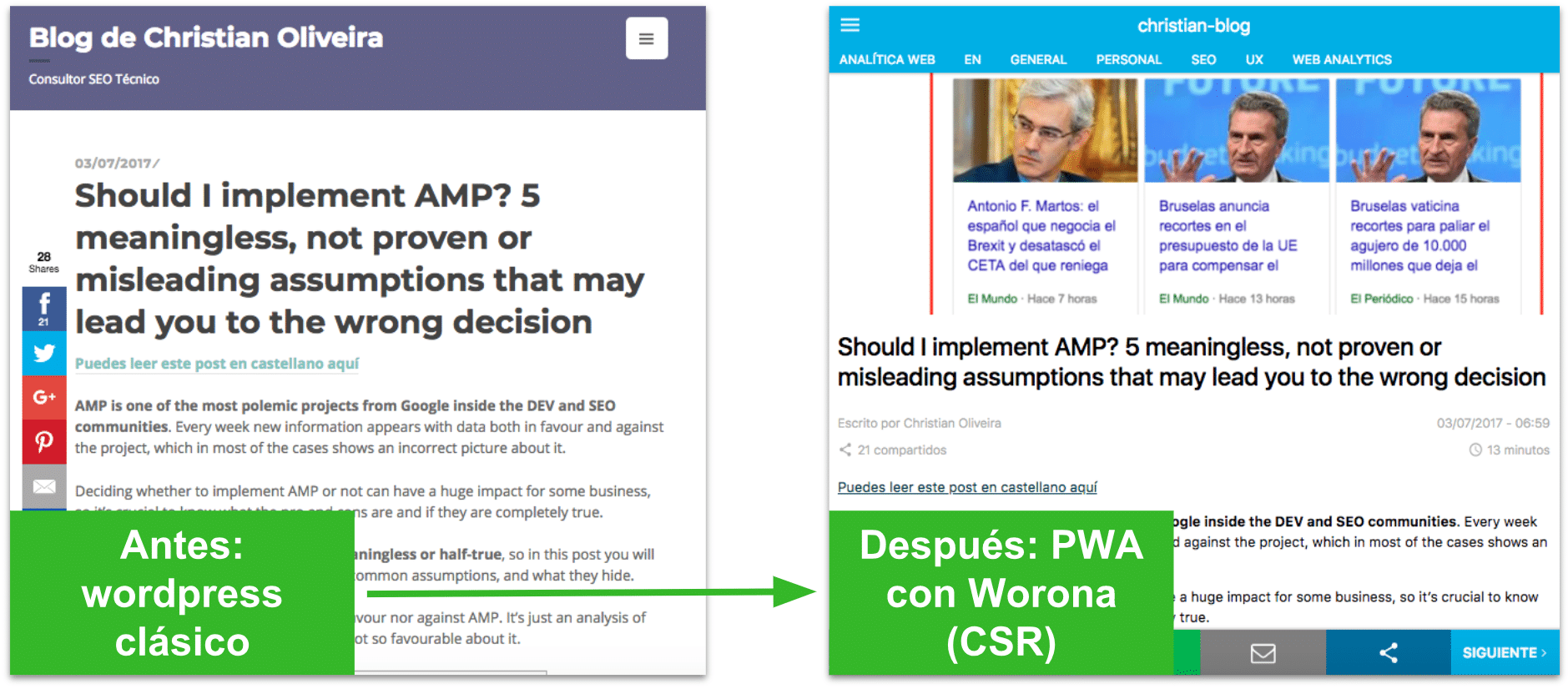
Para poder probar en nuestras propias carnes cómo trata Google el JavaScript, hemos sacrificado nuestros blogs migrándolos de un WordPress “normal” a una PWA que funciona únicamente con JS (CSR).
Lo hemos hecho con Worona (ahora Frontity), que es una plataforma para convertir un WordPress en una PWA para usuarios móviles. En nuestro caso, hemos colaborado con ellos para hacer que la PWA se cargase tanto en mobile como en desktop modificando el código, y que cuando no tenemos JS activo se reciba una página en blanco, simulando así el CSR. Hicimos esto porque nuestros blogs todavía no están en mobile first indexing, y queríamos que la versión desktop fuera PWA también.
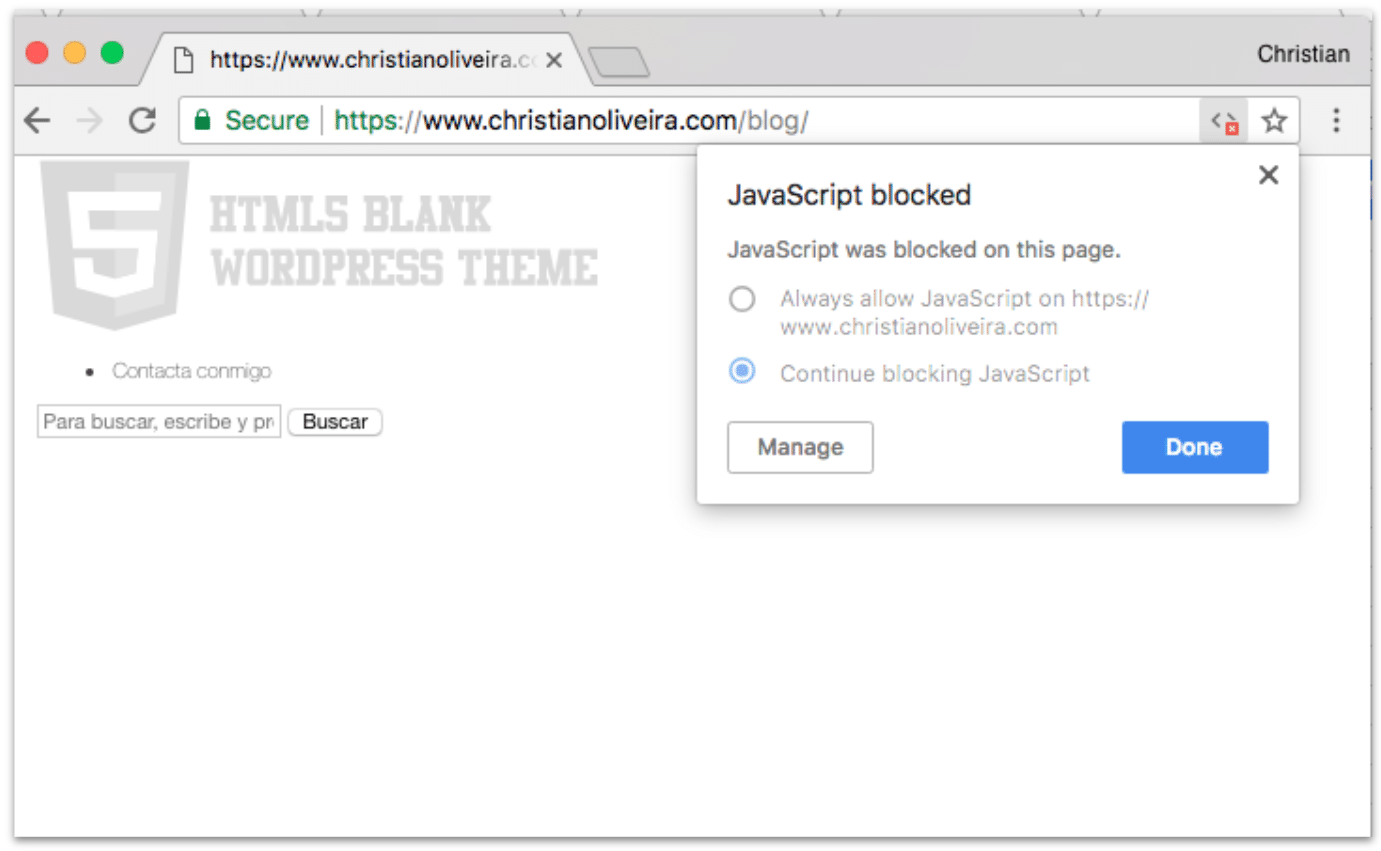
Como podéis ver si desactivamos JS todas las páginas del blog cargan únicamente esto que veis aquí: una página prácticamente en blanco, sin contenido ni enlaces para rastrear:
Una vez puesta la PWA en producción, hemos hecho diferentes pruebas. ¡Ojo! Como vais a ver, las pruebas han sido hechas en un blog pequeño, en un espacio corto de tiempo y a pequeña escala. No podemos garantizar que los resultados del propio experimento se vayan a mantenerse o a replicarse en otras situaciones.
Prueba 1: renderizado
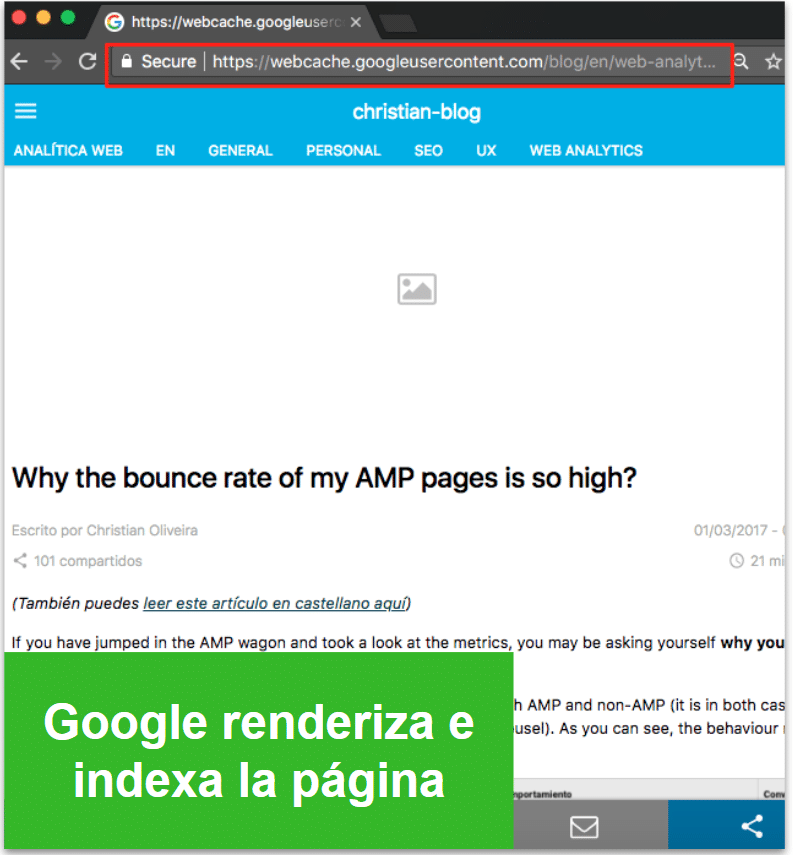
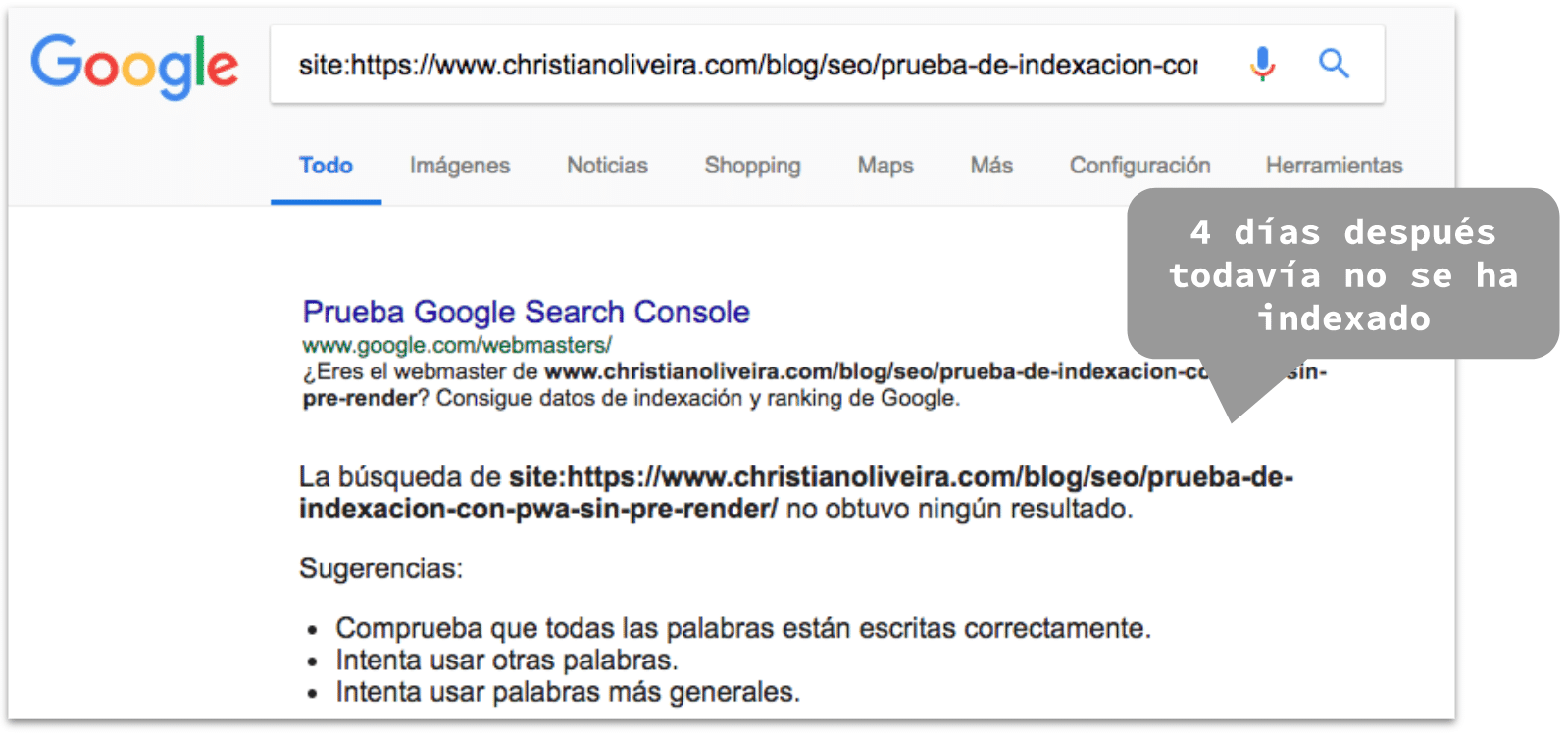
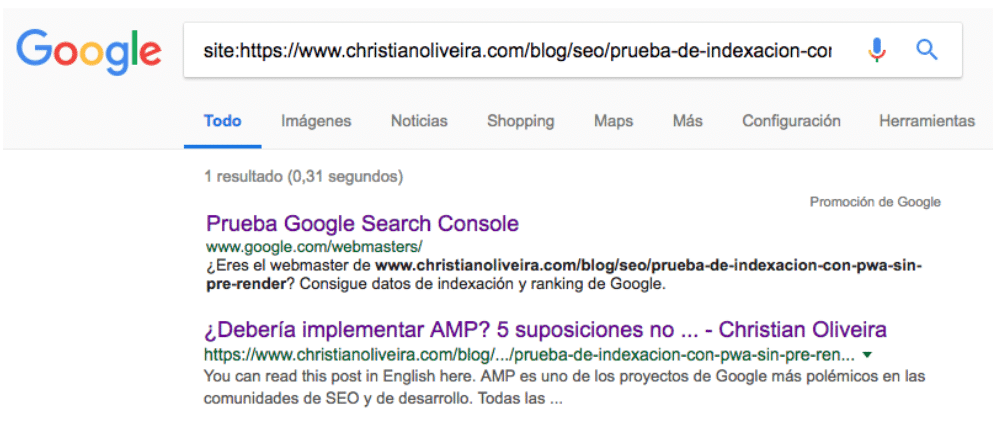
La primera prueba era comprobar si Google era, efectivamente, capaz de renderizar e indexar las URLs del blog, que sólo funcionan con JavaScript. Para ello, comprobamos primero en la Mobile-Friendly Test Tool y en el Fetch and Render de Search Console, donde podemos ver que el contenido aparece. Utilizamos la opción de “Solicitar indexación” para forzar a Google a actualizar esa URL en su índice, y en menos de 15 minutos podemos comprobar que lo ha hecho:
Observaciones:
Google ha sido capaz de renderizar e indexar el contenido
El proceso ha sido relativamente rápido (15’)
Prueba 2: rankings
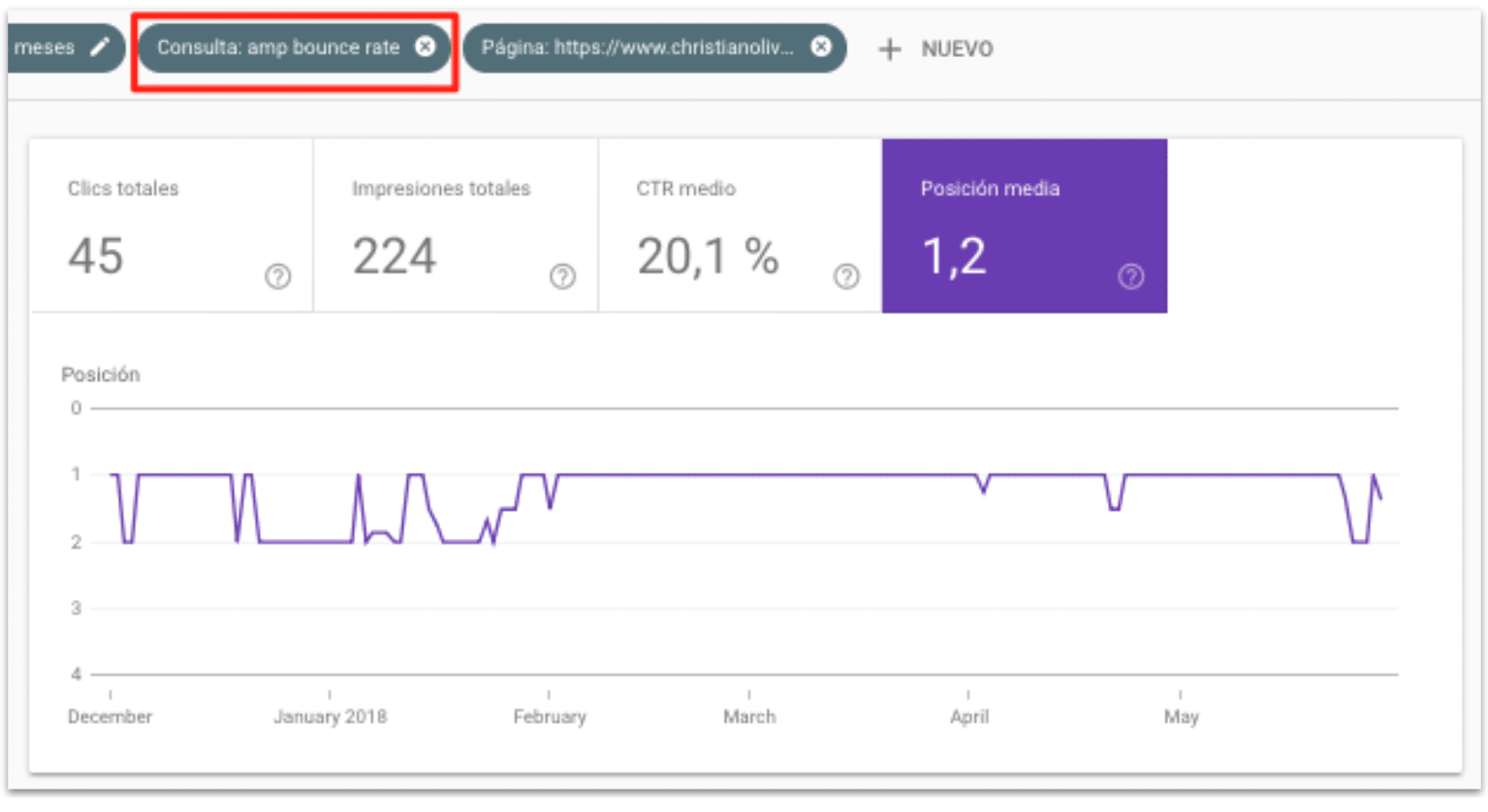
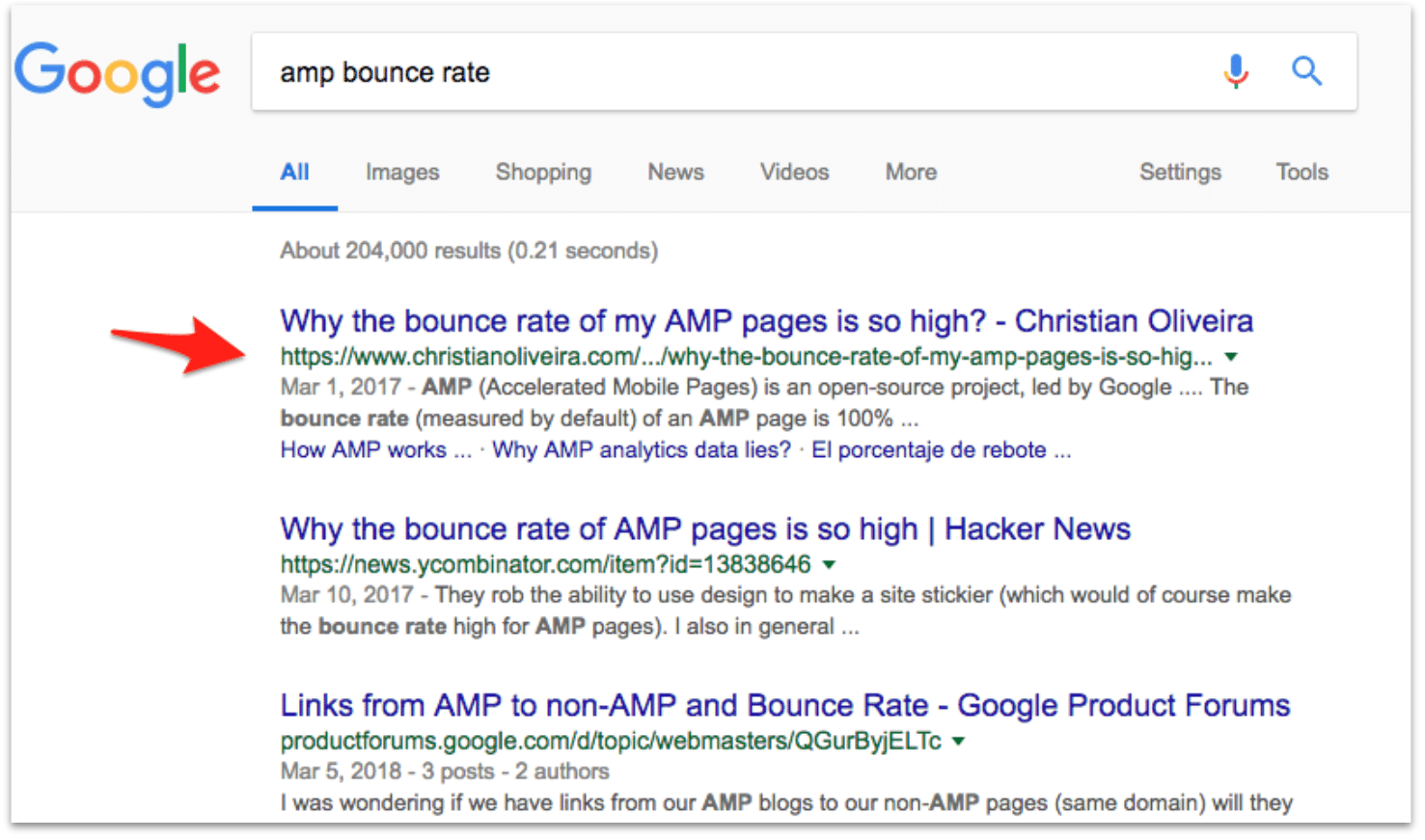
Una vez que sabemos que Google es capaz de renderizar el JS y ver nuestro contenido, la siguiente pregunta obvia es de si nos mantiene los rankings para ese post. Para ello, elegimos una keyword para la que el post lleva 6 meses posicionando entre posiciones 1 y 2:
Y comprobamos que una vez ha actualizado esta página en su índice, seguimos manteniendo la misma posición para esta búsqueda:
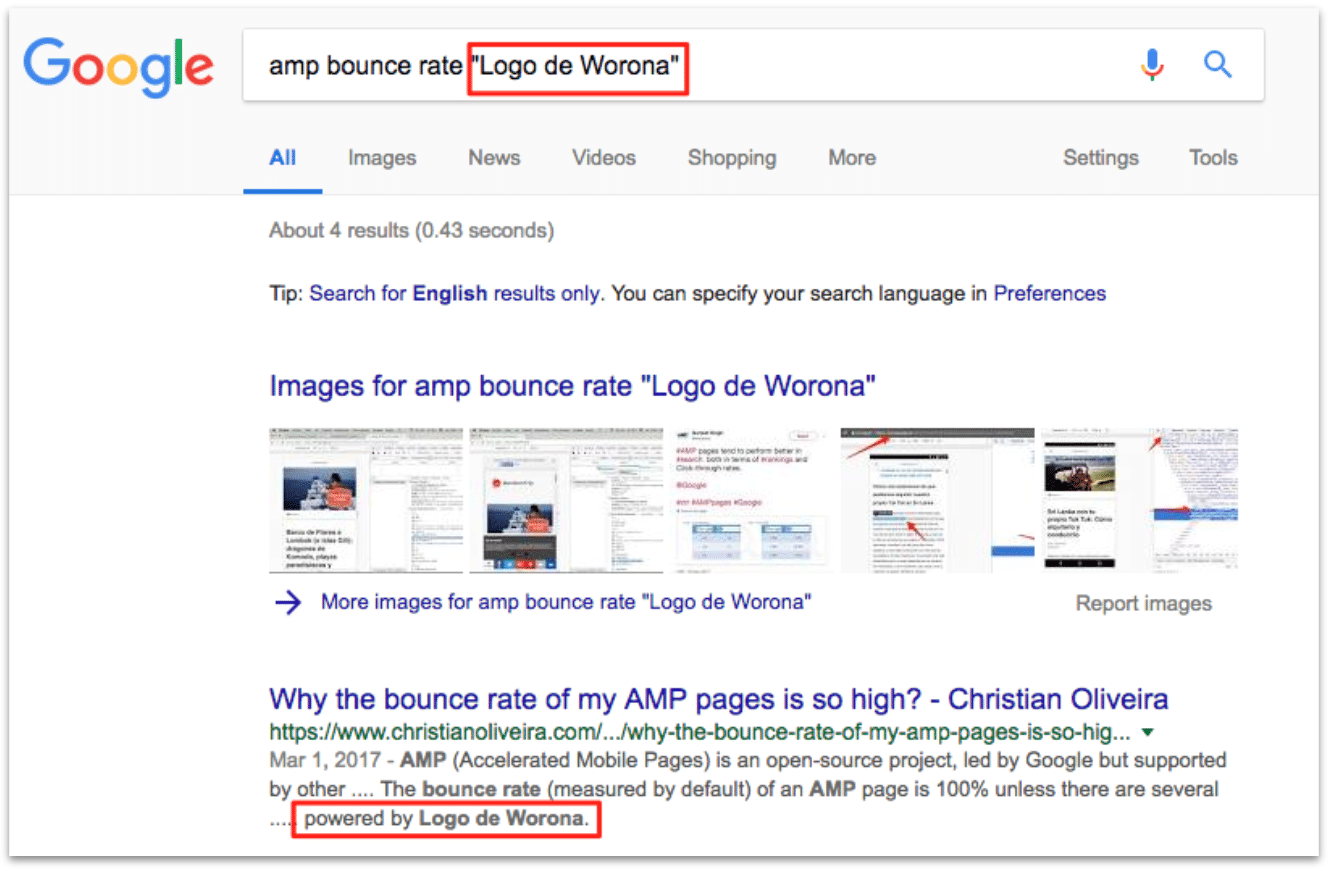
Además, hacemos una búsqueda extra combinando la keyword con un trozo de texto que aparece en la PWA y no aparecía en la versión anterior del blog, para asegurarnos de que Google está utilizando la versión PWA de la página:
Observaciones:
No se han perdido los rankings por tener el contenido en una PWA sin renderizar.
Prueba 3: nuevo contenido
Para comprobar cuánto tarda Google en detectar, rastrear e indexar un post nuevo, publicamos uno:
Como no queremos forzar que lo rastree, lo que hacemos es un Fetch and render de la home del blog y solicitamos la indexación de la misma, en la que está presente un enlace a este nuevo post, para ver si Google lo indexa.
A pesar de que aparecía una visita de Googlebot a la URL en los logs, la página no apareció en el índice de Google hasta 5 días después:
Un pequeño error al hacer esta prueba es que el post no tenía apenas contenido, y el plugin utilizado (Worona) al hacer scroll pasa al siguiente post, así que Google al renderizar está recibiendo el contenido de otro post bajo esta URL:
Observaciones:
Si no forzamos el renderizado y la indexación de ese contenido, Google tardará más en indexar el nuevo contenido.
Prueba 4: las dos olas de indexación
Por último, queríamos demostrar el sistema de dos olas de indexación que Google ha confirmado. Al igual que en el caso anterior, al hacer la prueba con una URL que tenía muy poco contenido, Google ha terminado cargando el siguiente post que sale al hacer scroll e indexando contenido de otro post asociado a esta URL.
Lo que hicimos fue lo siguiente:
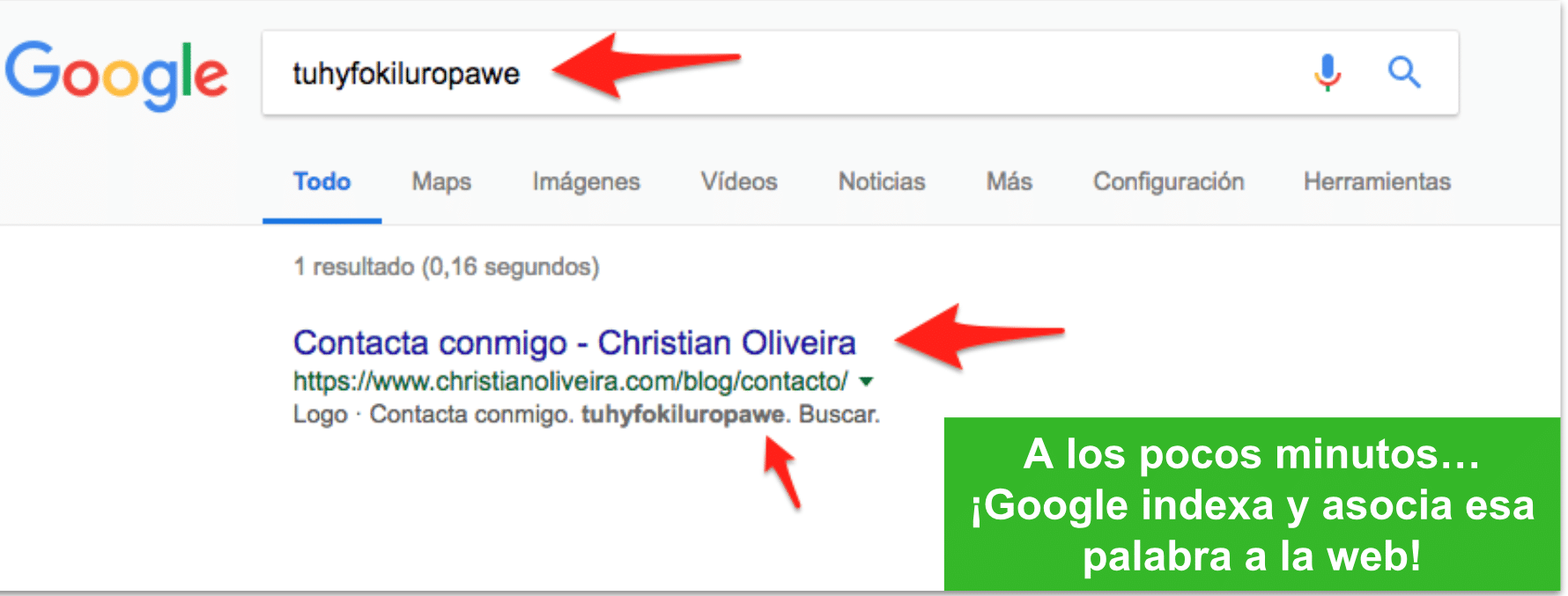
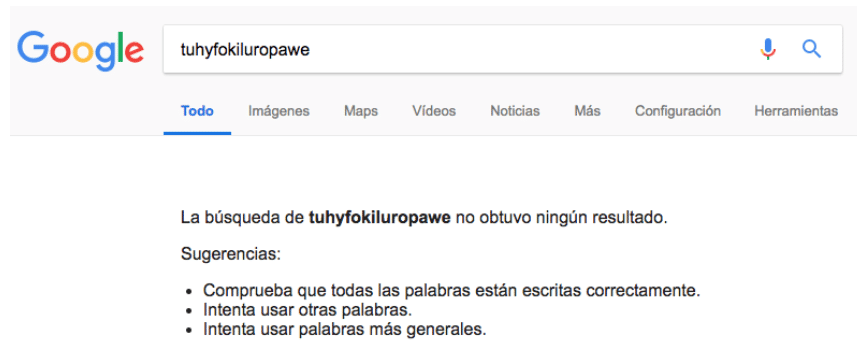
En una página que Google todavía no había indexado desde la migración a la PWA, hicimos un cambio para incluir una palabra inventada únicamente en el HTML inicial que se envía, que desaparece al cargar el JS
Forzamos a Google a pasar por esa página haciendo únicamente Fetch (no el Render) en Search Console y solicitando su indexación
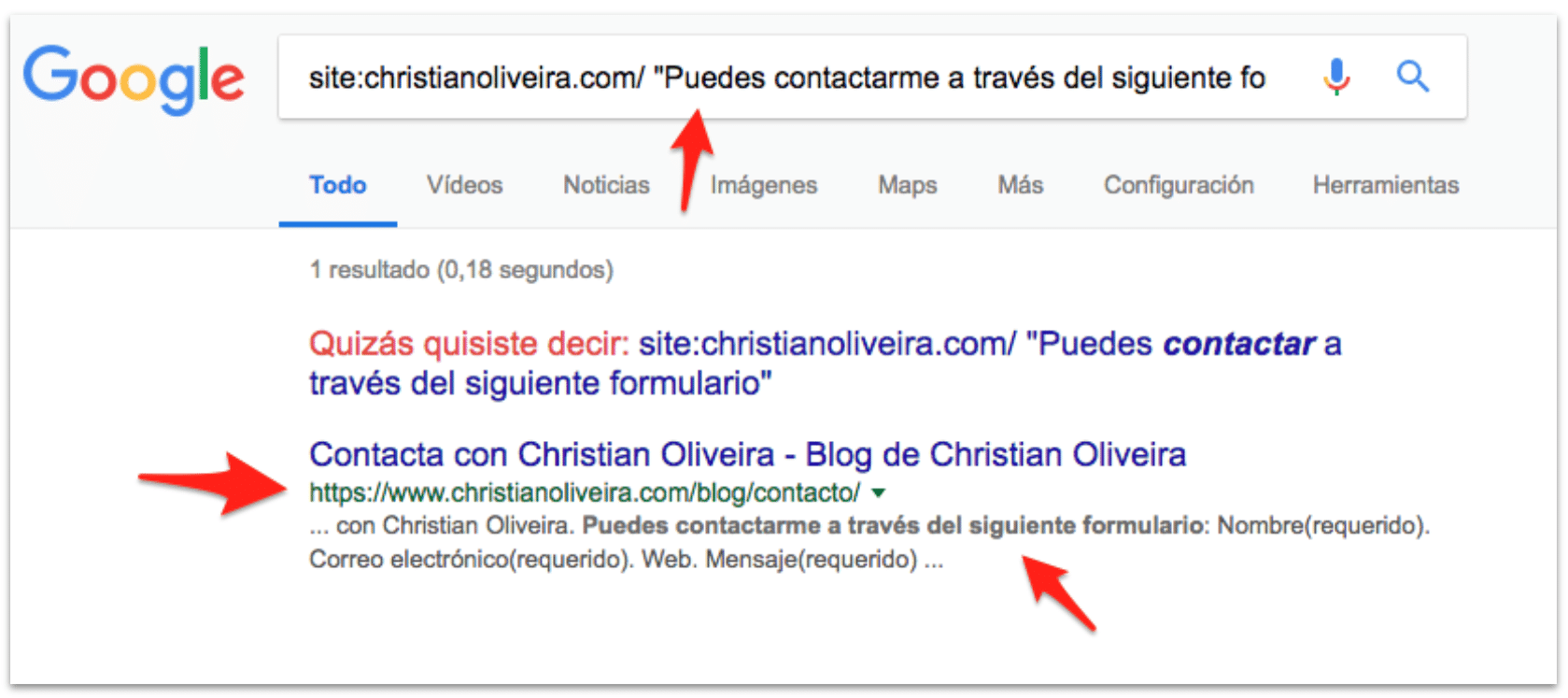
A los pocos minutos, al buscar la palabra ya podemos ver que Google la ha visto, indexado y que la página aparece:
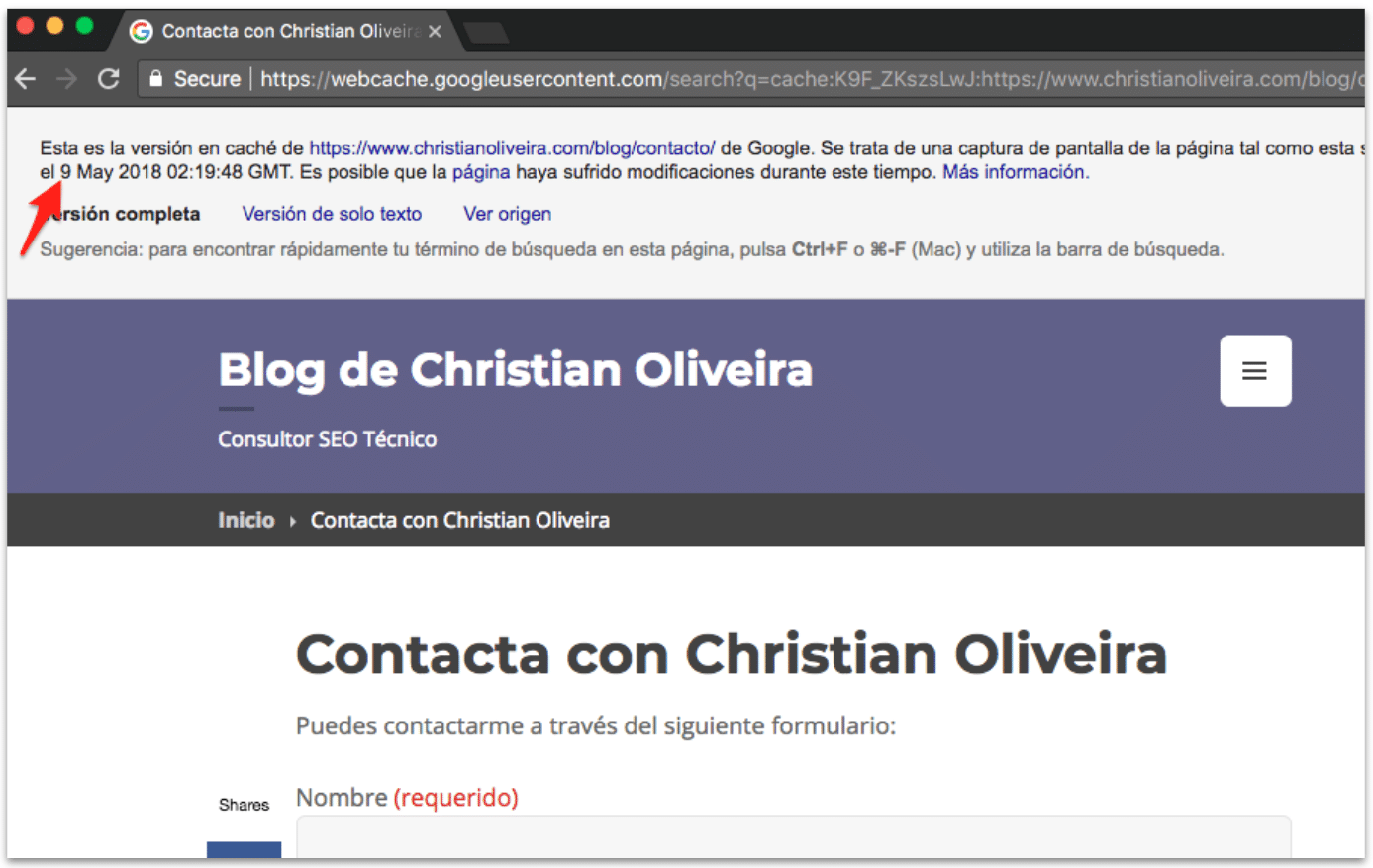
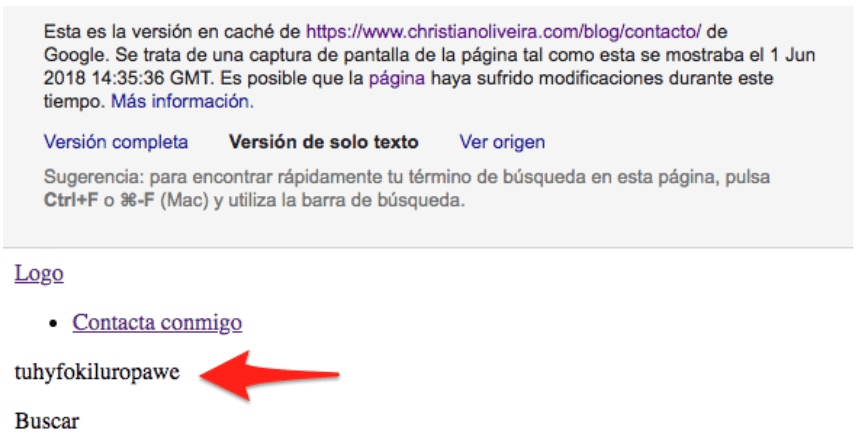
Por otro lado, si nos vamos a ver la cache de la página en Google, nos encontramos que a pesar de que ya ha indexado el nuevo contenido (el nuevo HTML vacío con nuestra palabra inventada) en caché todavía tiene la versión antigua de la página:
Además, si buscamos trozos de texto que aparecían en la versión antigua de la página pero no en la nueva, la página sigue apareciendo:
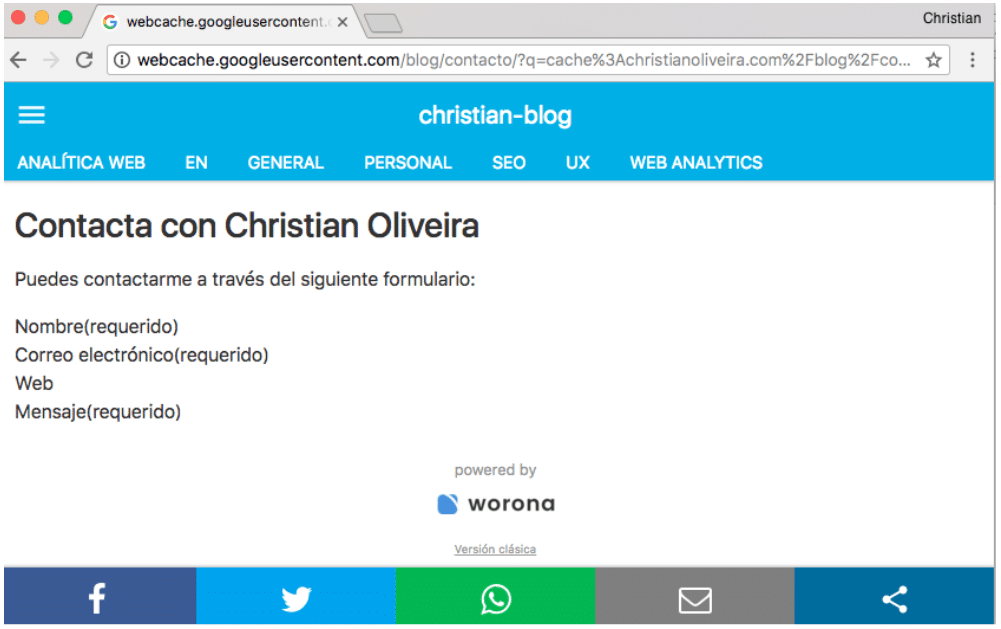
Unos días después, Google muestra ya la cache actualizada con la versión PWA:
Y, a partir de este momento, la página ya no aparece para la palabra que hemos inventado y que sólo aparece en el HTML sin renderizar. Con lo cual parece que Google no se ha comido el cloaking después de haber renderizado la página:
A pesar de que si comprobamos la versión sólo texto o el origen en la caché de Google, sí la tiene indexada. Con esto demostramos a su vez lo que ya sabemos todos, que la versión de texto sólo muestra el raw HTML, lo cual no es el indicador que debemos mirar en CSR para ver si Google tiene un contenido:
Observaciones:
Antes de renderizar la página Google ha indexado el contenido que hay sin JS (primera ola).
Este contenido lo ha asociado a la versión anterior de la web (sin PWA).
Una vez que ha renderizado, únicamente aparecemos para el contenido que aparece en la versión final de la página renderizada, ignorando el contenido que aparecía inicialmente en el HTML pero que no aparece luego al ejecutar el JS (segunda ola).
Conclusiones
A día de hoy muy pocas webs han migrado directamente a PWA sin prerender (CSR) para todos los agentes. Los que lo han hecho y han bajado, tenían además otros problemas técnicos (un ejemplo muy conocido es el de hulu.com).
Las webs nuevas que han salido directamente con PWA sin prerender no tienen problemas para rankear, pero sí de indexación. Esto lo hemos visto en casos de gente que se ha cedido a que analicemos y con los experimentos que hemos hecho. También muy contundente la imagen del tweet de Barry Adams que hemos mencionado del paso de indexación en Google de CSR a SSR.
Para Google, el Dynamic Rendering es una solución que funciona y que hemos podido comprobar en proyectos de clientes y sin problemas de ningún tipo, siempre y cuando se haga bien.
Siempre digo que es mejor remar a favor que ir en contra de los algoritmos de los buscadores y este post es un ejemplo de ello. En él os voy a enseñar el concepto de «frecuencia de rastreo» y lo vital que es su optimización (sobre todo en sitios de gran tamaño) para mejorar el tráfico […]
Antes de empezar un proyecto SEO es importante conocer la tecnología en la que está desarrollado un sitio web. ¿Es SalesForce? ¿Cuándo cambiaron de CMS? ¿Es un portal hecho a medida? ¿Está usando un Framework Javascript? ¿Qué sistemas de caché usa? ¿Tiene Cloudflare o similares para poder usar los workers y resolver las limitaciones de […]